 Figure 1 : Recherche d'une regexe avec
Textpad
Figure 1 : Recherche d'une regexe avec
Textpad
Sous-sections :
Les expressions régulières (ou "expressions rationnelles", en anglais "regular expression" ou "regexes", "regexp", etc.) permettent de manipuler (recherche et remplacement) du texte en utilisant des caractères spéciaux, qui valent pour une classe de cas et non littéralement. Perl en offre le meilleur support, mais des éditeurs de textes courants permettent également de les utiliser.
Les regexes ne sont cependant pas un langage : elles ne peuvent pas faire de boucle, ou agir de façon conditionnelle. Le pattern est générique mais statique. Elles sont surtout utiles dans des cas prévisibles et normalisés : paragraphe, ponctuation, encodage...
Il existe de nombreuses excellentes introductions aux expressions régulières et des documentations dans les logiciels qui les implémentent, dont une sélection est proposée ci-dessous ; on se limite ici à des introductions puis à des exemples avec trois environnements : Emacs (Windows / Linux), Textpad (Windows), et Perl. La syntaxe des expressions régulières peut varier très légèrement d'un éditeur ou d'un programme à l'autre, mais les fonctions restent les mêmes. Word n'est pas un éditeur de texte mais implémente un sous-ensemble des expressions régulières. Les exemples ci-dessous sont dans la syntaxe de Perl, ils sont traduits à la fin de cette partie dans les idiomes légèrement différents des autres outils présentés.
*.doc.
* ci-dessus exprime ici "toute
chaîne de n'importe quelle longueur", non un astérisque)
\*.
\\.
Abc
recherche littéralement la chaîne "Abc".
[aeiouy] = "un caractère parmi
les 6 caractères a e i o u ou y". a vaut
bien toujours littéralement pour "a", mais dans une
classe constituée également d'autres éléments en
relation d'alternative. [aeiouy]b
trouvera donc "ab", "ib", mais pas "cb". Pour éviter
des listes de caractères trop longues, on peut
utiliser un tiret : [a-z] = tout
caractères entre "a" et "z" (tout alphabétique
minuscule), [0-9] tout numérique,
[A-Za-z0-9] tout alphanumérique. Ces
listes sont cumulables : [0-35-9]
recherche tout numérique sauf "4".
[aeiouy]+
signifie "une ou plusieurs voyelles de suite",
[aeiouy]* zéro ou plusieurs,
[aeiouy]? zéro ou une ;
[aeiouy]{5} signifie "exactement 5
voyelles de suite". Ainsi [aeiouy]+c peut
correspondre à "aiec", "ac", mais pas à "adc".
[^aeiouy]+ signifie "un ou plusieurs
caractères de suite qui n'est pas a e i o u ou
y". [ae]$ signifie un a ou un e
(minuscule) en fin de paragraphe (juste avant un
retour chariot).
1. Recherche littérale - Les expressions
régulières permettent de rechercher des caractères
littéralement : les caractères sont désignés par le symbole
correspondant, a recherche le caractère "a",
etc. Des caractères "non visibles" comme le retour chariot, la
tabulation, etc. peuvent être désignés littéralement par un
caractère spécial : \n pour le retour chariot et
\t pour la tabulation. L'anti-slash forme un seul
symbole avec le caractère qui suit, qui ne vaut plus
littéralement pour un "n" ou un "t". L'anti-slash lui-même
n'est pas l'équivalent littéral du caractère "\". Pour
désigner un anti-slash littéralement, il faut le faire
précéder lui même d'un anti-slash : \\ recherche
"\". Les "méta-caractères" de cette sorte sont généralement
\, ., *,
?, +, ^,
$, {, |,
(, ), et }, dont on
voit ci-dessous le sens spécial ; pour les utiliser
littéralement il faut donc utiliser \\,
\., \*, \?,
\+, \^, \$,
\{, \|, \(, et
\). L'anti-slash permet d'interpréter un
méta-caractère comme un caractère littéral, mais également de
donner un sens spécial à des caractères littéraux, comme
\n ou \t.
