PVI :PROTH»SE VOCALE INTELLIGENTE
Pascal Vaillant
1. Introduction : architecture du systËme
PVI
2. Le module d'analyse sÈmantique
3. Le module de transfert lexical
4. Le module de gÈnÈration
5. …valuation et discussion
6. Conclusion
PVI : SystËme de traduction d'icÙnes en
langue ![]()
1. Introduction : architecture du systËme
PVI ![]()
Ce chapitre [*] dÈcrit la conception et le fonctionnement du programme de comprÈhension de sÈquences d'icÙnes et de gÈnÈration de phrases en franÁais mis en oeuvre dans le systËme PVI. Le systËme complet intËgre ce programme et une interface graphique sophistiquÈe conÁue pour lui dans une architecture spÈcifique que nous dÈcrivons ici briËvement. Le lecteur se reportera, pour une description plus particuliËre de l'interface de PVI, au rapport de MichaÎl Checler [1995].
Le systËme PVI est conÁu pour fonctionner sur un ordinateur AppleTM de type Macintosh, sous Multifinder, avec un systËme d'exploitation AppleOS version 7, muni des extensions AppleEvents (en standard dans les versions 7.5 et ultÈrieures d'AppleOS) et QuickTime. Il requiert une configuration de 8 Mo de mÈmoire vive (il en consomme 7 au total : 4 Mo pour l'interface et 3 Mo pour le programme dÈcrit ici).
L'ordinateur doit Ítre Ègalement muni d'un systËme de synthËse vocale, qui peut Ítre matÈriel (carte de synthËse) ou logiciel (programme de synthËse compatible avec l'architecture Apple Speech Manager).
Le principe de fonctionnement en est la dÈsignation de symboles iconiques disposÈs sur l'Ècran, puis leur conversion en phrases franÁaises, et l'Ènonciation vocale de celles-ci par un programme de synthËse vocale artificielle.
Le systËme PVI comprend le programme de conversion icÙnes-phrases et le programme d'interface graphique. Il ne comprend pas le systËme de synthËse vocale.
Le module linguistique nÈcessite un environnement d'exÈcution Prolog II+ pour fonctionner, tandis que l'IHM est un programme exÈcutable autonome.
|
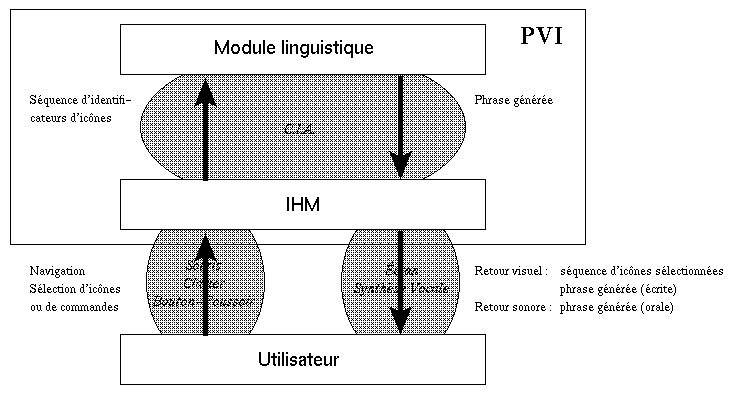
La figure 1 prÈsente une vision gÈnÈrale des interfaces du systËme PVI.
Des dÈtails sur le fonctionnement pratique du systËme peuvent Ítre trouvÈs dans la notice d'utilisation [Vaillant 1995].
