1. Discours
, genres et typologie des textes
![]()
Denise Malrieu & Franįois Rastier : GENRES ET VARIATIONS MORPHOSYNTAXIQUES
--- 548 ---
1. Discours
, genres et typologie des textes
![]()
Peu étudiée en linguistique, la notion de genre suscite des débats sur sa définition et son opérativité, car elle est souvent confondue avec celle de type de texte, et tantôt définie ā partir de Ģ fonctions du langage ģ [BIB 88 , 92], tantôt assimilée avec le domaine sémantique du discours [ILL99]. Alors que les travaux pionniers de [BIB 88 , 93 , 99] visent ā développer une typologie inductive des textes en les caractérisant par un ensemble de dimensions organisant des traits linguistiques, la recherche dont nous présentons les premiers résultats combine la catégorisation préalable des genres et l'approche empirique pour qualifier les différences significatives entre genres prédéfinis et tester la pertinence de leur classement initial.
1.1.
Discours et genres ![]()
Sans doute indéfinissables a priori , les fonctions du langage, se concrétisent dans des pratiques sociales diversifiées qui déterminent les discours et les genres. Comme tout texte relčve dun genre, la typologie des genres commande celle des textes. En outre, comme tous les genres relčvent dun discours déterminé, leur typologie est sans doute subordonnée ā celle des discours. [1]
Nous distinguons quatre niveaux hiérarchiques supérieurs au texte : les discours (ex. (juridique vs littéraire vs essayiste vs scientifique), les champs génériques (ex. théâtre, poésie, genres narratifs [2]), les genres proprement dits (ex. comédie, roman Ģ sérieux ģ, roman policier, nouvelles, contes, mémoires et récits de voyage), les sous-genres (ex. roman par lettres [3]). Au niveau inférieur de la classification, nous trouvons les textes dun męme auteur. Soit :
--- 549 ---
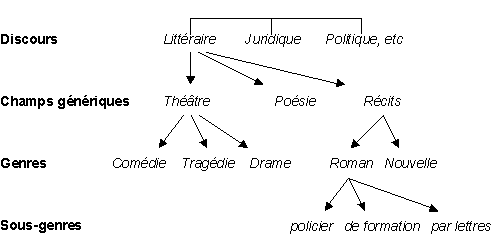
Figure 1 : Niveaux de classification
Aussi, cinq raisons convergentes engagent ā considérer le genre comme le niveau fondamental pour la catégorisation des textes.
(i) Il ny a pas de genres supręmes (pas de genre de genres), puisque les critčres de groupement des genres sont les discours et les pratiques qui leur correspondent. Aussi, de grandes catégories de lexpression, comme la prose ou loral, conduisent-ils ā des regroupements oiseux : par exemple, loral, de la brčve de comptoir au réquisitoire, na évidemment pas plus dunité que la prose. De męme, les catégories sémantiques de type fonctionnel (information, divertissement, etc.) regroupent des textes hétérogčnes par leur genre et leur discours.
(ii)
Pour établir le cadre conceptuel dune typologie des
genres, on peut concevoir la production et l'interprétation
des textes comme une interaction non-séquentielle
de composantes autonomes : thématique, dialectique,
dialogique et tactique [RAS 89]
.
La
thématique
rend compte des contenus investis, cest-ā-dire du
secteur de lunivers sémantique mis en uvre dans
le texte. Elle en décrit les unités ; par analogie,
et bien quelle ne décrive pas spécifiquement
le lexique, on peut dire quelle traite du vocabulaire
textuel (molécules sémiques, faisceaux disotopies,
etc.). La
dialectique
rend compte des intervalles temporels dans le temps représenté,
de la succession des états entre ces intervalles et
du déroulement aspectuel des processus dans ces intervalles.
--- 550 ---
La
dialogique
rend compte des modalités, notamment énonciatives
et évaluatives, ainsi que des espaces modaux quelles
décrivent. Dans cette mesure, elle traite de l'énonciation
représentée
lénonciation réelle ne relevant pas de
la linguistique, mais de la psycholinguistique ou de la
philosophie du langage.