2. Classes d'éléments - Les expressions
régulières permettent également de ne pas faire correspondre
les élément un à un, mais de faire correspondre une liste de
possibilités à un élément. a/ Une
classe de caractères en alternative est désignée entre
crochets : [aeiouy] recherche une occurrence
d'une voyelle : elle trouvera deux éléments dans
"soir". - Pour ne pas écrire de longue suite de
caractères, on peut spécifier des plages avec le tiret :
[0-9] recherche tout caractère numérique,
[a-z] toute lettre en minuscule,
[A-Za-z0-9] recherche tout caractère
alphanumérique. Il faut noter que les plages de caractères
sont basées sur l'ASCII, il faut donc ajouter les caractères
qui n'en font pas partie, comme les caractères accentués :
[a-zéèàùâêîôûäëïöüçA-ZÉÈÀÙÂÊÎÔÛÄËÏÖÜÇ0-9] pour
être (presque) exhaustif. Mais, par chance, on peut alors
utiliser le point . qui vaut pour tout élément
sauf le retour chariot (\n). [aeiouy]. trouvera
"az", "aa", "a!" mais pas "a" ni "ba". Pour mettre un
tiret littéralement parmi les éléments en alternative, il faut
le mettre en premier dans la liste : [-,;]
recherche un tiret, une virgule ou un point virgule (pour "]"
utiliser l'antislash : [-\]]). - Les
méta-caractères perdent leur sens particulier dans une
expression entre crochets. b/ Des
symboles spéciaux permettent de désigner les classes les plus
souvent utilisées, par exemple en Perl \w =
word, tout caractère de mot (alphanumériques plus '_'),
\d = digit ([0-9]), \s tout
caractère blanc (= [ \t\n\r\f], soit espace,
tabulation, saut de ligne, retour chariot, saut de page) ;
lesquels peuvent être inversés \W = tout
caractère non-mot, \D = tout non numérique,
\S tout caractère autre que blanc, etc. (cf la
page de manuel Perl : http://www.Perldoc.com/Perl5.8.0/pod/Perlre.html#Regular-Expressions)
- Autres familles de classes, du type :
[:alnum:] par exemple pour tout
alphanumérique ([A-Za-z0-9])
c/ L'alternative entre des éléments de
plusieurs caractères est exprimée par |, et
s'applique aux éléments entre parenthèses :
(oui|non) permet de rechercher "oui" ou
"non". Avec les crochets, le contenu est évalué comme une
liste de caractères, ainsi l'alternative | est
inutile : [truc|tric] = [truci]
- le caractère ^ en début de plage permet
d'indiquer une assertion négative : [^a-z]
recherche tout ce qui n'est pas un alphabétique minuscule.
3. Quantifieurs - Possibilité de préciser le
nombre d'occurrences d'un élément (un caractère littéral, ou
une classe d'éléments en alternative, ou une chaîne de
caractères entre parenthèses). Les principaux quantificateurs
sont ? (0 ou 1 fois), + (1 ou
plusieurs fois), * (0 ou plusieurs fois). On peut
également spécifier une plage d'occurrence :
[aeiouy]{3,5} désigne toute suite de entre 3 et 5
voyelles. Si le second caractère n'est pas spécifié, il vaut
pour l'infini : [0-9]{5,} recherche au moins 5
numériques de suite. On voit que ? =
{0,1}, + = {1,} et
* = {0,}. Une valeur seule entre
accolades exige une valeur exacte : a{5}
recherche exactement 5 "a" de suite. Les quantificateurs s'appliquent à la dernière unité
syntaxique les précédents. non{5} trouvera
"nonnnnn" mais non pas "nonnonnonnonnon" pour cela il faut
écrire (non){5} Note : Les expressions rationnelles sont
par défaut avides : dans "abbb", ab+ trouvera
"abbb" et non "ab". Si on veut éviter ce comportement, on peut
utiliser la négation : <[^>]+> par exemple
pour ne pas prendre le début d'une balise et la fin de la
dernière balise sur la même ligne. Avec Perl, on peut
également préciser au quantificateur de chercher la séquence
minimale en ajoutant "?" : +?, *? et
{1,5}? cherche donc la première
correspondance. D'autre part une expression rationnelle
cherche l'expression dès que possible, et s'arrête dès que les
conditions sont satisfaites même si une correspondance plus
loin serait plus complète. Aussi y* trouve un
motif vrai dès le premier caractère de "xyz", puisqu'il peut
correspondre à une chaîne nulle.