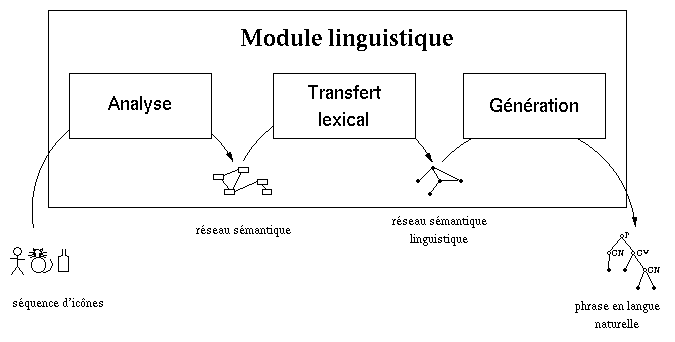
Le module linguistique, auquel est consacrÈ cette description, est lui-mÍme conÁu en trois modules qui correspondent aux grandes Ètapes de traitement du message de l'utilisateur : l'analyse, le transfert et la gÈnÈration. La premiËre fournit une interprÈtation de la sÈquence d'icÙnes sous la forme d'un rÈseau sÈmantique ; la seconde adapte ce rÈseau sÈmantique ý un traitement linguistique ; la troisiËme construit un message en langue naturelle ý partir du rÈseau sÈmantique linguistique (fig. 2).
|
| ---> | Dans la suite, les identificateurs de fichier du type Fichier.p2 dÈsigneront des fichiers sources Prolog , et les identificateurs de rËgles du type regle/3 dÈsigneront des rËgles Prolog et leur aritÈ. |
|---|
2. Le module d'analyse sÈmantique
![]()
Le module d'analyse prend en entrÈe une sÈquence d'identificateurs d'icÙnes, et la convertit, sans utiliser d'information grammaticale, en une reprÈsentation du sens.
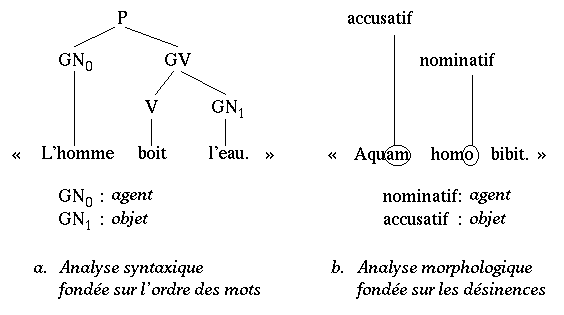
Le principe de base de l'analyse est, ici comme partout, de reconstituer les relations sÈmantiques entre prÈdicats et attributs pour aboutir ý une reprÈsentation du sens o˘ chaque agent se voie attribuer son rÙle casuel. Ainsi dans HOMME / EAU / BOIRE, on doit retrouver l'information [BOIRE : agent =HOMME, objet =EAU]. Toutefois, ce systËme postule qu'il ne peut compter ni sur l'ordre des mots (fig. 3.a), ni sur une information morphologique (fig. 3.b), pour attribuer ´ ý coup s˚r ª les rÙles casuels.
|
C'est pourquoi l'analyse doit se fonder ici sur des informations de nature sÈmantique : une sorte de sens commun modÈlisÈ informatiquement qui permette de reconnaÓtre en ´ homme ª l'agent, et en ´ eau ª l'objet, de l'action de boire.
L'ensemble de ces informations sont regroupÈes dans un lexique sÈmantique des icÙnes reconnues par l'application. La modÈlisation du contenu s'inspire, dans sa forme et dans sa terminologie, des travaux de Rastier [1987; 1994] sur la langue : nous en avons transposÈ une partie sur le langage d'icÙnes.
Afin d'Èviter les dÈrives traditionnellement liÈes ý l'organisation du lexique autour d'une ontologie a priori - ý savoir, l'inadaptation de la connaissance modÈlisÈe (insuffisante ou redondante) avec les besoins de l'application -, le contenu sÈmantique pertinent, considÈrÈ comme un objet purement linguistique, a ÈtÈ extrait d'un corpus recueilli auprËs d'enfants handicapÈs du Centre de Kerpape.
La mÈthodologie thÈorique permettant de dÈcrire la sÈmantique des symboles de l'application en se fondant uniquement sur le corpus, et non sur une connaissance du monde dÈfinie ´ de l'extÈrieur ª, est celle dÈcrite par Hjelmslev [1968]. Une dÈcomposition systÈmatique d'Èchantillons suffisants d'un systËme de signes devrait ainsi permettre d'en dÈcrire formellement la structure. Dans la pratique, nous avons fait intervenir notre connaissance ´ naturelle ª lors de l'analyse du corpus pour constituer les catÈgories ; cette intervention est lÈgitime dans le cas d'un langage sans syntaxe. Le fait de se fonder sur le corpus prÈserve de toute faÁon les exigences d'exhaustivitÈ et de description pertinente des traits spÈcifiques.