La
tactique
rend compte de la disposition séquentielle du signifié,
et de lordre, linéaire ou non, selon lequel les unités
sémantiques ā tous les paliers sont produites et
interprétées.
Chacune de ces quatre composantes peut ętre la source de critčres typologiques divers, mais ne suffit pas ā caractériser un genre. Aussi admettons-nous cette hypothčse : sur le plan sémantique, les genres seraient définis par des interactions normées entre les composantes que nous venons dévoquer.
(iii) Les parties de genres sont elles-męmes relatives ā ces genres : par exemple, la description inaugurale dans la nouvelle du XIX e nest pas une simple occurrence de la description.
(iv) Les sous-genres, comme le roman de formation ou le roman policier sont définis par diverses restrictions qui intéressent soit le plan de lexpression (par exemple le roman par lettres, le traité versifié), soit celui du signifié. Elles doivent ętre spécifiées selon les composantes mises en jeu : thématique et dialectique pour le roman policier, par exemple, dialogique pour les romans fantastiques, tactique pour les sonnets liminaires, etc.
(v) Létude des genres nest quune étape dans un processus de caractérisation, et elle revęt son plus grand intéręt quand elle permet de percevoir la singularité des textes de męme que les normes sociales constituent le fond qui permet de comprendre les actions individuelles [4].
Sil est possible, pour des applications, de privilégier le discours (ex. politique) ou le champ générique comme niveau danalyse, au plan de la théorie linguistique, dans la mesure oų nous cherchons ā caractériser la textualité, cest le genre et non le discours qui la détermine. Un discours regroupe des textes ā structure trop hétéroclite pour cet objectif : comment et pourquoi comparer, au sein du discours littéraire la maxime et lépopée ? En revanche, au sein dun champ générique, les genres sont en compétition et en co-évolution (cf. sur lévolution comparée du roman sérieux, du roman policier et du polar, Beauvisage, 2001) [BEA 01].
--- 551 ---
1.2.
Problčmes et perspectives en linguistique de corpus
![]()
La demande sociale dune théorie opératoire des genres est croissante, aussi bien pour la linguistique de corpus que pour laccčs aux banques textuelles. Létude des corpus en situation suggčre que le lexique, la morphosyntaxe (cf. infra , 3), voire la maničre dont se posent les problčmes sémantiques de l'ambiguīté et de l'implicite, tout cela varie avec les genres. Les systčmes danalyse et de génération doivent tenir compte de ces spécificités, si bien que les projets de systčmes universels semblent ainsi irréalistes, linguistiquement parlant [5]. Pour parvenir ā des traitements automatiques efficaces de corpus, il convient de spécifier les fonctionnements propres aux différents genres. Dans un corpus homogčne, connaître la structure du genre peut permettre de simplifier les traitements : ainsi, certaines parties des textes seront par exemple éliminées, pour constituer des sous-corpus pertinents pour une tâche donnée. En outre, la connaissance des genres peut s'avérer utile pour la recherche d'informations : dans les articles scientifiques, par exemple, la formulation des hypothčses est ā rechercher dans des parties bien définies de la structure du texte, les discussions théoriques aussi. Cependant, l'article expérimental n'a pas la męme structure que l'article théorique, etc. Aussi une description fine est-elle un préalable nécessaire.
Si lon convient des insuffisances d'une linguistique fondée sur des exemples, pour progresser dans létude des genres et de la nature des normes linguistiques qui les structurent, il faut unifier létude de la langue et létude de la Ģ parole ģ (au sens saussurien du terme), en étudiant des usages par une linguistique de corpus [BAR 00]. L'un des pionniers de cette démarche est D. Biber [6]. Le profilage de textes proposé par Habert et ses collaborateurs sen inspire pour proposer Ģun bilan quantitatif fondé sur des indices linguistiquesģ [HAB 00]. Le profilage commence par une Ģneutralisation des genresģ, pour faire émerger des configurations textuelles indépendantes des genres et des discours. Ce choix suscite deux questions en débat.