4. Référence - Les parenthèses permettent de
hiérarchiser les membres d'une alternative (cf. 2), et de
regrouper une chaîne de caractères en un élément (cf. 3), mais
servent également à mettre en mémoire le résultat. Ce qui
permet par la suite de faire référence au contenu d'une
expression entre parenthèses à l'aide de \1 (pour
désigner le contenu d'une première parenthèse dans
l'expression de recherche), \2 (pour désigner le
contenu d'une seconde), etc. Ainsi ([^ ]+)
\1 recherche un mot répété : un blanc, toute suite d'au
moins un caractère qui n'est pas un blanc, un blanc, et la
même suite de caractères. Les références de cette sorte sont
également utiles pour remplacer : faire référence dans
l'expression de remplacement au contenu trouvé dans
l'expression de recherche : remplacer
([0-9]+)([a-zA-Z]+) par \1 \2 permet
par exemple d'ajouter un espace entre une suite de numériques
et une suite d'alphabétiques. Remplacer
([a-z])([;:\?!]) par \1 \2 ; permet
d'ajouter un espace entre la fin d'un mot et les signes de
ponctuation qui demandent cet espace. (anti-slash avant le
? pour lui faire rechercher le caractère "?",
puisque c'est un caractère réservé).
5. Assertion - De nombreuses expressions
permettent d'inclure des assertions, qui ne correspondent pas
à un élément à rechercher mais indiquent par exemple que
l'expression commence en début de ligne (^) ou en
fin de ligne ($), etc. Ces assertions sont la
partie la plus variable des expressions régulières entre les
différents logiciels, il faut se reporter à la documentation
correspondante.
Les exemples sont notés m/expression de
recherche/ (m = match) et s/expression de
recherche/expression de remplacement/ (s = substitute),
dans la syntaxe de Perl. Une traduction ci-dessous montre les
expressions équivalentes dans les implémentations de Emacs et
Texpad.
Supprimer des espaces
s/ +/ / Remplacer plusieurs espaces par un
seul.
s/ +/ /g Le modificateur "g" (pour global)
permet de faire tous les remplacements d'espaces multiples, et
non seulement la première occurrence.
s/[ \t]+/ /g; Supprimer toute combinaison
d'espaces et tabulations.
Ebarber des lignes (enlever les espaces en début et en fin de ligne)
s/ +$//gm; Supprimer un espace en fin de
ligne. Le modificateur 'm' est nécessaire pour traiter la
chaîne comme "multiligne", et pour que '$' corresponde à
chaque fin de ligne et non à la fin de la chaîne entière.
s/[ \t]+$//gm Supprimer toute combinaison
d'espace et tabulation en fin de ligne
s/(^[ \t]+)|([ \t]+$)//gm; Supprimer toute
combinaison d'espace et tabulation en début ou en fin de ligne
Supprimer les sauts de ligne
s/\n{2,}/\n/g; Remplace les sauts de lignes
multiples par un seul saut de ligne.
s/([ \t]*\n){2,}/\n/g Plus rigoureux : supprime
les lignes vides ou ne contenant qu'une combinaison de blancs
et de tabulations.