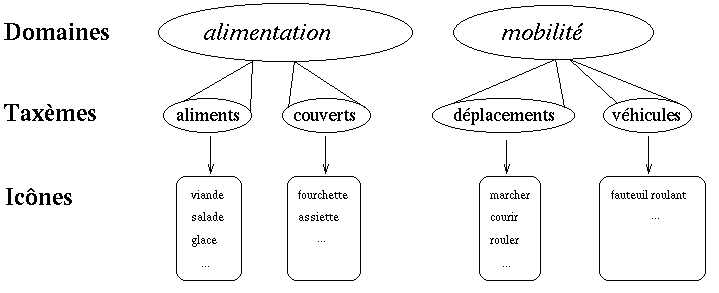
Le dictionnaire ainsi conÁu comprend trois niveaux (fig. 4) :
|
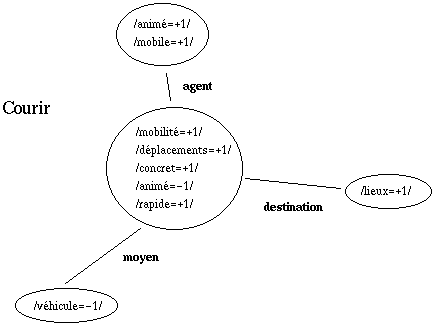
Le contenu est lui-mÍme modÈlisÈ sous la forme de sËmes , ou traits sÈmantiques , ÈlÈments de sens atomiques reprÈsentant des diffÈrences minimales pertinentes. Une icÙne possËde ainsi trois niveaux de sËmes : au niveau macrogÈnÈrique tout d'abord, les sËmes d' ´ Ètiquetage ª du domaine et du taxËme (ils sont au nombre de deux) ; au niveau microgÈnÈrique, les sËmes qui reprÈsentent le contenu commun ý toutes les icÙnes du mÍme taxËme ; enfin au niveau spÈcifique, les sËmes qui reprÈsentent le contenu propre de l'icÙne, par diffÈrences avec celui des icÙnes du mÍme taxËme.
Il existe des sËmes de deux sortes : les sËmes intrinsËques , qui reprÈsentent le contenu ´ propre ª de l'icÙne, sans la considÈrer en relation avec aucune autre, et les sËmes extrinsËques , ou traits de sÈlection , qui reprÈsentent les conditions que les icÙnes de nature prÈdicative imposent ý leurs Èventuels actants. Les premiers sont des attributs simples, gÈnÈralement bivaluÈs (+1 ou -1 selon qu'ils sont prÈsents ou absents du noyau de sens) ; les seconds sont des attributs attachÈs ý un rÙle casuel particulier. Ainsi <canin,+1> est-il un sËme intrinsËque pour la dÈfinition de " chien ", alors que <agent,<canin,+1>> est un sËme extrinsËque pour la dÈfinition d' " aboyer ".
Les sËmes extrinsËques font partie de la dÈfinition du sens d'un concept aussi bien que les sËmes intrinsËques [1]. Ils sont simplement rattachÈs ý un rÙle casuel, donc conditionnent les relations sÈmantiques qui peuvent surgir entre ce concept et son contexte - alors que les sËmes intrinsËques concernent le coeur du concept.
Selon l'icÙne considÈrÈe, on pourra donc soit n'avoir que des sËmes intrinsËques, soit n'avoir que des sËmes extrinsËques, soit avoir les deux. Un exemple reprÈsentatif, correspondant ý la structure du contenu de l'icÙne " courir ", est donnÈ dans le tableau 1.
| traits sÈmantiques : | intrinsËques | extrinsËques | ||||
|---|---|---|---|---|---|---|
| domaine | // mobilitÈ // | |||||
| taxËme | ' dÈplacement ' |
|
|
|||
| icÙne | ' courir ' |
|
|
|||
Cette reprÈsentation, distribuÈe en sËmes gÈnÈriques et sËmes spÈcifiques, est Èquivalente ý la reprÈsentation ´ compilÈe ª exposÈe fig. 5.
|
Tous ces ÈlÈments sont convoquÈs lors du calcul d' ´ affinitÈ sÈmantique ª en quoi consiste l'analyse (cf. ß 2.2).