--- 552 ---
a) Habert et coll. affirment : Ģ nous visons ā éliminer le contexte situationnel et historique des textes ģ (1999) ; cependant, sans faire ā proprement parler partie de ce contexte, les genres varient tout de męme avec lui. Si le genre constitue une variable qui véhicule des contraintes globales et locales, négliger cette variable peut obscurcir la compréhension des phénomčnes. Par exemple, dans ses travaux sur la comparaison entre les discours de De Gaulle et de Mitterand, Dominique Labbé a peut-ętre sous-estimé la disparité entre les discours écrits (dominants chez de Gaulle) et les entretiens oraux (dominants chez Mitterand), ce qui conduit sans doute ā attribuer aux auteurs des différences qui relčvent des genres, voire ā négliger lopposition entre lécrit oralisé des discours de De Gaulle et loral transcrit des entretiens de Mitterand [7].
b) De fait, aucune typologie des textes fondée sur des critčres définis indépendamment des genres (comme oral vs écrit, public vs privé, etc.) na permis disoler des genres : par exemple, les tentatives de classification automatique conduites par Biber ont conclu ā des variations trčs importantes selon les corpus, mais sans isoler des genres, ce qui nétait dailleurs pas son propos. Certains auteurs considčrent quun genre nest quun type parmi dautres, voire un genre de type . La question sera tranchée quand on aura produit des types de textes stables et cohérents, indépendants de toute connaissance préalable des genres et des discours, qui ne recoupent ni les genres ni les discours, et qui aient une pertinence théorique et pratique. Alors le défi est lancé , la typologie des textes sera devenue indépendante de la théorie des genres.
c) Le statut des configurations obtenues par Ģ induction ģ appelle des précisions, car les normes linguistiques varient tout ā la fois selon les discours (qui correspondent ā des types de pratiques), les genres (qui correspondent ā des situations typiques), et enfin les styles. Par ailleurs, en raison de la détermination du global sur le local, les variations sont déterminées par les discours, les genres et les styles individuels, et elles ne peuvent ętre ordonnées et comprises que si lon ménage, dčs le choix du corpus, les conditions de cette compréhension.
Cependant, nous ne privilégions pas exclusivement une démarche Ģ déductive ģ : la linguistique de corpus qui se développe actuellement doit permettre de refonder ou daffiner les distinctions intuitives et empiriques entre genres . En effet, les variations morphosyntaxiques selon les genres sont notables. Par exemple, les textes littéraires contiennent significativement moins de passifs que les autres ; la position de ladjectif, la nature des déterminants, des pronoms et des temps, lusage du nombre varient aussi notablement. Ou encore, dans le domaine technique męme, les variations sont importantes entre un manuel et une brochure commerciale : au premier, les acronymes, les impératifs, les ellipses de déterminants ; au second, les phrases longues, les pronoms nombreux, etc. Bref, létude des normes linguistiques
--- 553 ---
complčte
utilement celle des
rčgles
et permettra sans doute de préciser leurs conditions
dapplication [8].
Remarque
. Derričre lopposition fort approximative entre démarche
inductive et démarche déductive se dessine
une opposition nette entre deux conceptions du texte :
la conception ordinaire en informatique linguistique en fait
une chaîne de caractčres, sans plus. Cependant,
la chaîne de caractčres nest accessible que
par restriction : par exemple, si lindication
roman
est portée sur un
ouvrage, elle ne fait pas partie du texte (au sens restreint)
mais bel et bien de luvre dailleurs les auteurs nont
pas manqué den jouer. Ainsi, selon la conception
philologique que nous partageons, le texte ne se réduit
pas ā une chaîne de caractčres, mais
doit ętre considéré comme une uvre,
au sens général du terme, qui ne se limite pas aux
pratiques artistiques. Ce statut dérive de laction
pratique qui la produit et configuré. En dautres termes,
les pratiques que reflčtent les genres déterminent
les modes génétique, mimétique et herméneutique
des textes, et elles commandent ainsi les Ģ traitements
des chaînes de caractčres ģ. En dautres
termes, les variables recueillies dans len-tęte du
texte (auteur, date, genre, etc.) sont des
variables
globales
qui déterminent les
variables
locales
étiquetant les unités dans le corps du texte.
