PORTRAIT DE LINGUISTE(S) À L'INSTRUMENT
Benoît
HABERT
LIR - LIMSI CNRS / Université Paris 10
SOMMAIRE :
1.
La linguistique « à linstrument »
2.
Le statut des objets techniques en linguistique
2.1.
Instrument, outil, utilitaire, ressource
2.2.
Instrument et dispositif expérimental
2.3.
Des dispositifs aux instruments
3.
Les instruments en linguistique : erreurs techniques et errances
humaines
3.1.
Instruments : une imperfection assumée
3.2.
Des instruments humains, trop humains
4.
Instrumenter en linguistique
4.1.
Que voir « à linstrument » ?
4.2.
Préparer les données pour linstrument
4.3.
Détourner un instrument
5.
Donner un statut aux instruments en linguistique
1. La linguistique « à
l'instrument » ![]()
A part des domaines comme la psycholinguistique, la phonétique et la phonologie, une bonne partie de la recherche linguistique ne suppose pas d'instrument particulier. C'est en tout cas un implicite largement partagé, en particulier depuis les débuts de la grammaire générative. Cette situation se trouve aujourd'hui bousculée par la multiplication, particulièrement sensible depuis une dizaine d'années, avec l'émergence du Web, des outils, des instruments et des ressources modifiant les conditions de constitution d'observables et d'analyse de données en sciences du langage. A côté d'une linguistique sans instrument, s'impose clairement une linguistique « à l'instrument ».
En tout cas, a progressé depuis quelques années l'idée que la linguistique pouvait, voire devait, faire appel à des outils [1]. L'essor renouvelé en France, depuis moins de 10 ans, des linguistiques de corpus a rendu les linguistes plus sensibles au versant technique de la manipulation des données de langue. Dans ce contexte, j'ai défendu la perspective d'outiller la linguistique [Habert, 2004]. Influencé probablement par l'éventail très ouvert des réalités couvertes par tool en anglais, en particulier en informatique ou en ingénierie linguistique, je n'ai pas suffisamment prêté attention aux confusions conceptuelles qui pouvaient découler d'un emploi trop large du mot outil, comme le soulignait pourtant voici près de cinquante ans Gilbert Simondon dans Le mode d'existence des objets techniques [Simondon, 1989]. C'est donc aux statuts possibles de l'instrument en linguistique aujourd'hui et à une clarification des notions connexes que sont consacrées ces pages. Elles s'inscrivent dans le contexte général de l'annotation automatique ou semi-automatique de données langagières [Véronis, 2000b]. L'annotation consiste à ajouter de l'information (une interprétation stabilisée) aux données langagières : sons, caractères et gestes. Elle associe deux ou trois volets : i) segmentation pour délimiter des fragments de données et/ou ajout de points singuliers ; ii) regroupement de segments ou de points pour leur affecter une catégorie ; iii) (éventuellement) mise en relation de fragments ou de points. Par exemple, l'annotation syntaxique consiste à découper des suites de mots, à leur affecter des étiquettes de constituants (groupe nominal, noyau verbal, etc.), et à ajouter les relations fonctionnelles (sujet, objet, etc.), entre ces constituants. Les ponctuations constituent des points singuliers, qui peuvent faire partie d'un constituant, séparer deux constituants ou deux phrases. La figure 1 fournit une telle annotation du dernier vers du Dormeur du Val de Rimbaud, en suivant les conventions du Corpus arboré de Paris 7 (http://www.llf.cnrs.fr/fr/Abeille/French_Treebank.pdf). Un certain nombre de segments sont délimités. Ils sont étiquetés comme constituants éventuellement enchâssés : les syntagmes adjectivaux (AP) rouges et droit, les syntagmes nominaux (NP) il et deux trous rouges, le syntagme prépositionnel (PP) au côté droit, le VN (noyau verbal) a, le point final considéré comme un point singulier (mais non étiqueté). Ces segments délimités et étiquetés sont mis en relation. Le NP (syntagme nominal) il occupe la fonction SUJ(et), le NP deux trous rouges la fonction OBJ(et) et le PP au côté droit la fonction MOD(ifieur) du noyau verbal. Des relations d'enchâssements sont établies entre les AP rouges et droit et respectivement un NP et un PP. Enfin, un constituant de plus haut niveau, SENT(ence), c'est-à-dire phrase, regroupe les autres (y compris le point).
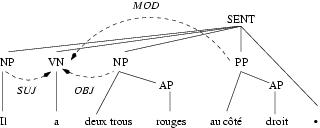
Figure 1 : Annotation syntaxique du v. 14 du Dormeur du Val
Dans un premier temps, je préciserai ce qu'est un outil, ce qu'est un instrument, en particulier par rapport à la notion de dispositif expérimental. Dans un second temps, je distinguerai dans les scories des instruments actuels (et à venir) ce qui relève de la technique et ce qui relève des incertitudes des jugements humains que ces instruments cherchent à rendre opératoires. Dans un troisième temps, je présenterai des usages possibles des instruments désormais disponibles.
2. Le statut des objets
techniques en linguistique
![]()
Outil et instrument correspondent à une opposition entre polyvalence et spécialisation, tandis que dispositif expérimental et instrument relèvent d'un contraste entre instable et stable qui ressortit à la fois à une dimension historique et à une dimension sociale (homologation).
2.1. Instrument,
outil, utilitaire et ressource ![]()
Par instrument(en anglais tool), on entendra un logiciel qui prend en entrée une donnée langagière (du texte, de l'oral, un lexique...) et qui permet d'obtenir en sortie une représentation transformée (annotée), soit automatiquement soit semi-automatiquement soit manuellement. Un étiqueteur constitue un tel instrument. Il reçoit du texte brut et retourne un texte étiqueté : chaque mot est assorti d'une catégorie (nom, verbe, etc.) voire éventuellement lemmatisé (muni d'une forme canonique). Un logiciel d'aide à la transcription de l'oral constitue également un instrument : il permet d'écouter le signal sonore (en s'arrêtant, en « bouclant », en ralentissant le débit...), d'en voir des représentations graphiques (qui facilitent le repérage des pauses, des enchevêtrements, de la hauteur, etc.) et d'écrire la transcription correspondante, synchronisée avec le signal.
On réservera le mot outil (tool) pour les logiciels multi-usages, polyvalents, non spécifiquement orientés vers le traitement de données langagières mais qui peuvent être mis à contribution en linguistique. Par exemple, un tableur (une feuille de calcul) - comme Excel ou Gnumeric - permet des calculs en gestion, mais aussi sur des décomptes provenant d'observables linguistiques. Il en va de même pour un gestionnaire de bases de données relationnelles [2], comme Access ou MySQL [3]. On parlera d'utilitaire pour un logiciel qui assure une tâche limitée, périphérique à un traitement donné (on trouve aussi l'appellation imagée moulinette et celle de script). Un programme de segmentation d'un texte en phrases peut constituer un tel utilitaire.
L'opposition est ici double. En premier lieu, entre généricité de l'outil, destiné à une classe large de phénomènes (tout ce qui peut se représenter par des entités et des relations entre ces entités pour les gestionnaires de bases de données) et spécificité de l'instrument (transcription pour étudier la syntaxe de l'oral, le lexique employé avec Transcriber : http://sourceforge.net/projects/trans/ ; étude de la prononciation, de la prosodie, etc. avec Praat : http://www.praat.org). En second lieu, si la spécificité rassemble instrument et utilitaire par contraste avec les outils, instrument et utilitaire s'opposent cependant sur l'éventail des tâches qu'ils permettent d'accomplir, large dans le premier cas, limité dans le second.