Ajouter un tag paragraphe
s/^(.+)$/<p>\1<\/p>/gm; pour ajouter un tag
<p> ouvrant et fermant à chaque paragraphe. Ce qui est
contenu entre chaque début et chaque fin de ligne est mis de
côté avec "(.+)". On y fait référence dans l'expression de
remplacement avec \1, en l'encadrant de la balise ouvrante et
fermante. L'antislash avant "/p" est nécessaire à
l'interpréteur pour ne pas confondre ce slash littéral avec le
slash de fin de la syntaxe s///;
s/^([^<])(.+)$/<p>\1\2<\/p>/gm; si on
veut éviter d'ajouter ce tag aux lignes commençant déjà par
une balise (par exemple, on a des balises <div> ou
<head> qu'il ne faut pas encadrer d'un <p>). On
recherche une ligne qui ne commence pas par un chevron ouvrant
: "[^<]". Le résultat est mis de côté (avec des
parenthèses) pour être recollé dans le remplacement.
s/^([ \t]+)?([^<
\t])(.+)$/\1<p>\2\3<\/p>\n/gm; Si les lignes ont
été indentées, il faut prévoir d'éventuels blancs en début de
ligne et ajouter "([ \t]+)?".
Renommer un tag
s/<(\/?)nom_du_tag(.*?)>/<\1nouveau_nom\2>/g;
Pour renommer toutes les occurrences d'une balise, on veut
sauvegarder les éventuels attributs et l'éventuel slash de
fermeture. L'éventuel slash de fermeture ("\/?") est reporté
avec \1 ; (.*?) permet de faire une recherche "non gourmande"
: on prend tout ce qui précède le premier ">"
rencontré. "<nom_du_tag(.*)>" seul ne marcherait pas s'il y
a plusieurs balises sur la ligne : le ">" final pourra aller
chercher la fin d'une autre balise si la ligne en contient.
Rechercher le contenu d'un tag
m/<([^\s]+)\s+[^>]*?rend=(["'])italics\2[^>]*?>((.*?|\s*?)*?)<\/\1>/g
On recherche toute section encadrée par des balises où il y a
un attribut "rend" avec la valeur "italics". On cherche une
balise ouvrante ("<"), on isole et mémorise le nom du tag
en cherchant les premiers caractères jusqu'à un espace
("([^\s]+)" (il peut y avoir même un saut de ligne entre le
nom du tag et ses attributs), et on fait référence au même nom
grâce à "\1" à la fin de l'expression (précédé du slash de
fermeture : "\/"). On prévoit après le nom des blancs (\s+),
éventuellement d'autres attributs ("[ >]*?") avant
"rend=(["'])italics\2". On prévoit avec ['"] que la valeur de
l'attribut peut être marquée entre apostrophes ou guillemets,
mais la fermeture doit correspondre à l'ouverture
("\2"). Après l'attribut "rend" on prévoit encore d'autres
éventuels attributs ([^>]*). Enfin on prévoit entre le tag
d'ouverture et de fermeture toute combinaison, la moins longue
possible ("*?"), de caractères et de sauts de ligne
("(.*?|\n*?)")
Note : si plusieurs balises de même nom sont enchaînées, par exemple <seg rend="italic"><seg></seg></seg>, l'expression sélectionnera <seg rend="italic"><seg></seg> et non <seg rend="italic"><seg></seg></seg>. On voit ici la limite des expressions régulières et la nécessité d'utiliser un analyseur syntaxique dès qu'on ne manipule plus le texte mais la logique XML.