Une petite doxa des subdivisions fondamentales en genres et en espËces doit Ítre reprÈsentÈe dans le dictionnaire pour prendre en compte les phÈnomËnes de comprÈhension, ou implications naturelles entre traits sÈmantiques fondamentaux, sans allonger exagÈrÈment les listes de sËmes (nous ne faisons pas ici de suppositions ontologiques fortes, mais nous mettons en facteur, pour des raisons d'Èconomie, des affÈrences gÈnÈralement admises dans les corpus considÈrÈs).
Le mÈcanisme d'analyse est en effet conÁu de telle sorte qu'il essaye de trouver les actants ´ les mieux adaptÈs ª pour chaque rÙle casuel possible. On cherche donc ý disposer dans le lexique d'informations prÈcises sur les actants idÈaux attendus par un prÈdicat, de sorte que cette recherche du mieux adaptÈ soit effectivement discriminante. Il est nÈanmoins nÈcessaire que des candidats partageant un assez grand nombre de traits gÈnÈriques en commun avec le candidat idÈal soient considÈrÈs comme mieux adaptÈs que ceux n'en partageant pas ; ainsi un animal peut-il Ítre considÈrÈ comme un ´ remplaÁant ª acceptable pour un humain comme agent d'un prÈdicat, alors qu'une notion abstraite, par exemple, ne l'est pas du tout et doit Ítre rejetÈe lors de l'analyse.
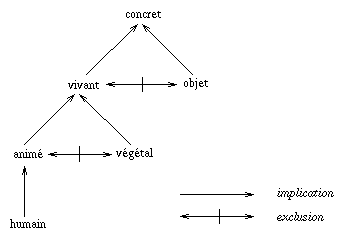
Or nous avons choisi, pour mÈnager une grande souplesse au modËle du lexique, et pour assurer sa pertinence dans un corpus particulier, de ne pas organiser celui-ci selon une taxonomie rigide (ß 2.1.1). Nous n'avons donc pas d' ´ arbre d'hÈritage ª universel qui permette, par simple examen de la filiation d'un concept en genres d'extension de plus en plus grande, de retrouver ce type d'information ; de savoir par exemple qu' /humain/ comprend /animÈ/.
Il n'est en outre pas judicieux, dans le modËle de lexique utilisÈ ici, de stocker au niveau de chaque rÙle casuel l'ensemble des traits sÈmantiques gÈnÈraux qui pourraient Èventuellement s'y appliquer (en notant par exemple, lorsqu'un prÈdicat a un sËme extrinsËque <agent,<humain,+1>>, qu'il a aussi les sËmes extrinsËques <agent,<animÈ,+1>>, <agent,<vivant,+1>>, <agent,<concret,+1>> ...) : ces sËmes ne seraient pas pertinents, mais seulement prÈsents pour l'exhaustivitÈ de la reprÈsentation.
Nous avons donc dÈfini un arbre d'hÈritage (fig. 6), sur des sËmes et non sur des concepts. Cet arbre dÈcrit une ´ ontologie ª primitive : il reprÈsente les liens de comprÈhension ou d'exclusion entre quelques sËmes trËs courants.
|
Lors de l'analyse, les sËmes ´ ascendants ª d'un sËme extrinsËque attachÈ ý une icÙne prÈdicative donnÈe, mÍme s'ils ne sont pas explicitement spÈcifiÈs, sont ainsi convoquÈs eux aussi lors du calcul. Pour que leur importance globale n'excËde pas, ý cause de leur nombre, celle des sËmes explicitement prÈsents dans la reprÈsentation lexicale, un coefficient constant appelÈ droits_de_succession leur est affectÈ.
Cette forme de reprÈsentation, qui consiste ý considÈrer l'hÈritage comme concernant les composants sÈmantiques primitifs et non les concepts, permet d'intÈgrer une ontologie au lexique sans pour autant considÈrer le lexique lui-mÍme comme une ontologie : le lexique n'est pas un arbre de Porphyre, et un mÍme sËme peut Ítre gÈnÈrique dans un taxËme donnÈ, spÈcifique dans un autre, tout en gardant sa propre dÈfinition.