Par ressource(resource), on entendra des données (des corpus écrits ou oraux, des dictionnaires électroniques, des bases de données). La distinction est relative : les données sont de plus en plus assorties d'instruments. Elles ne sont en effet pas forcément manipulables telles quelles. Elles nécessitent des instruments d'exploration, de filtrage, de tri ou de transformation. C'est le cas au premier chef de la Toile à laquelle nous n'avons accès que via des moteurs de recherche aux comportements distincts les uns des autres. La taille même des corpus aujourd'hui disponibles -- 220 millions de mots pour la base textuelle littéraire Frantext, dont plus de la moitié étiquetés, 100 millions de mots étiquetés pour le British National Corpus -- les rend « illisibles ». On ne les lit plus, on les explore. Pour Frantext, Stella et pour le BNC, Sarah sont les instruments qui rassemblent les fonctionnalités de requêtage offertes. Il s'agit dans ce cas d'instruments spécialisés : ils adaptent aux ressources pour lesquelles ils ont été développés des opérations comme la constitution de sous-corpus, les décomptes d'un phénomène au sein d'une partie par rapport au reste, l'édition de concordances, le filtrage des segments de textes en fonction de motifs, etc.
2.2. Instrument
et dispositif expérimental ![]()
On utilisera la dénomination dispositif expérimental, empruntée à la sociologie de l'innovation développée par Bruno Latour, pour un montage d'instruments, d'outils et de ressources servant à produire des « faits » dont la reproductibilité et le statut (l'interprétation) font l'objet de controverses.
Ressortissent partiellement aux dispositifs expérimentaux les aligneurs. L'alignement (multilingue) [Véronis, 2000a] part de deux textes qui sont en rapport de traduction. Il consiste à établir des correspondances de plus en plus fines (entre les parties du texte : alignement structurel ; entre phrases : alignement phrastique ; entre mots : alignement lexical). La figure 2 fournit le titre et le premier quatrain du poème de Rimbaud, Le Dormeur du Val et l'une de ses traductions sur la Toile (http://www.eyedia.com/rimbaud/anglais/sleepingman_an.html). Les grandes divisions du poème sont respectées (titre, et les strophes une à une). Elles permettent donc un premier alignement grossier. Par contre les subdivisions structurelles ne le sont pas forcément : le v. 2 de la version anglaise correspond au v. 2 et au v. 3 de la version française. Les phrases de deux textes alignés ne sont pas forcément en relation bi-univoque : à une phrase dans une langue peut en correspondre plusieurs dans l'autre (avec un remaniement éventuel de l'ordre des informations). C'est souvent le cas dans le passage du français à l'anglais : l'anglais privilégie la parataxe là où le français joue de la subordination. L'alignement lexical bute sur la répartition variable selon la langue entre mots simples et « mots en plusieurs mots » : ainsi « Le Dormeur » devient « The Sleeping Man ». « Belle infidèle » par force parfois, la traduction remanie alors en profondeur les structures. Au v. 4, sujet et verbe permutent : « qui mousse de rayons » vs.« where rays foam up » [où les rayons moussent].
La compositionnalité globale des traductions autorise les alignements au niveau du mot, de la phrase, de la partie de texte (avec des aménagements nécessaires, comme viennent de le montrer les exemples empruntés au Dormeur du Val). Cette compositionnalité entraîne un parallélisme approximatif : la traduction d'un segment occupe dans le texte-cible une place proche de celle de ce segment dans le texte-source. L'alignement utilise ce parallélisme et un certain nombre d'indices pour préciser les correspondances. Les meilleurs alignements sont ceux qui maximisent ce parallélisme et le nombre d'indices rapprochant les segments supposés se correspondre. La longueur des phrases constitue un premier indice. Les bons candidats traductionnels d'une phrase sont d'abord à chercher dans les phrases de longueur comparable situées à des endroits similaires. Des indices lexicaux sont également mis à contribution : consultation de dictionnaires bilingues, mais aussi recherche des transfuges comme les nombres ou les noms propres qui se retrouvent souvent à l'identique dans une autre langue et des « vrais amis », ces mots dont la forme est proche d'une langue à l'autre et qui correspondent au même sens (dans Le Dormeur du Val, « Nature », mais peut-être aussi « soldat » vs. « soldier », « octobre » vs. « October », « Val » vs. « Valley »).
Des instruments ont remplacé les dispositifs expérimentaux pour l'alignement phrastique -- des aligneurs sont effectivement commercialisés -- tandis que la recherche continue pour l'alignement lexical, par le biais de dispositifs expérimentaux. Les aligneurs fournissent aux traducteurs professionnels mais aussi aux lexicographes des équivalences traductionnelles qui complètent les usuels existants (en particulier dans les domaines spécialisés). On y trouve des correspondances pour les néologismes, mais aussi des variantes admises pour la traduction d'un mot donné ainsi que des indications sur la traduction la plus adéquate pour un terme (celle qui est homologuée par l'usage).
|
|
Le Dormeur du Val |
The Sleeping Man in the Valley |
|
1 |
Cest un trou de verdure où chante une rivière |
Its a hole of greenery where a river sings |
|
2 |
Accrochant follement aux herbes des haillons |
Hanging crazily the silver rags on the grass; |
|
3 |
Dargent ; où le soleil, de la montagne fière |
Where the sun, from the proud mountain, |
|
4 |
Luit : cest un petit val qui mousse de rayons. |
Shines: its a little valley where rays foam up. |
Figure 2 : Alignement d'une strophe de poème et de sa traduction
2.3. Des
dispositifs aux instruments ![]()
[Véronis, 2000b, p. 122] distingue trois stades dans « l'état de la technique pour les différents types d'annotation » :
recherche : existence de travaux de nature prospective, mais ne donnant pas encore lieu à des implémentations utilisables en situation d'annotation réelle ;
prototype : existence de logiciels dans les laboratoires, mais qui ne sont pas encore suffisamment robustes et suffisamment testés pour faire l'objet d'une diffusion importante ;
opérationnel : existence de logiciels commerciaux, ou de logiciels gratuits de large diffusion.
Le terme prototype dénomme effectivement un logiciel qui préfigure un instrument mais qui n'en a pas forcément le fini ni la stabilité. Néanmoins, la distinction recherche/prototype/opérationnel que propose J. Véronis ne se superpose pas exactement à la partition dispositif expérimental/prototype/instrument. J. Véronis met en avant le fini, la robustesse, la diffusion (commerciale ou non) du produit résultant. Derrière cette caractérisation, se joue en fait -- et c'est tout l'enjeu de la notion de dispositif expérimental -- la reconnaissance par une communauté donnée du bien-fondé des techniques mises en uvre pour les « faits » visés. On pourrait donc dire qu'un instrument, c'est un dispositif expérimental qui a réussi. Ce qu'il fait est homologué (après éventuellement une phase de prototypage). Pour reprendre [Stengers & Bensaude-Vincent, 2003, p. 115] :
Lorsqu'un dispositif expérimental a été reconnu comme pertinent, lorsque la signification des « faits » qu'il permet de produire a été reconnue comme fiable, ce dispositif peut, c'est une grande réussite scientifique, être décrit comme une sorte de « prototype » pour une lignée d'instruments, que ceux-ci permettent des mesures, des détections ou des transformations. Ces instruments pourront être utilisés dans des laboratoires n'appartenant pas à la spécialité d'origine, dans des hôpitaux, des industries, des garages, etc., voire être mis dans « toutes les mains ». Ils seront alors devenus ce que Bruno Latour a appelé des « boîtes noires », conçus pour être manipulés par des non-spécialistes qui n'ont pas besoin d'en connaître le mode de fonctionnement mais sont en position de « faire confiance » en la fiabilité de ce grâce à quoi ils pourront uvrer à leurs propres fins [4].