Les éléments qui varient le plus entre logiciels sont régulièrement :
Correspondance des exemples proposés
EN COURS
Perl Textpads/ +/ / Rechercher : + ; Remplacer
s/ +/ /gid., utiliser la toucher "remplacer tout"
s/[ \t]+/ /g;Rechercher : [ \t]+ ; Remplacer
s/ +$//gRechercher : +$ ; Remplacers/[ \t]+$//gRechercher : [ \t]+$ ; Remplacers/(^[ \t]+)|([ \t]+$)//gm;Rechercher : \(^[ \t]+\)\|\([ \t]+$\) ; Remplacers/\n{2,}/\n/g;Rechercher : s/([ \t]*\n){2,}/\n/gRechercher : s/^(.+)$/<p>\1<\/p>/gm;Rechercher : ^\(.+\)$ ; Remplacer<p>\1<\/p>
s/^([^<])(.+)$/<p>\1\2<\/p>/gm;Rechercher : ^\([^<]\)\(.+\)$ ; Remplacer<p>\1<\/p>
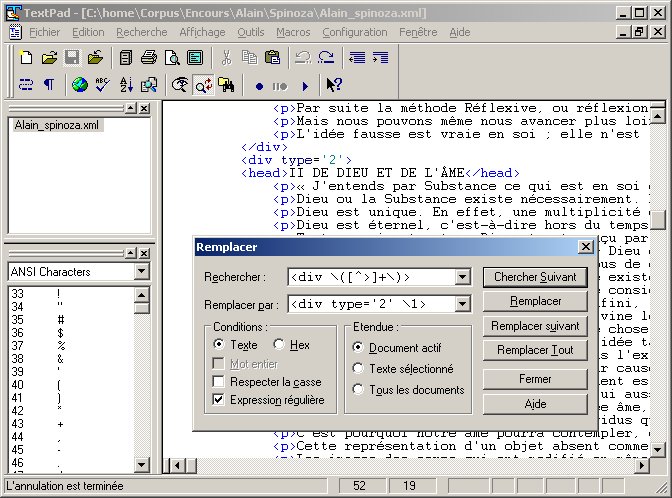
s/^([ \t]+)?([^> \t])(.+)$/\1<p>\2\3<\/p>\n/gm;Rechercher : ^\([ \t]+\)?\([^< \t]\)\(.+\)$ ne marche pas vraiment : conditionnel mal implémenté ; Remplacers/<(\/?)nom_du_tag(.*?)>/<\1nouveau_nom\2>/g;Rechercher : <\(\/?\)ancien_tag\(.*?\)> pb également; Remplacerm/<([^\s]+)\s+[^>]*?rend=(["'])italics\2[^>]*?>((.*?|\s*?)*?)<\/\1>/gRechercher : Le logiciel propose une "boîte de dialogue" Chercher (menu Recherch->Chercher, touche F5) et une boîte de dialogue Remplacer (menu Recherch->Remplacer, touche F8 ou Ctrl-H) avec un champ "Rechercher" et un champ "Remplacer". Pour bénéficier des expressions régulières il faut cocher la case correspondante parmi les options.
Figure 1 : Recherche d'une regexe avec
Textpad
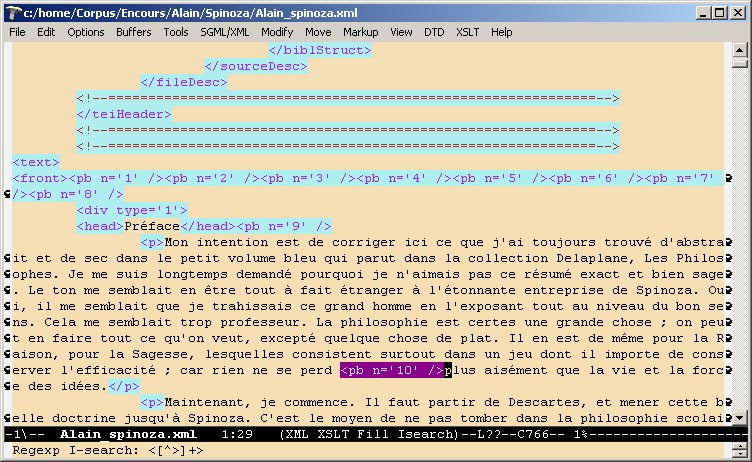 Figure 2 :Recherche d'une regexe avec Emacs. Ici, avec C-M-s (Ctrl-Alt-s), on parcourt toutes les balises.
Figure 2 :Recherche d'une regexe avec Emacs. Ici, avec C-M-s (Ctrl-Alt-s), on parcourt toutes les balises.