Lapproche sémantique globale part de catégories Ģ intuitives ģ de genre qui caractérisent globalement le texte, au męme titre que la date ou lauteur, et elle doit ętre combinée avec lapproche empirique et contrôlée par elle.
Si l'approche empirique Ģ inductive ģ peut aider ā mettre en évidence des différences entre textes, nous n'attendons pas qu'elle définisse les genres textuels. Nous considérons en effet que les genres sont définis par linteraction normée de composantes textuelles : nous jouons alors de difficulté, puisque les traits linguistiques dont nous disposons pour conduire létude présentée ici sont issus dune analyse morphosyntaxique au palier de la phrase qui ne tient évidemment pas compte des contraintes des paliers supérieurs.
Pour les variables morphosyntaxiques dont nous disposons, nous chercherons s'il existe des différences significatives au sein de chaque niveau. Ā chacun correspond, nous le verrons, une spécificité morphosyntaxique propre, car les variables discriminantes ā un niveau ne le sont pas nécessairement aux autres. D'autre part, nous chercherons ā qualifier les groupements de variables corrélées dans notre corpus ; et comme les corrélations observées restent relatives au corpus de travail, nous ferons varier sa composition pour explorer les variations de facteurs selon les genres [9].
Nous chercherons enfin si une classification descendante est confirmée par une classification ascendante, de maničre ā parvenir ā une classification objectivée. Si les classes formées par la classification automatique recoupent les genres prédéfinis, cela confirmera le caractčre déterminant des genres sur les usages linguistiques. Les classes qui sécartent des genres prédéfinis seront étudiées pour enrichir ou rectifier la
--- 554 ---
définition des genres, en gardant ā l'esprit que le statut des classes formées automatiquement reste indéfini a priori , dans lattente dune qualification sémantique.
Tout corpus reflčte le point de vue qui a présidé ā sa constitution : le nôtre a été réuni pour constituer un échantillon représentatif des usages linguistiques écrits du franįais moderne, en premier lieu pour élaborer un correcteur orthographique et grammatical. Il compte ainsi des centaines de romans policiers, censés rendre mieux compte dusages contemporains que les romans Ģ sérieux ģ. En général, un corpus Ģ de langue ģ nest pas homogčne, et celui-ci ne fait pas exception : il nest pas partout au męme niveau de variété, dhomogénéité ou de représentativité (ex. les textes scientifiques ou techniques). Cependant, il résulte dun objectif explicite et en tire une cohérence légitime [10]. Nous lavons légčrement restreint pour notre propos, en éliminant les discours, champs génériques ou genres trop peu représentés, comme le discours religieux, représenté par une seule uvre de Bossuet.
Le corpus compte néanmoins 2541 ouvrages, soit 164 millions de mots et 27 millions dautres signes (ponctuations, alinéas [11]). Il est donc 300 fois plus étendu que celui dont Biber tire ses conclusions (481.000 mots) ; en outre, il comprend uniquement des textes intégraux et non des extraits. Il se répartit sur quatre discours inégalement représentés : scientifique, juridique, essayiste, littéraire. Le discours juridique se divise en rapports, codes et lois. Le discours scientifique et technique reste divisé par domaines, informatique, linguistique, médecine, physique et mathématiques, sciences naturelles, autres : cette division, discutable, na pas été utilisée ; de męme pour les essais qui ressortissent ā diverses disciplines, histoire, politique, critique