La limite dispositif expérimental/instrument varie donc dans le temps [5]. Les étiqueteurs, après une phase d'expérimentation où ils relevaient des dispositifs expérimentaux, sont suffisamment stabilisés désormais pour constituer des instruments (même si continuent la recherche et les expériences autour des techniques d'étiquetage). Il en va de même pour les moteurs de recherche. Sous leur forme actuelle, ils sont issus pour l'essentiel des dispositifs expérimentaux de la recherche d'information qui s'est développée depuis la fin des années cinquante. Ces dispositifs ont permis de tester plusieurs familles de modèles et de déterminer les forces, les faiblesses et les conditions d'utilisation de chacune [Sparck Jones & Willett, 1997][Baeza-Yates & Ribeiro-Neto, 1999].
A travers ces deux exemples, on constate que le passage d'un ou de plusieurs dispositif(s) à un instrument est conditionné par un consensus relatif sur ce qu'est le succès visé (la pertinence d'un document en recherche d'information, l'affectation d'une catégorie morpho-syntaxique en étiquetage), sur la manière de le mesurer et sur le degré minimal de réussite acceptable (niveau plancher). Simondon parle à cet égard de « filtre social ».
Les campagnes d'évaluation internationales et nationales (en France dans le cadre du programme Technolangue : http://www.technolangue.net) contribuent fortement à de tels consensus. Développées initialement en recherche et en extraction d'information, fortement appuyées par les institutions de recherche appliquée, elles ont été progressivement généralisées à d'autres domaines : étiquetage morpho-syntaxique ; reconnaissance d'entités nommées, c'est-à-dire des noms de personnes, d'institutions, de lieux, etc. ; réponse à des questions factuelles ; analyse syntaxique ; désambiguïsation sémantique (c'est-à-dire attribution à un mot en contexte du sens approprié), etc. Les participants disposent au départ d'un corpus d'entraînement annoté pour le phénomène considéré. Chacun améliore son système en utilisant ce corpus comme pierre de touche. Dans une deuxième phase, les participants reçoivent un corpus non annoté et doivent le retourner annoté par leur système. Les résultats sont évalués par rapport à une version étiquetée de ce deuxième corpus, avec des scores basés sur le rappel et la précision [6]. L'objectif de ces campagnes d'évaluation est de déterminer le niveau moyen que l'on peut attendre pour un type d'annotation donné et de faire émerger les approches efficaces pour ce faire, afin d'obtenir, in fine, des composants logiciels spécialisés et « branchables » (plug-ins), comme le souligne [Cunningham, 1999]. En ce sens, les campagnes d'évaluation contribuent à la stabilisation en instruments de certains dispositifs expérimentaux. Parallèlement progresse grâce à ces campagnes la mise en place de notations suffisamment consensuelles pour le niveau d'annotation donné. La campagne d'évaluation des étiqueteurs morpho-syntaxiques pour le français, GRACE, en 1996-1998 [Adda et al., 1999] s'était ainsi donné un jeu d'étiquettes pivot pour pouvoir comparer les résultats de la dizaine de participants.
A rebours, certains domaines, riches en expérimentations, ne disposent pas pour autant d'instruments, faute de consensus sur les méthodes à employer, sur les résultats à produire et sur l'évaluation de leur qualité. C'est le cas en acquisition automatique de catégories sémantiques lexicales [7]. L'objectif est de regrouper les mots d'un corpus en « classes sémantiques » basées sur les relations d'hyperonymie, de synonymie et d'antonymie à partir des ressemblances et des divergences entre les contextes où figurent ces mots. Les dimensions de variation entre les nombreux dispositifs expérimentaux construits dans ce but sont la nature même des corpus à utiliser (généralistes ou spécialisés), leur volume, la taille et le type de contextes pertinents (le document, le paragraphe, la phrase, les k mots autour du pôle considéré, les dépendances syntaxiques dans lesquelles il figure, etc.) et la manière de remplacer les proximités et les écarts dans les contextes par un indice synthétique de plus ou moins grande distance entre mots, etc. On ne dispose pas non plus ni d'un lexique sémantique de référence facilitant la mesure des résultats ni d'un accord sur ce qu'est une classe sémantique cohérente. Cette instabilité sur les méthodes et leur évaluation explique l'absence d'instruments. Elle n'empêche pas pour autant l'existence de produits logiciels, commercialisés ou non, qui matérialisent certains des choix possibles dans les axes de variation mentionnés.
Cette vision fondamentalement historique des relations entre dispositif et instrument rejoint l'analyse de Simondon : « L'unité de l'objet technique, son individualité, sa spécificité, sont les caractères de consistance et de convergence de sa genèse. La genèse de l'objet technique fait partie de son être » [Simondon, 1989, p. 20]. Dans un cours de 1971, L'invention dans les techniques, Simondon souligne la double contrainte en jeu : « L'invention technique, en tant que technique, est toujours un mixte d'auto-corrélation interne et d'adaptation : l'auto-corrélation lui donne la stabilité ; l'adaptation, l'utilité » [Simondon, 2005, p. 230]. L'alignement phrastique répond aujourd'hui à l'exigence d'auto-corrélation, pas l'alignement lexical : « ... c'est l'objet le plus stable et le plus cohérent, et non pas le plus complexe qui, pour un fonctionnement défini, recèle le plus de véritable technicité et peut fournir un schème transposable pour d'autres réalisations » (ibid., p. 92). L'adaptation concerne l'intégration plus ou moins aisée de l'objet technique dans le milieu associé. Dans le domaine de l'ingénierie linguistique, cette intégration dépend par exemple de l'architecture utilisée (Windows vs. Linux ou Unix), de la simplicité plus moins grande d'installation et d'utilisation, des associations facilitées ou non avec d'autres logiciels [8].
3. Les instruments en
linguistique : erreurs techniques et errances humaines ![]()
Les instruments en linguistique sont en particulier des instruments à classer (segmenter, assigner des étiquettes, mettre en relation). Les difficultés rencontrées relèvent de deux ordres d'explication : les limitations des techniques mises en place, qui conduisent à de vraies erreurs, d'une part, les incertitudes des jugements humains correspondant à ces classifications d'autre part, qui renvoient à des zones de flou.
3.1. Instruments :
une imperfection assumée ![]()
Aujourd'hui, certains traitements sont suffisamment stabilisés pour donner naissance à des instruments. Outre l'alignement phrastique et l'étiquetage morphosyntaxique, on peut mentionner la reconnaissance et le typage des noms propres (noms de personnes, d'institutions, de lieux, d'événements) ou encore l'analyse syntaxique partielle [Bourigault & Fabre, 2000] (elle fournit une partie seulement des dépendances fonctionnelles d'un texte).
La stabilisation de chacune de ces annotations n'implique pas pour autant l'infaillibilité des instruments correspondants. Les instruments ne sont pas parfaits. Ils se trompent. La comparaison de l'étiquetage du Dormeur du Val d'Arthur Rimbaud par le TreeTagger (http://www.ims.uni-stuttgart.de/projekte/corplex/TreeTagger/DecisionTreeTagger.html) et par Cordial (http://www.synapse-fr.com/) le manifeste à l'envi. Le lemme fourni par Cordial pour « rivière » est « rivier », forme inconnue du Petit Robert. « Argent » au vers 3 est étiqueté ADJINV, adjectif invariable (comme dans « une robe argent »). « Somme » au vers 10 (« il fait un somme ») est bien lemmatisé « somme », mais comme NCFS, nom commun féminin singulier : il s'agit du montant d'argent et pas du repos. Le TreeTagger lemmatise « rivière » en « rivière », considère « argent » comme un NOM... mais « mousse » au vers 4 comme un NOM également (dans « qui mousse de rayons »). « Nue », correctement identifié comme NOM au vers 7 (« sous la nue »), est malencontreusement étiqueté comme NOM au vers 5 (« tête nue »).