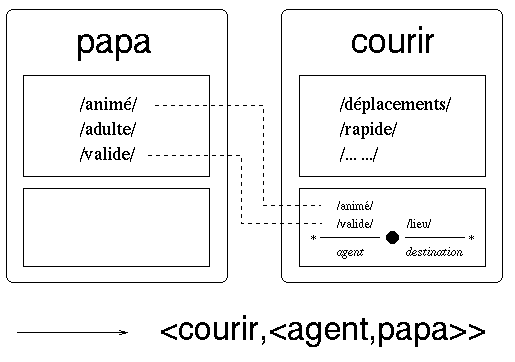
Nous avons exposÈ (ß 2.1.2) comment une certaine doxa, ou ´ connaissance naturelle ª reÁue du monde, modÈlisÈe dans le lexique, fournit les donnÈes de l'analyse sÈmantique. Cette connaissance porte essentiellement sur les relations qu'une icÙne peut lier avec une autre : il s'agit en effet des propriÈtÈs qu'une icÙne prÈdicative donnÈe i peut imposer ý ses actants c( i ) en les propageant le long de ses relations casuelles :
i --> c( i )
Il existe un second niveau de connaissance naturelle, celui des relations particuliËres que deux icÙnes peuvent lier par l'intermÈdiaire d'une troisiËme : il s'agit des propriÈtÈs qu'une icÙne prÈdicative i impose ý l'un de ses actants c2( i ) lorsqu'un autre de ses actants, c1( i ), possËde lui-mÍme des propriÈtÈs particuliËres :
c1( i ) --> c2( i )
Cette implication conditionnelle , o˘ le prÈdicat joue un rÙle de pivot entre deux types d'actants particuliers pouvant entrer conjointement en relation avec lui, doit Ègalement Ítre modÈlisÈe dans le lexique pour prendre en compte certains phÈnomËnes. Ainsi doit-on pouvoir prÈdire qu'un agent /carnivore/ pour le verbe " manger " renforce la plausibilitÈ d'un objet /animal/ (autrement improbable dans ce rÙle).
Cette sorte de connaissance est reprÈsentÈe par des ´ cadres ª, de la forme reprÈsentÈe fig. 7.
![[agent : +carnivore] <- MANGER -> [objet: +animaux]](cadresem.gif)
|
Ces cadres se superposent le cas ÈchÈant, lors de l'analyse, ý la structure prÈdicative de base de l'icÙne (fig. 5), pour former une structure du mÍme type, mais enrichie.
Dans certains cas, il est nÈcessaire de pouvoir gÈrer l'utilisation de la mÍme icÙne pour des emplois diffÈrents. Il ne s'agit pas vÈritablement d'homonymie, puisque les icÙnes de l'application constituent un systËme de signes artificiel o˘ celle-ci est a priori bannie, mais d'emploi du mÍme signifiant dans des taxËmes distincts. Ainsi l'icÙne reprÈsentant un tÈlÈphone peut-elle Ítre utilisÈe pour reprÈsenter l'objet " tÈlÈphone " (au sens de ´ poste tÈlÈphonique ª), dans le taxËme des appareils domestiques, autant que pour reprÈsenter l'action " tÈlÈphoner ", dans le taxËme des communications.
Ces doubles emplois apparaissent frÈquemment lors des premiers essais du programme, alors qu'ils n'avaient pas ÈtÈ prÈvus au dÈpart : on s'aperÁoit par exemple que l'utilisateur emploie spontanÈment l'icÙne " tÈlÈphone " au sens du verbe tÈlÈphoner, sans avoir subi d'apprentissage. On est donc amenÈ ý prÈvoir cet emploi tant il semble surgir naturellement.