--- 555 ---
artistique, etc. Le discours littéraire se divise en trois champs génériques : récits, poésie et théâtre. Parmi les récits, on distingue les romans Ģ sérieux ģ, les romans policiers, les contes, les nouvelles, les récits de voyage et les mémoires ; au sein de la poésie, la poésie lyrique (en vers, en prose) et les fables ; au sein du théâtre, la comédie, le drame et la tragédie. Quantitativement, le corpus se présente ainsi :
|
Discours |
Code |
Nombre |
Pourcent. |
|
Essais |
E |
246 |
10,5 |
|
Scientifique |
H |
66 |
1,8 |
|
Juridique |
J |
155 |
6,1 |
|
Littéraire |
L |
2074 |
81,6 |
|
Champs génériques littér. |
|
|
|
|
Poésie |
P |
125 |
4,9 |
|
Théâtre |
T |
225 |
8,9 |
|
Genres narratifs |
R |
1724 |
67,8 |
|
Genres |
|
|
|
|
Essais philosophiques |
E_F |
83 |
3,3 |
|
Essais historiques |
E_H |
44 |
1,7 |
|
Essais littéraires |
E_L |
40 |
1,6 |
|
Ess. politiques et sociaux |
E_P |
98 |
3,9 |
|
Scientifique |
|
|
|
|
Divers |
H_D |
12 |
0,5 |
|
Informatique |
H_I |
4 |
0,2 |
|
Linguistique |
H_L |
3 |
0,1 |
|
Médecine |
H_M |
7 |
0,3 |
|
Physique |
H_P |
15 |
0,6 |
|
Sciences Naturelles |
H_S |
5 |
0,2 |
|
Juridique |
|
|
|
|
Codes |
J_C |
11 |
0,4 |
|
Lois |
J_L |
32 |
1,3 |
|
Rapports |
J_R |
112 |
4,4 |
|
Poésie |
|
|
|
|
P. lyrique |
P_L |
97 |
3,8 |
|
P. en prose |
P_P |
28 |
1,1 |
|
Genres narratifs |
|
|
|
|
Contes |
R_C |
49 |
1,9 |
|
Mémoires |
R_M |
88 |
3,5 |
|
Nouvelles |
R_N |
51 |
2 |
|
Roman policier |
R_P |
521 |
20,5 |
|
Roman Ģ sérieux ģ |
R_S |
989 |
38,9 |
|
Récits de voyage |
R_V |
26 |
1,0 |
|
Théâtre |
|
|
|
|
Comédie |
T_C |
142 |
5,6 |
|
Drame et Tragédie |
T_D |
83 |
3,3 |
--- 556 ---
Le corpus comporte 49 % d'ouvrages de la seconde moitié du XX e sičcle, 13 % de la premičre moitié, 13 % de la premičre moitié du XIX e et 14 % de la seconde moitié, 5% de la seconde moitié du XVIII e ; le reste appartient aux XVII e et XVI e sičcles.
Lattribution de genre résulte dune hypothčse initiale qui sappuie sur des indices divers : éditeur spécialisé, auteur, indication explicite, etc. ; aucun nest nécessaire ni suffisant, mais pris ensemble ils sont généralement indiscutables. Elle se fait sans difficulté dans tous les discours non littéraires, en droit, par exemple. Elle reste facile pour les champs génériques : ainsi, il est aisé de différencier le théâtre. Les incertitudes qui demeurent parfois ne sont pas irrémédiables ; des traitements de classification automatique permettent dailleurs de repérer les mauvais classements, en attirant lattention sur les textes atypiques dans une catégorie, qui peuvent se révéler mal classés : ainsi, une inadvertance avait placé Les Rois Maudits de Druon parmi les essais historiques, alors que la classification automatique la pertinemment placé parmi les romans.
2.2.
Les variables
![]()
L'ensemble des textes du corpus a été étiqueté par lanalyseur morphosyntaxique CORDIAL de la société Synapse-Développement [12]. Catégorisé, le corpus compte un total de 187 millions détiquettes, plus les variables non ponctuelles (relatives aux phrases, etc.), soit environ 200 millions. Pour chacune des 251 variables, on calcule pour chaque texte les moyennes, les minima et les maxima : soit environ 1. 900.000 nombres.