Toutefois, l'une des qualités appréciables d'un instrument par rapport à un annotateur humain, c'est que son comportement est reproductible et prévisible. Face aux mêmes données ou au même type de données, il produira toujours le même résultat. Utiliser au mieux un instrument, c'est donc profiter de cette stabilité pour savoir quels sont ses biais, ses réussites et ses erreurs systématiques.
Autant dire qu'une annotation n'est pas une donnée intangible, mais un résultat temporaire qu'on doit pouvoir corriger, faire évoluer. Une des manières d'améliorer une annotation à un niveau donné consiste d'ailleurs à combiner les résultats de plusieurs instruments opérant en parallèle. Alignons ainsi les résultats sur Le Dormeur du Val de Cordial et ceux du TreeTagger. Dans la figure 3, sont en gras les endroits où un étiqueteur donne la version juste alors que l'autre se trompe. Si l'on enlève les ponctuations, Le Dormeur du Val compte 124 mots. Le désaccord porte seulement sur 7 mots (moins de 6%) : le TreeTagger permet de rectifier 3 erreurs de Cordial (lemme correct pour « rivière », « argent » et « Nature » noms au lieu d'adjectifs invariables), et Cordial rend le service inverse dans 4 cas (« mousse » indicatif présent 3ème personne du singulier plutôt que nom, « nue » dans « tête nue » adjectif féminin singulier au lieu de nom, « comme » subordonnant et non adverbe, « berce » impératif 2ème personne du singulier et non indicatif présent 3ème personne du singulier). La convergence sur le reste accroît la confiance que l'on peut porter à l'étiquetage de ces mots (comme pour « chante », « une », et « tête » dans la figure). On voit que la combinaison des deux étiqueteurs diminue fortement le temps de vérification manuelle de l'étiquetage : on peut, au moins dans un premier temps, s'en tenir aux divergences. Ces techniques de combinaison d'instruments sont pratiquées pour d'autres niveaux : analyse syntaxique [Monceaux & Vilnat, 2003]... Elles supposent de régler trois types de problèmes. Il faut d'abord que les résultats produits par les instruments soient alignables. Il faut ensuite un jeu de catégories pivot pour comparer les annotations (ici la partie du discours a été choisie). Il faut enfin déterminer quoi faire en cas de divergence (quand plusieurs instruments sont en lice, on peut recourir à des procédures de « vote » : on choisit la solution retenue par la majorité des instruments).
|
V. |
Cordial |
TreeTagger |
| ||||||
|
mot |
lemme |
cat. |
POS |
mot |
lemme |
cat. |
POS |
||
|
M |
M |
||||||||
|
1 |
chante |
chanter |
VINDP3S |
V |
chante |
chanter |
VER: pres |
V |
|
|
1 |
une |
un |
DETIFS |
D |
une |
un |
DET: ART |
D |
|
|
1 |
rivière |
rivier |
NCFS |
N |
rivière |
rivière |
NOM |
N |
|
|
M |
M |
||||||||
|
3 |
argent |
argent |
ADJINV |
A |
argent |
argent |
NOM |
N |
|
|
M |
M |
||||||||
|
4 |
mousse |
mousser |
VINDP3S |
V |
mousse |
mousse |
NOM |
N |
|
|
M |
M |
||||||||
|
5 |
tête |
tête |
NCFS |
N |
tête |
tête |
NOM |
N |
|
|
5 |
nue |
nu |
ADJFS |
A |
nue |
nue |
NOM |
N |
|
|
M |
M |
||||||||
|
9 |
comme |
comme |
SUB |
C |
comme |
comme |
ADV |
R |
|
|
M |
M |
||||||||
|
11 |
Nature |
nature |
ADJINV |
A |
Nature |
nature |
NOM |
N |
|
|
11 |
berce |
bercer |
VIMPP2S |
V |
berce |
bercer |
VER: pres |
V |
|
|
M |
M |
|
|||||||
Figure
3 : Combinaison des étiquetages de Cordial et du TreeTagger
Clé
de lecture pour la colonne POS (Part of Speech Partie
du discours) : A(djectif), C(onjonction), N(om), R (adveRbe),
V(erbe).
3.2. Des
instruments humains, trop humains ![]()
La constitution collective de données annotées tout comme les démarches d'évaluation apportent des éclairages renouvelés sur la fiabilité et la cohérence des annotations humaines, aux différents niveaux de l'analyse linguistique. J. Véronis montre par exemple le décalage, au sein d'un groupe d'étudiants en maîtrise de linguistique, entre le sentiment d'aisance à repérer en contexte des mots polysémiques et les larges désaccords effectifs sur les mots jugés tels [Véronis, 2004]. De la même manière, pour d'autres étudiants de même formation, l'écart est patent entre la facilité apparente à attacher à des mots polysémiques en contexte l'un des sens d'un dictionnaire généraliste (Le Petit Larousse) et la médiocrité de l'accord entre annotateurs sur les sens retenus, y compris lorsqu'on table sur la hiérarchisation des sens pour réduire l'éventail des étiquettes et disposer d'un « grain » sémantique plus grossier (ibid.). Les tâches qui semblent de prime abord aisées à un locuteur ou à un linguiste demandent à tout le moins une formation spécifique et un travail « jurisprudentiel », pour déterminer les choix à faire dans les cas difficiles. La constitution du « répartitoire » des catégories à employer, pour reprendre les termes de Damourette et Pichon, la détermination des conditions d'emploi de chacune des catégories sont pleinement des activités de recherche dont l'importance est pourtant souvent mésestimée, comme le souligne [Sampson, 2000].
De telles analyses relativisent les erreurs des traitements automatiques, y compris pour des tâches jugées simples, comme l'étiquetage morpho-syntaxique ou les découpages élémentaires en phrases et mots. On peut en conclure que le « plafond » à atteindre pour une annotation donnée n'est pas forcément 100% dans les cas où la performance humaine n'est pas suffisamment stable. A la variabilité des accords inter-annotateurs évoqués au paragraphe précédent, il faut d'ailleurs ajouter la mouvance de l'accord intra-annotateur : un même fragment, annoté par la même personne à intervalles éloignés, ne recevra pas forcément la même étiquette ; au fil du texte, un annotateur fluctue dans les décisions qu'il prend pour un phénomène donné. Sans doute convient-il d'examiner la situation niveau par niveau. A l'évidence, il y a des domaines où les consensus nécessaires peuvent s'appuyer sur une décantation préalable. C'est le cas de l'étiquetage morpho-syntaxique, qui bénéficie d'une stabilisation sur plusieurs siècles d'un découpage en « parties du discours ». Il n'en va déjà pas de même en syntaxe. La prédominance des divergences pour les découpages sémantiques conduit même G. Sampson à douter de la possibilité d'une annotation sémantique homogène et, partant, d'un traitement automatique reproductible à ce niveau : « le sens des mots ne relève pas des phénomènes dont peuvent rendre compte des théories scientifiques empiriques et prédictives » [Sampson, 2001]. A tout le moins, faut-il prendre toute la mesure du caractère culturel des catégories employées par une annotation [9]. A l'inverse, cette relativité des classements opérés n'autorise pas à dire que la tâche est impossible.
L'annotation suppose un consensus relatif et provisoire sur la manière de découper et d'étiqueter en fonction des phénomènes visés. Relatif, ce consensus l'est par rapport aux personnes en charge de l'annotation manuelle ou de la mise au point de l'outil d'annotation. Il dépend également de l'objectif de l'annotation. Ainsi une analyse syntaxique automatique destinée à la gestion de dialogues homme-machine pose des contraintes différentes d'une analyse visant au repérage de régularités syntactico-sémantiques : les constituants et les fonctions nécessaires ne seront pas les mêmes, les points cruciaux non plus.