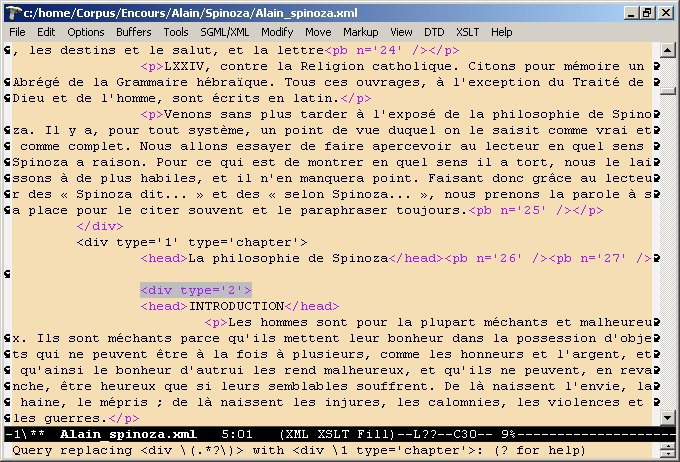 Figure 3 : Remplacement d'une regexe avec Emacs (C-M-% (Ctrl-Alt-%)). Si le remplacement est correct, on peut demander "!" pour remplacer
toutes les occurrences restantes.
Figure 3 : Remplacement d'une regexe avec Emacs (C-M-% (Ctrl-Alt-%)). Si le remplacement est correct, on peut demander "!" pour remplacer
toutes les occurrences restantes.
Documentation pour l'utilisation des expressions rationnelles dans un programme Perl :
Principaux éléments :
Depuis la ligne de commande
Perl est une solution simple à mettre en oeuvre pour les regexes, puisqu'il n'y a pas besoin d'ouvrir un éditeur ni même le fichier. On peut effectuer directement un simple remplacement depuis la ligne de commande, sans écrire le programme dans un fichier :
Perl -e "s/(oui|yes|si)/non/g" -p -i.bak fichier.xml
L'interpréteur exécute le bout de code entre guillemets (c'est l'effet de "-e"). Il effectue le remplacement dans le fichier donné en argument (fichier.xml), et sauvegarde l'ancien fichier dans "fichier.xml.back".
Pour utiliser les regexes dans un script
m// (match) permet de rechercher, l'opérateur s/// (substitute) de remplacer
$variable =~ m/chaine recherchée/; # $variable n'est pas modifié $variable =~ s/chaine recherchée/chaine de remplacement/g; # le contenu de $variable est modifié
=~ permet d'appliquer une recherche ou un remplacement à une variable : ce n'est pas un opérateur d'assignation (=), on peut plutôt penser à "m" et "s" comme à des fonctions prenant deux arguments, la chaîne
source à gauche derrière "=~" et l'expression régulière à droite entre "/".
$content =~ s/oh/ah/g; # dans $content, tous les "oh" sont maintenant des "ah".
$result = $content =~ m/oh/; # $result = 1 si $content contient 'oh', une chaîne vide autrement
if ($content =~ m/oui/) { # passe la condition si $content contient "oui"
print "C'est d'accord";
}
while ($result =~ m/oui/g) {
print "un de plus\n";
}
my @result = $content =~ m/<[^>]+>/g; # @result contient une liste de toutes les balises.
my $result = $content =~ s/a/o/g; # $result contient le nombre d'occurrences remplacées.
Les principaux modificateurs
while ($content =~ m/oui/g) { #pour toutes les occurrences de "oui" dans $content
print "Un de plus";
}
my $content = "AbCd";
if ($content =~ /abcd/) { # Ici la condition serait satisfaite.
print "ok\n"
}
my $content = " <p> \n paragraphe \n\n</p>"; $content =~ s/(^[ \t]+)|([ \t]+$)//gm; # "ébarbe" les lignes : enlèves les espaces droite et gauche
Les principales classes
\w Match a "word" character [a-zA-Z_] \W Match a non-"word" character [^a-zA-Z_] \s Match a whitespace character [ \t\n\r\f] \S Match a non-whitespace character [^ \t\n\r\f] \d Match a digit character [0-9] \D Match a non-digit character [^0-9] \t tab \n newline \r return \f form feed