Chaque texte est ainsi décrit par les variables suivantes : (i) Variables bibliographiques : titre de l'ouvrage, nom d'auteur, date de la premičre publication. (ii) Variables quantitatives : la taille en Ko, des chiffres absolus concernant quelques grandes catégories morphosyntaxiques, le pourcentage de chaque catégorie par rapport ā la catégorie superordonnée (par ex : pourcentage d'articles définis sur lensemble des déterminants). (iii) Enfin, pour chaque catégorie morphosyntaxique, on dispose des moyennes par ouvrage (chaque ouvrage a le męme poids dans la moyenne) ; des moyennes par taille (le poids de chaque ouvrage est proportionnel ā
--- 557 ---
sa taille) ; enfin, des valeurs minimale et maximale de chaque variable par discours, champ générique et genre, ce qui permet de mesurer lempan de variation.
Par rapport ā celles que retient Biber, les variables sont trois fois plus nombreuses. Certaines catégories sont communes : temps des verbes, personnes, pourcentages relatifs sur les parties du discours (ex. pourcentage dadjectifs parmi les mots lexicaux), et sur les types de propositions (ex. pourcentage de relatives). En revanche, nous ne disposons gučre d'étiquettes concernant les intégrations de syntagmes ou de propositions : types de relatives, subordonnées de cause, modaux, passifs, types de questions, nominalisations [13]. Les principales classes de catégories dont nous disposons sont les suivantes : les ponctčmes (que complčte le décompte des dialogues, des paragraphes, des phrases, des incises, des propositions) ; les parties du discours et les pourcentages des sous-catégories pour chacune d'elles ; les personnes des verbes, des adjectifs possessifs et pronoms possessifs et personnels ; les temps verbaux ; les types de verbes, transitifs directs ou indirects, avec COD obligatoire, types de sujet ou de COD (abstrait / concret, animal, animé) etc. ; les types de noms : nom propre (humain, prénom, géographique, autre), nom commun (abstrait ou concret, animal, animé, humain, humanoīde), % de noms de lieu, de temps, de profession, noms composés, noms épithčtes, de noms appartenant ā un groupe nominal ; les types de propositions (principales, coordonnées, subordonnées et les types de ces derničres) ; enfin, les types de compléments.
Le statut de ces variables est divers, et leur interprétation doit tenir compte de cette diversité : certaines, comme les pronoms, correspondent ā des signes ("je, tu, il") dont linterprétation demanderait l'analyse des composantes textuelles au niveau méso-sémantique (de la proposition au paragraphe) ; d'autres sont des indices de la complexité de la phrase, de la proposition, du syntagme; enfin, certaines peuvent ętre rattachées ā des indices thématiques (humain, animé...), d'autres au registre de langue. La diversité des variables est un moyen dobjectivation : les corrélations entre variables en principe indépendantes, par exemple les temps verbaux et les ponctuations, permettent de mettre en évidence des relations insoupįonnées [14]. Les données statistiques dont nous partons correspondent au décompte des scores de chaque variable pour chacun des ouvrages, considéré comme un ensemble dun seul tenant. Les "individus" (au sens statistique) ā décrire et ā classer sont les ouvrages, ou les groupements douvrages (ex. les genres, champs génériques et discours). Ils individus sont décrits ā l'aide des pourcentages calculés ā partir des étiquettes.
![]()
NOTES
[1] page 548 : Lexistence de genres transdiscursifs reste douteuse, car le voisinage dautres genres ou, sil sagit de genres inclus, dautres contextes dinclusion suffit ā les modifier : ainsi, un proverbe na pas le męme sens dans un discours ludique ou dans un discours juridique ; la lettre commerciale na presque rien de commun avec la lettre personnelle du discours privé, etc. Puisque les genres sont spécifiques aux discours, un texte technique, par exemple, ne peut ętre assimilé ā un texte scientifique. Męme dans des discours aussi proches que les discours scientifiques, les genres ne sont pas exactement comparables, car chaque discipline a ses traditions et ses normes : par exemple, un traité de physique nobéit pas aux męmes normes quun traité de linguistique.
[2] page 548 : Un champ générique est un groupe de genres qui contrastent voire rivalisent dans un champ pratique : par exemple, au sein du discours littéraire, ā lépoque classique, le champ générique du théâtre se divisait en comédie et tragédie.