En aval, l'annotation concrétise, réifie un certain état de connaissances sur une certaine gamme de phénomènes pour une communauté scientifique donnée : « Ce qui réside dans les machines, c'est de la réalité humaine, du geste humain fixé et cristallisé en structures qui fonctionnent » [Simondon, 1989, p. 12]. Les instruments qui incorporent et rendent opératoires ces classifications des données langagières, s'ils rajoutent leurs propres erreurs, portent en eux les incertitudes et les variations de la catégorisation humaine concernant le langage et les langues.
4. Instrumenter en
linguistique
![]()
Bourdieu disait des théories qu'elles sont des programmes de perception (elles fournissent le cadre permettant de constituer les « faits », elles délimitent pour l'essentiel ce qui va être observé et ce qui va être écarté). On peut également voir dans l'instrument « l'objet technique qui permet de prolonger et d'adapter le corps pour obtenir une meilleure perception ; l'instrument est outil de perception » [Simondon, 1989, p. 114]. Les instruments permettent de voir de nouveaux phénomènes. Leur emploi effectif ne va pas cependant sans ajustement nécessaire des données à observer. A l'inverse, les instruments se prêtent au détournement qui leur permet de traiter des données pour lesquelles ils n'avaient pas été prévus initialement, ouvrant la voie à de nouveaux progrès.
4.1. Que
voir « à l'instrument » ? ![]()
La ligne de partage que Simondon établit entre outil et instrument dans le cours L'invention et le développement des techniques (1968-1969) est la suivante : « [l'instrument] est l'inverse de l'outil, car il prolonge et adapte les organes des sens : il est un capteur, non un élément effecteur. L'instrument équipe le système sensoriel, il sert à prélever de l'information, tandis que l'outil sert à effectuer une action » [Simondon, 2005, p. 88-89]. Examinons deux prototypes d'instruments spécifiques, le premier dédié à l'analyse du vers classique, l'autre à la variation terminologique.
Pour dégager les régularités rythmiques de l'alexandrin classique, à partir des 77 186 alexandrins des pièces en vers de Corneille et Racine, corpus complété par des oeuvres en alexandrins représentatives du dix-neuvième siècle, V. Beaudouin entreprend l'exploitation systématique et la mise en correspondance des niveaux phonétique, lexical et morpho-syntaxique [Beaudouin, 2002]. Le prototype construit pour explorer les niveaux retenus, le métromètre, utilise et adapte des analyseurs informatiques spécifiques : le phonétiseur de F. Yvon (ENST), l'étiqueteur morpho-syntaxique de P. Constant [Constant, 1991]. Il fournit pour chaque vers cinq niveaux de représentation : les syllabes métriques, les voyelles métriques, le repérage des fins de mots, les parties du discours des mots et le marquage accentuel. La figure 4 fournit ces niveaux de représentation pour le premier hémistiche du Dormeur du Val [10]. Le métromètre permet de constater par exemple que la « règle des quatre accents » par alexandrin n'est en réalité vérifiée qu'à 60%... Il offre surtout la possibilité effective de saisir des corrélations entre les niveaux annotés. Ainsi :
La frontière entre deux hémistiches, entre la fin d'un vers et le début du suivant, se construit par le contraste maximal, quel que soit le marquage, entre la fin d'un segment et le segment suivant : en début de segment, les syllabes ne sont que très rarement accentuées, les mots-outils (articles, prépositions, pronoms, conjonctions...) sont très fréquents et les syllabes très fluettes (en nombre moyen de phonèmes) ; en fin de segment, l'accent est quasi-systématique, les mots-pleins (noms, verbes, adjectifs et adverbes) ont effacé tous les mots-outils et les syllabes sont devenues « épaisses ». Contraste important entre la fin d'un segment et le suivant, mais aussi entre la fin d'un segment et l'avant-dernière position, dont le profil est assez similaire au début de segment. Tout se passe comme si l'éminence de la fin du segment métrique était renforcée, garantie par le déficit de marquage des positions adjacentes [Beaudouin, 2004, p. 133].
|
O0 |
= |
Cest |
un |
trou |
de |
verdure... | ||
|
O1 |
= |
(s ai) |
(lt un) |
(t r ou) |
(d @) |
(v ai r) |
(d u r) |
|
|
O2 |
= |
1 |
0 |
1 |
0 |
0 |
1 |
|
|
O3 |
= |
12 |
|
|
|
|
|
|
|
O4 |
= |
1 |
6 |
0 |
7 |
0 |
0 |
|
|
O5 |
= |
1 |
1 |
1 |
1 |
0 |
1 |
|
|
|
|
|
|
|
|
|
|
|
|
Clé de lecture |
|
|
|
|
|
|
|
|
|
O1 en SAMPA |
|
sE |
te |
tRu |
d@ |
vER |
dyR |
|
|
O2 Accents |
|
+ |
- |
+ |
- |
- |
+ |
|
|
O3 Syllabes |
|
12 |
|
|
|
|
|
|
|
O4 Catégorie |
|
verbe |
déterminant/pronom |
nom |
préposition |
nom |
|
|
|
O5 Fin Mot |
|
FM |
|
FM |
|
|
FM |
|
Figure 4 : 1er hémistiche du Dormeur du Val passé au métromètre
L'examen des corpus spécialisés prouve qu'un terme donné se réalise rarement sous une forme unique (la « forme conseillée » des terminologies normatives), mais qu'il figure dans un halo de variations. Par exemple, en médecine du cur, une des affections possibles d'une artère, la sténose, apparaît dans des séquences comme 1) sténose de l'IVA proximale, mais aussi 2) sténose serrée du tronc commun, 3) sténose très serrée de l'IVA proximale, 4) sténose circonflexe moyenne serrée. On observe un réseau de variations qui mettent en jeu des mots relevant des mêmes catégories sémantiques. On peut se demander alors s'il s'agit de variantes effectives d'un terme déjà connu ou d'un terme à découvrir. L'objectif de C. Jacquemin est précisément de pouvoir relier les séquences qui sont des variations syntaxiques, voire sémantiques, les unes des autres [Jacquemin, 2001]. L'approche choisie par C. Jacquemin et qui a donné naissance au prototype FASTR est fondamentalement syntaxique. Il s'agit à partir de l'arbre entièrement lexicalisé représentant un terme connu (un arbre dont les feuilles lexicales donc sont identifiées) d'engendrer les différents arbres syntaxiques partiellement lexicalisés correspondant aux variantes syntaxiques envisageables de l'arbre de départ. A partir de sténose serrée de l'IVA, FASTR engendre ainsi l'arbre correspondant à l'insertion d'un adverbe de degré avant l'adjectif (sténose <adverbe de degré> serrée de l'IVA), mais aussi l'arbre correspondant à l'ajout d'une coordination (sténose serrée de l'IVA et de <déterminant défini> <nom>), et à la combinaison des deux, etc. C. Jacquemin a mis au point pour ce faire des « méta-règles » qui constituent une restriction sur l'ensemble des règles syntaxiques dont relèveraient a priori les termes en tant que syntagmes nominaux. En effet, toutes les « transformations » ne donnent pas naissance à des candidats-termes plausibles. On ne pourrait par exemple remplacer l'article défini par un démonstratif dans la dernière variante ci-dessus. Les méta-règles nécessitent alors de pouvoir vérifier des contraintes fines (sur des traits lexicaux, morpho-syntaxiques ou sémantiques). Après cette phase d'engendrement de variations éventuelles, la tâche assignée à FASTR est d'aller chercher dans les corpus utilisés les séquences qui peuvent leur correspondre. Comme ces variations sont reliées au terme qui a servi à les engendrer, on obtient effectivement un réseau de variantes-candidates pour un terme donné. C. Jacquemin a appliqué cette approche au français comme à l'anglais, en mettant au point les méta-règles correspondantes. Il l'a testée sur des corpus spécialisés (médecine, métallurgie) en prenant comme « semences » les termes proposés par l'INIST - Institut de l'Information Scientifique et Technique du CNRS. La mise au point des méta-règles, pour les deux langues, est l'occasion d'une réflexion et d'expériences poussées. C. Jacquemin examine tout particulièrement le rôle de la coordination, de la permutation, de l'insertion et de l'élision. Il utilise également des ressources lexicales pour rechercher des variantes relevant de la morphologie dérivationnelle (passage de l'adjectif relationnel au syntagme prépositionnel, et vice-versa, par exemple). Il aborde également le repérage de variantes sémantiques, en partant d'une liste de synonymes (le thesaurus AGROVOC de l'INIST pour traiter un corpus concernant l'agriculture). De nombreuses analyses de détail montrent le va-et-vient obstiné entre des méta-règles déjà spécifiques et l'examen des collectes qui en résultent pour progresser vers une véritable « grammaire des termes et de leurs variantes ». Le prototype d'instrument pour l'analyse fine de la variation terminologique qu'est FASTR joue un rôle central dans cette avancée.
4.2. Préparer
les données pour l'instrument ![]()
De la même manière qu'un instrument de mesure a des conditions d'emploi (un thermomètre médical ne peut mesurer que de 35 à 41° Celsius), les instruments d'annotation ne sont pas « tout terrain ». Les étiqueteurs, par exemple, sont mis au point pour du texte « policé ». Des courriers électroniques riches en émoticônes (ou smileys), en marques typographiques de dialogue, déboucheront sur des taux de réussite bien plus faibles que les 95 à 97% de mots correctement étiquetés normalement attendus pour du français écrit standard. Selon les cas, on peut en tirer la conclusion soit que tel instrument n'est pas applicable à la donnée dont on dispose (c'est connaître les limites de son instrument), soit que cette donnée est à « aménager » pour la rendre plus aisément annotable. Donnons un exemple de la deuxième branche de l'alternative.
L'étiqueteur Cordial considère les vers comme des phrases indépendantes, en raison de la majuscule initiale (quand les vers ne se terminent pas par une ponctuation forte mais par un passage à la ligne, le programme leur réserve le même traitement qu'aux titres). Ce « réglage » implicite est source d'erreurs pour Le Dormeur du Val. A contrario, si l'on élimine la structure formelle de ce poème en enlevant les passages à la ligne et les majuscules de début de vers (figure 5), les résultats de Cordial s'améliorent (figure 6). Ainsi « argent », au vers 3, auparavant considéré comme un adjectif invariable, est désormais un nom commun masculin singulier. Les données de départ gagnent donc souvent à être nettoyées et normalisées avant d'être soumises à un instrument d'annotation.
|
Le Dormeur du Val. Cest un trou de verdure où chante une rivière accrochant follement aux herbes des haillons dargent ; où le soleil, de la montagne fière, luit ; cest un petit val qui mousse de rayons Les parfums ne font pas frissonner sa narine ; il dort dans le soleil, la main sur sa poitrine tranquille. Il a deux trous rouges au côté droit. |
Figure 5 : Le Dormeur du Val en phrases
|
vers |
phrases | ||||
|
... |
... | ||||
|
rivière |
rivier |
NCFS |
rivière |
rivier |
NCFS |
|
===== FIN DE PHRASE ===== |
|
|
|
||
|
==== DEBUT DE PHRASE ==== |
|
|
|
||
|
Accrochant |
accrocher |
VPARPRES |
accrochant |
accrochant |
VPARPRES |
|
follement |
follement |
ADV |
follement |
follement |
ADV |
|
aux |
au |
DETDPIG |
aux |
au |
DETDPIG |
|
herbes |
herbe |
NCFP |
herbes |
herbe |
NCFP |
|
des |
de |
DETDPIG |
des |
de |
DETDPIG |
|
haillons |
haillon |
NHMIN |
haillons |
haillon |
NHMIN |
|
===== FIN DE PHRASE ===== |
|
|
|
||
|
==== DEBUT DE PHRASE ==== |
|
|
|
||
|
D' |
de |
PREP |
d' |
de |
PREP |
|
argent |
argent |
ADJINV |
argent |
argent |
NCMS |
|
; |
; |
PCTFORTE |
; |
; |
PCTFORTE |
|
===== FIN DE PHRASE ===== |
===== FIN DE PHRASE ===== |
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Figure 6 : Cordial et Le Dormeur du Val (vers vs. phrases)
4.3. Détourner
un instrument ![]()
Simondon insiste sur l'atout que constitue l'ouverture pour certains objets techniques : « Le véritable perfectionnement des machines, celui dont on peut dire qu'il élève le niveau de technicité, correspond non pas à un accroissement de l'automatisme, mais au contraire au fait que le fonctionnement d'une machine recèle une certaine marge d'indétermination » [Simondon, 1989, p. 11]. Une partie du progrès technique se produit en effet par détournement d'instrument, à main armée de technique, comme le montrent les deux exemples suivants. C'est « pousser son instrument ».
L'étiquetage morpho-syntaxique de l'oral est difficile avec les instruments actuels. Ces étiqueteurs ont été en effet développés pour de l'écrit relativement normé et ils sont perturbés par les notations propres à l'oral (répétitions, absence de ponctuation), dans des proportions qui varient selon les conventions de transcription retenues et selon le type d'oral traité (policé ou fortement interactif, avec chevauchements). Pourtant, la transcription orthographique « nue » s'avère rapidement insuffisante lorsqu'augmente le volume des transcriptions effectuées ou si l'on veut isoler des configurations morpho-syntaxiques spécifiques. Les résultats des concordances sont par exemple bruités par les homographes (« fait » : nom ou participe passé, ou encore fragment des mots en plusieurs mots « en fait », « tout à fait » ?). Lorsqu'on étudie des phénomènes comme les marqueurs discursifs ou les amorces et répétitions, on peut tirer profit de catégories morpho-syntaxiques, à la fois pour déterminer les catégories affectées et pour mieux connaître les « sites » où se produisent ces phénomènes. En attendant la mise au point d'étiqueteurs adaptés à l'oral, on peut s'inspirer de la stratégie présentée dans [Valli & Véronis, 1999]. A. Valli et J. Véronis ont « détourné » un étiqueteur prévu pour l'écrit, Cordial. Un pré-traitement modifie la transcription manuelle (enlèvement des pauses silencieuses ou remplies, des amorces de mots interrompus, des indications d'événements non linguistiques, etc.). Cordial étiquette alors cette version aménagée. Un post-traitement aligne enfin les formes conservées dans la version aménagée et leurs étiquettes avec la version de la transcription manuelle. On obtient alors un étiquetage partiel mais fiable pour les mots étiquetés. Sur un tour de parole de l'exemple que les auteurs fournissent, le résultat est le suivant (en gras, ce qui n'est pas étiqueté) :
doncCoo surPrep votreDetPoss activitéNcfs - euh professionnelleAdjfs - hein voilàPrep est-ce queAdv qu- alorsAdv quandSub vousPpers2p vousPpers2p mPpers1s ditVparpms queSub vousPpers2p êtesVindp2p électronicienNcms
On voit que l'essentiel des mots se trouvent étiquetés, ce qui permet des concordances plus précises.