[3] page 548 : La question des sous-genres est délicate : en fait, indépendamment des sous-corpus définis pour une application, les sous-genres sont des lignées génériques, cest-ā-dire des séries de textes écrits les uns ā partir des autres (cf. Rastier et Pincemin, 1999 [RAS 99]). Cest évidemment dans les genres littéraires que les lignées sont les plus apparentes ; elles évoluent par ruptures, et une étude diachronique doit en tenir compte (cf. Beauvisage, 2001[BEA 01]).
[4] page 550 : Sur la sémantique des genres, cf. Rastier, 1989, I, ch. III ; 2001, ch. 8.[RAS 01] Les genres sont des moyens (i) de la médiation symbolique (au sens proposé par Clifford Geertz, 1972 [GEE 72]) qui articule lindividuel et le social, et (ii) de la médiation sémiotique, celle qui articule le physique et le représentationnel. Traitant des genres au sein de la linguistique, la poétique généralisée engage dans son ensemble la médiation symbolique : le genre concilie laction individuelle et la norme sociale oų elle prend place.
[5] page 551 : Ils reposent en effet sur le préjugé normatif que la langue est homogčne et identique ā elle-męme dans tous les textes et dans toutes les situations de communication.
[6] page 551 : Son approche a été parfaitement résumée ainsi par Habert et al. : ĢL'optique, inductive, consiste ā faire émerger a posteriori les types de textes considérés comme des agglomérats fonctionnellement cohérents de traits linguistiques grâce ā un traitement statistique multidimensionnel de textes annotés [ ] Biber examine les corrélations entre 67 traits linguistiques dans les 1.000 premiers mots de 481 textes d'anglais contemporain écrit et oral. Les traits étudiés ressortissent ā 16 catégories distinctes (marqueurs de temps et d'aspect, questions, passifs, modaux...). Ils sont identifiés automatiquement sur la base d'un premier étiquetage morpho-syntaxique. La statistique multidimensionnelle permet d'obtenir des pôles multiples, positifs et négatifs, correspondant ā des constellations de traits linguistiques corrélés. Ces pôles constituent deux ā deux des dimensions textuelles. Chaque texte, par son emploi des traits linguistiques retenus, se situe en un point déterminé de l'espace ā n dimensions issu de l'analyse. Les techniques de classification automatique permettent alors de regrouper les textes en fonction de leurs coordonnées sur ces dimensions. Les types de textes qui en résultent ne recoupent directement ni les "genres" des données de départ ni les registres intuitivement distingués ģ. (Habert et coll., 2000)[HAB 00].
[7] page 552 : Ces travaux nont malheureusement pas encore donné lieu ā une publication synthétique ; voir cependant Labbé, 2000 [LAB 00].
[8] page 553 : Les rčgles ne sont peut-ętre que des normes réifiées parce quelles évoluent lentement.
[9] page 553 : Dans cette étude, ce point ne sera pas développé ; il fait lobjet de travaux en cours.
[10] page 554 : La notion męme de corpus doit ętre affinée, car un corpus nest pas un ensemble de données, encore moins une collection sans principe défini parée du nom de ressource linguistique : comme toujours dans les sciences de la culture, les données sont faites de ce que lon se donne ; or le point de vue qui préside ā la constitution dun corpus conditionne naturellement les recherches ultérieures. Si la représentativité dun corpus na rien dobjectif et dépend du type dexploitation prévue, son homogénéité dépend aussi du type de recherche. En rčgle générale, les recherches en sémantique des textes doivent porter sur des corpus aussi homogčnes que possible pour ce qui concerne leur genre, ou du moins leur discours. En effet, un texte peut Ģ perdre ģ du sens, sil est placé parmi des textes oiseux, car la comparaison avec eux ne permet pas de sélectionner doppositions pertinentes. La recommandation dhomogénéité na au demeurant rien dexclusif, et lun des objectifs de la critique philologique peut ętre aussi de problématiser les variations du corpus (cf. Rastier, 2001).