D. Bourigault a développé en 1993 Lexter, un instrument de détection de possibles séquences terminologiques [Bourigault, 1993]. Lexter isole, au sein des syntagmes nominaux complexes, ceux qui présentent l'« air de famille » des entrées de terminologies : limitation de l'éventail des prépositions possibles, contraintes sur la détermination, etc. Ce logiciel correspondait au départ à des besoins industriels bien délimités : l'aide au développement de terminologies au sein d'EDF. Ces besoins impliquaient une grande robustesse : la possibilité de traiter de gros volumes de textes techniques pas toujours « léchés ». Lexter, grâce à D. Bourigault, a été rendu rapidement accessible d'abord à la communauté de la terminologie « assistée par ordinateur », via le groupe de travail Terminologie et Intelligence Artificielle, puis à des utilisateurs plus variés. Lexter a fini par jouer pour le français le rôle d'analyseur syntaxique relativement tout terrain, mais très partiel (puisque limité au syntagme nominal). Il a permis par exemple d'expérimenter l'apport de dépendances syntaxiques [Bouaud et al., 2000] dans une acquisition de classes syntactico-sémantiques inspirée des travaux de Harris sur les sous-langages [Harris et al., 1989]. Il a ouvert la voie à Syntex, l'analyseur syntaxique en dépendances que D. Bourigault et ses collègues ont depuis mis au point [Bourigault & Fabre, 2000]. Syntex est effectivement un descendant de Lexter, au plan des principes, et s'inscrit donc dans une lignée, au sens simondonnien, qui comprend également les travaux de F. Debili [Debili, 1982] et de G. Grefenstette [Grefenstette, 1994]. Cependant cette ouverture n'est pas seulement technique. Lexter a également contribué à créer ce que Simondon appelle le « milieu associé » à un instrument et qui est fondamental dans la réception de ce dernier et finalement pour son succès : l'ensemble des pratiques et des expériences qui facilitent l'adaptation de/à l'instrument.
[Véronis, 2000b, p. 113] souligne que de tels détournements peuvent correspondre à la création d'instruments autonomes :
... les technologies [d'annotation] existent parfois de façon « encapsulée » dans des logiciels dont la finalité n'est pas l'annotation de corpus, et ne sont pas directement accessibles à l'utilisateur. Il est parfois possible de les détourner ou de les contourner pour annoter des corpus, mais on peut souhaiter que ces technologies apparaissent en tant que telles hors des logiciels qui les contiennent pour l'instant. Le cas de Cordial, développé par la société Synapse, est de ce point de vue exemplaire. Cordial était au départ un correcteur orthographique et grammatical qui, comme tout correcteur de ce type, contenait un module de détermination des catégories grammaticales des mots mais dont les résultats n'étaient pas directement accessibles à l'utilisateur. A la suite d'une interaction avec des équipes universitaires dans le cadre de l'action GRACE d'évaluation des étiqueteurs grammaticaux..., la société Synapse a rendu disponible une version université dans laquelle le module grammatical est accessible et permet l'étiquetage de corpus.
5. Donner
un statut aux instruments en linguistique ![]()
A parler de l'« outil informatique » en général, ou à qualifier d'outil sans plus de nuances des composants très divers du travail actuel en linguistique étayée par l'informatique (une base de données textuelles, un tableur, un logiciel de statistique lexicale, un étiqueteur, etc.), on court le risque de penser plus difficilement les statuts de ces composants.
La distinction évolutive entre dispositifs expérimentaux et instruments devrait en outre aider à délimiter les domaines des sciences du langage où l'annotation automatique est stabilisée de ceux où elle ne l'est pas. Elle devrait permettre également, pour ces derniers, de se poser la question de ce qui peut l'être et de ce qui risque de résister.
G. Bachelard écrivait en 1938 : « [...] on pourrait déterminer les différents âges d'une science par la technique de ses instruments de mesure » [11]. Si la linguistique peut désormais recourir à de nouveaux instruments, il lui faut certainement aller plus avant dans l'approfondissement des changements de pratiques liées à ces instruments et plus généralement au déplacement des rapports entre science et technique [Hottois, 2004]. Les portaits de linguiste(s) à l'instrument restent à peindre...
Je remercie Martine Adda (LIMSI), Jean-Baptiste Berthelin (LIMSI), Didier Bourigault (ERSS), Serge Fleury (SYLED & université Paris III), Serge Heiden (ICAR), Martine Hurault-Plantet (LIMSI), Michèle Jardino (LIMSI) et Sylvie Mellet (Bases) pour leur regard critique sur une première version de ces pages.
Une version fortement abrégée de ces pages paraîtra en 2006.
![]()
NOTES
1 Voir par exemple le vol. IX n°1, juin 2004, de la Revue Française de Linguistique Appliquée : Linguistique et informatique : nouveaux défis.
2 [Vaguer, 2004] fournit un exemple d'utilisation de bases de données relationnelles pour analyser certains emplois de la préposition « dans ».
3 C'est d'ailleurs la dénomination d'« outils informatiques » qui coiffe, dans [Pinol & Zysberg, 1995], la présentation de l'usage en histoire des tableurs et des gestionnaires de bases de données. Pour une présentation notionnelle de ces outils, en dehors de logiciels spécifiques, voir [Hainaut, 2002].
4 Je rejoins Sylvie Mellet sur la nécessité néanmoins de ne pas confondre « boîtes noires », c'est-à-dire le fait d'accepter un certain type de résultat pour un certain objectif et « magie noire », qui revient à s'en remettre à des outils, à des dispositifs ou à des instruments sans (chercher à) comprendre sur le fond la nature des opérations en cause et à utiliser leur résultat comme simple faire valoir de positions pré-établies. Le statut effectif des logiciels d'aide à l'analyse de textes - leur rôle, les contraintes qu'ils créent ou non dans la construction de l'interprétation - est à examiner sous cet angle. Simondon écrivait joliment : « Pour redonner encore à la culture le caractère véritablement général qu'elle a perdu, il faut pouvoir réintroduire en elle la conscience de la nature des machines, de leurs relations mutuelles et de leurs relations avec l'homme, et des valeurs impliquées dans ces relations. Cette prise de conscience nécessite l'existence, à côté du psychologue et du sociologue, du technologue ou mécanologue » [Simondon, 1989, p. 13]. Accepter que certains modules fonctionnent à un moment donné comme des boites noires ne conduit certes pas à désirer des utilisateurs inconscients.
5 Il en va de même d'ailleurs pour la frontière entre instrument et utilitaire. Devient utilitaire l'instrument tellement stabilisé qu'il n'est plus qu'un composant minime dans un vaste ensemble. La segmentation en mots et en phrases joue aujourd'hui le rôle de composant et d'utilitaire dans certains instruments (étiqueteurs, analyseurs syntaxiques), alors qu'il s'agit de tâches complexes [Grefenstette & Tapanainen, 1994][Habert et al., 1998], dont l'automatisation reste problématique (voir par exemple le problème des « mots en plusieurs mots » étudiés par le LADL sous la dénomination de « mots composés »). Il en va de même des correcteurs orthographiques désormais intégrés aux traitements de texte ou aux moteurs de recherche.
6 Le rappel est la proportion de bonnes réponses fournies au sein des bonnes réponses possibles. La précision est la proportion de bonnes réponses dans les réponses fournies.
7 Voir [Zweigenbaum & Habert, 2004] pour une présentation d'ensemble.
8 On peut analyser en ces termes le succès de l'étiqueteur Cordial.
9 On peut d'ailleurs estimer que le paradigme actuel d'évaluation en termes de rappel/précision agit dans certains domaines comme un lit de Procuste : il peut conduire à sous-estimer les hésitations inter et intra-annotateurs lors de la construction de données de référence. Voir [Sparck Jones, 2001]. Les zones de flou semblent globalement minorées.
10 Dans la clé de lecture, la notation SAMPA (Speech Assessment Phonetic Alphabet) est utilisée pour les phonèmes [Gibbon et al., 1997]. SAMPA n'utilise que la partie « universelle » des claviers (celle de l'ASCII) pour faciliter l'utilisation de notations phonétiques à travers le monde sans dépendre ni des différents claviers disponibles ni d'une police de caractères spécifique pour l'Alphabet Phonétique International ni d'un clavier virtuel permettant de saisir directement les caractères phonétiques d'Unicode. C'est bien évidemment une solution de transition en attendant que se répande le recours à Unicode.
11 La formation de l'esprit scientifique, Vrin, 1938, p. 216, cité dans [Lecourt, 1971, p. 138].
BIBLIOGRAPHIE
Adda, G., Mariani, J., Paroubek, P., Lecomte, J. (1999). « Métrique et premiers résultats de l'évaluation GRACE des étiqueteurs morphosyntaxiques pour le français ». In Amsili, P. (ed), Actes de TALN'99 (Traitement Automatique des Langues Naturelles), pages 15-24, Cargèse. ATALA.
Baeza-Yates, R. & Ribeiro-Neto, B. (1999). Modern Information Retrieval. ACM Press Books. Addison-Wesley, Reading, Massachusetts.
Beaudouin, V. (2002). Mètre et rythmes du vers classique : Corneille et Racine. Lettres numériques. Honoré Champion, Paris.
Beaudouin, V. (2004). « Mètre en règles ». Revue Française de Linguistique Appliquée, IX(1):119-137.
Bouaud, J., Habert, B., Nazarenko, A., Zweigenbaum, P. (2000). « Regroupements issus de dépendances syntaxiques sur un corpus de spécialité : catégorisation et confrontation à deux conceptualisations du domaine ». In Charlet, J., Zacklad, M., Kassel, G., Bourigault, D. (eds), Ingénierie des connaissances : évolutions récentes et nouveaux défis, ch. 17, pages 275-290. Eyrolles, Paris.
Bourigault, D. (1993). « Analyse syntaxique locale pour le repérage de termes complexes dans un texte ». TAL, 34(2).
Bourigault, D. & Fabre, C. (2000). « Approche linguistique pour l'analyse syntaxique de corpus ». Cahiers de grammaire, (25):131-151.
Constant, P. (1991). Analyse syntaxique par couches. Doctorat de l'ENST, École Nationale Supérieure des Télécommunications, Paris.
Cunningham, H. (1999). « A definition and short history of Language Engineering ». Natural Language Engineering, 5(1):1-16.
Debili, F. (1982). Analyse syntactico-sémantique fondée sur une acquisition automatique de relations lexicales-sémantiques. Thèse de doctorat d'état en informatique, Université Paris XI, Orsay.
Gibbon, D., Moore, R., Winski, R. (eds) (1997). Handbook of Standards and Resources for Spoken Language Systems. Mouton de Gruyter, Berlin.
Grefenstette, G. (1994). Explorations in Automatic Thesaurus Discovery. Kluwer Academic Publisher, Dordrecht, The Netherlands.
Grefenstette, G. & Tapanainen, P. (1994). « What is a word, what is a sentence ? problems of tokenisation ». In 3rd Conference on Computational Lexicography and Text Research (COMPLEX'94), Budapest.
Habert, B. (2004). « Outiller la linguistique : de l'emprunt de techniques aux rencontres de savoirs ». Revue Française de Linguistique Appliquée, IX(1):5-24.
Habert, B., Adda, G., Adda-Decker, M., de Marëuil, P. B., Ferrari, S., Ferret, O., Illouz, G., Paroubek, P. (1998). « Towards tokenization evaluation ». In Rubio, A., Gallardo, N., Castro, R., Tejada, A. (eds), Proceedings First International Conference on Language Resources and Evaluation, volume I, pages 427-431, Grenade.
Hainaut, J.-L. (2002). Bases de données et modèles de calcul. Outils et méthodes pour l'utilisateur. Sciences Sup. Dunod, Paris, 3ème edition.
Harris, Z., Gottfried, M., Ryckman, T., Mattick Jr, P., Daladier, A., Harris, T., Harris, S. (1989). The Form of Information in Science, Analysis of Immunology Sublanguage. Kluwer Academic Publisher, Dordrecht, The Netherlands.
Hottois, G. (2004). Philosophie des sciences, philosophie des techniques. Collège de France. Odile Jacob, Paris.
Jacquemin, C. (2001). Spotting and discovering terms through natural language processing. The MIT Press, Cambridge, Massachusetts.
Lecourt, D. (1971). Bachelard Epistémologie - Textes choisis. Les grands textes. Presses universitaires de France, Paris.
Monceaux, L. & Vilnat, A. (2003). « Evaluation, projection et combinaison d'analyses syntaxiques robustes ». TAL, 44(3):187-214.
Pinol, J.-L. & Zysberg, A. (1995). Métier d'historien avec un ordinateur. Fac Histoire. Nathan, Paris.
Sampson, G. (2000). « The role of taxonomy in language engineering ». Philosophical Transactions: Mathematical, Physical and Engineering Sciences, (358):1339-1355. Royal Society, London.
Sampson, G. (2001). Empirical Linguistics. Open Linguistics Series. Continuum, London.
Simondon, G. (1989). Du mode d'existence des objets techniques. L'invention philosophique. Aubier, Paris, 3ème edition. Première édition : 1958 - Préface de John Hart, postface de Yves Deforge.
Simondon, G. (2005). L'invention dans les techniques - cours et conférences. Traces écrites. Seuil, Paris. Edition établie et présentée par Jean-Yves Chateau.
Sparck Jones, K. (2001). « Automatic language and information processing: rethinking evaluation ». Natural Language Engineering, 7(1):29-46.
Sparck Jones, K. & Willett, P. (eds) (1997). Readings in Information Retrieval. Morgan Kaufmann, San Francisco, California.
Stengers, I. & Bensaude-Vincent, B. (2003). 100 mots pour commencer à penser les sciences. Les empêcheurs de penser en rond, Paris.
Vaguer, C. (2004). « Constitution d'une base de données : les emplois de dans marquant la coïncidence ». Revue Française de Linguistique Appliquée, IX(1):83-97.
Valli, A. & Véronis, J. (1999). « Etiquetage grammatical des corpus de parole : problèmes et perspectives ». Revue française de linguistique appliquée, IV(2):113-133.
Véronis, J. (2000a). « Alignement de corpus multilingues ». In Pierrel, J.-M. (ed), Ingénierie des langues, Informatique et systèmes d'information, ch. 6, pages 151-172. Hermès Science, Paris.
Véronis, J. (2000b). « Annotation automatique de corpus : panorama et état de la technique ». In Pierrel, J.-M. (ed), Ingénierie des langues, Informatique et systèmes d'information, ch. 4, pages 111-130. Hermès Science, Paris.
Véronis, J. (2004). « Quels dictionnaires pour l'étiquetage sémantique ? » Le français moderne, 72(1):27-38.
Zweigenbaum, P. & Habert, B. (2004). « Accès mesurés au sens ». Mots, (74):93-106. ENS Editions.
Vous pouvez
adresser vos commentaires et suggestions à : habert @ limsi.fr
(NB. Rétablir l'adresse en enlevant les espaces autour du @)
|
©
Référence
bibliographique : HABERT, Benoît. Portrait de linguiste(s) à
linstrument. Texto! [en ligne],
décembre 2005, vol. X, n°4. Disponible sur :
<http://www.revue-texto.net/Corpus/Publications/Habert/Habert_Portrait.html>.
(Consultée le ...). |