[11] page 554 : Extrait dun corpus total de 500 millions de mots et 80 millions de ponctuations (y compris les retours chariot servant de fin de paragraphe), notre corpus en représente environ un tiers. Sil comporte les indications élémentaires den-tęte (titre, auteur, date), il souffre de quelques insuffisances philologiques (concernant le péritexte, comme les préfaces, par exemple) qui restent cependant sans grande importance pour notre propos.
[12]
page 556 :
Aucun analyseur nest parfait ; celui-ci a cependant
obtenu des résultats satisfaisants aux tests
comparatifs de correction orthographique et
grammaticale : sur 17 tests, il est arrivé 15
fois en tęte. Nous avons naturellement évalué
ses taux derreurs : bien entendu inégaux,
parfois assez élevés dans certains cas
décole (confusions pour les verbes du
3
e
groupe entre le présent et le passé simple,
ou pour les présents de lindicatif et du subjeonctifs),
ils ne sont pas assez forts pour remettre en cause les
variations constatées, tant dans lapproche univariée
que dans lapproche multivariée.
Par rapport
aux versions du commerce, la version utilisée
a subi ā notre demande des modifications. La derničre
version de Cordial intčgre dailleurs notre
classification des genres, et permet de préciser, ā
partir dun extrait de texte, de quel genre répertorié
dans le corpus il se rapproche le plus.
[13] page 557 : Le corpus de Biber a été étiqueté manuellement, et comporte ainsi des indications que dans létat de lart les analyseurs morphosyntaxiques ne fournissent pas encore.
[14] page 557 : Ainsi, par exemple, la corrélation entre le point-virgule et limparfait du subjonctif ne sexplique pas seulement par le niveau de langue ; ces deux étiquettes témoignent peut-ętre, avec des moyens différents, dune męme position énonciative de distance critique, qui corrélerait la pause du point-virgule, interprétée comme un suspens, voire un recul, avec la valeur hypothétique du subjonctif.
OUVRAGES CITÉS :
[BAR 00] Barlow, M. & Kemmer, S, éds., Usage-based models of language , CSLI Publications, Standford, 2000.
[BEA 01] Beauvisage, T., Ģ Exploiter des données morphosyntaxiques pour létude statistique des genres Application au roman policier ģ, 2001, TAL, 16.
[BIB 88] Biber, D., Variation across Speech and Writing . Cambridge, Cambridge University Press, 1988.
[BIB 92] Biber, D., Ģ On the complexity of Discourse Complexity ; a multidimensional Analysis ģ , Discourse Processes , 15, 1992, p. 133-163.
[BIB 93] Biber, D., Ģ Using register-diversified corpora for general language studies ģ . Computational Linguistics , vol. 19, 2, 1993, p.243-258.
[BIB 00a] Biber, D., Ģ Investigating language use through corpus-based analyses of association patterns ģ, in M. Barlow & S. Kemmer (éds) : Usage-based models of language , CSLI Publications, Stanford, 2000.
[BIB 00b] Biber, D., Johanson, S., Leech, G., Conrad, S., Finegan, E., The Longman grammar of spoken and written English . Londres, Longman, 2000.
[GEE 72] Geertz, C., The Interpretation of Cultures , New York, Basic Books, 1972.
[HAB 00] Habert, B. et coll., Ģ Profilage de textes : cadre de travail et expérience ģ, Actes des 5čmes JADT . 2000.
[ILL 99] Illouz G., Habert B., Fleury S., Folch H., Heiden S., Lafon P., Ģ Maîtriser les déluges de données hétérogčnes ģ, Actes TALN 1999 , Cargčse, 1999.
[LAB 00] Labbé, D., Ģ La France, chez de Gaulle et Mitterand ģ, in Des mots en liberté Mélanges Maurice Tournier , Saint-Cloud, ENS Editions, 2000, pp. 183-193.
[RAS 89] Rastier, F., Sens et textualité , Paris, Hachette, 1989.
[RAS 99] Rastier, F., & Pincemin, B., Ģ Des genres ā l'intertexte ģ, Cahiers de Praxématique , n°23, 1999, p. 90-111.
[RAS 01] Rastier, F., Arts et sciences du texte , Paris, PUF, 2001.