| ---> | Ce type de dÈrivation n'a rien de surprenant comme on peut le voir ý l'oeuvre de faÁon systÈmatique dans la langue. Dans l'exemple donnÈ, il s'agit de dÈrivation mÈtonymique. Dans d'autres cas, il peut s'agir de variation d'aspect ou de structure casuelle d'un mÍme concept, ou mÍme simplement de changement de cas sÈmantique ( "table" dans le taxËme des meubles vs. "table" dans le taxËme des lieux - correspondant l'un ý l'accusatif, l'autre au locatif). |
|---|---|
| Les langues, nous le savons, possËdent des mÈcanismes morphologiques pour marquer ces dÈrivations (suffixation, prÈfixation). Le langage BLISS [Hehner 1980], langage d'idÈogrammes artificiel auquel on a songÈ ý adjoindre un systËme morphologique assez complet, en possËde aussi ; on pourrait donc imaginer une configuration BLISS de PVI, dans laquelle ces diffÈrents emplois seraient marquÈs au niveau du signifiant - encore que l'utilitÈ en soit contestable, car les utilisateurs handicapÈs ont l'habitude d'utiliser BLISS comme catalogue d'idÈogrammes, sans se soucier souvent de son systËme de dÈrivation par signes diacritiques. Dans la configuration implÈmentÈe en tout cas, ce n'est pas le cas. |
Nous avons donc tout simplement modÈlisÈ ces diffÈrents emplois en faisant correspondre ý un seul signifiant iconique plusieurs entrÈes du dictionnaire figurant dans des taxËmes diffÈrents, par exemple " tÈlÈphone1 " (poste tÈlÈphonique), " tÈlÈphone2 " (tÈlÈphoner) :
emplois(telephone,telephone2.telephone1.nil) ->;
Lors de l'analyse d'une sÈquence d'icÙnes, chaque icÙne est donc examinÈe pour voir si elle ne correspond pas ý plusieurs emplois. Si c'est le cas, la sÈquence de signifiants est convertie en autant de sÈquences de signifiÈs. C'est au bout du compte le plus haut score d'analyse qui dÈtermine quel emploi est pris en compte.
Le principe de base de l'analyse dans PVI est de reconstituer la structure sÈmantique du message en affectant de faÁon adÈquate les actants des prÈdicats. Dans une sÈquence d'icÙnes d'entrÈe, l'analyse commence donc par repÈrer les icÙnes prÈdicatives, c'est-ý-dire celles qui ont une structure casuelle implicite, et, pour chacune d'elles, recherche dans son contexte quelles sont les meilleures icÙnes candidates pour ´ remplir ª les rÙles casuels.
La question se ramËne donc ý celle de la dÈtermination de ces ´ meilleures ª candidates ; en d'autres mots, il est nÈcessaire de dÈfinir une grandeur, un ´ score ª de compatibilitÈ sÈmantique, ý l'aune duquel on dÈtermine la valeur des affectations d'actants.
Le processus fonctionne ensuite en calculant la meilleure affectation globale possible d'icÙnes ý cas sur l'ensemble de la sÈquence.
Dans la suite, nous noterons s 1 , s 2 , ... s n la sÈquence de symboles iconiques en entrÈe de l'analyse. Chacune de ces icÙnes a un ensemble de sËmes intrinsËques :
SI( s i ) = e i
(o˘ e i est un ensemble de traits sÈmantiques simples, du type couple attribut-valeur),
et certaines d'entre elles ont des sËmes extrinsËques qui constituent une structure casuelle (SC) lorsqu'on les factorise par cas :
SC( s i ) = { < c 1 , e i1 > , < c 2 , e i2 > , ... < c N , e iN > }
(o˘ chacun des N c j est un type casuel comme agent, objet, instrument ..., et chaque e ij un ensemble de traits sÈmantiques simples de type couple attribut-valeur).
On pourra noter plus prÈcisÈment l'ensemble des traits sÈmantiques simples (attribut-valeur) rattachÈs ý s i en tant que traits extrinsËques pour un cas c j :
SE( s i , c j ) = e ij
ce qui est Èquivalent ý :
< c j , e ij > appartient ý SC( s i )
La compatibilitÈ sÈmantique est la valeur que l'on cherche ý maximiser pour dÈterminer les meilleures affectations. C'est une relation binaire asymÈtrique : elle mesure le degrÈ de compatibilitÈ d' une icÙne ý une place d'actant d'une autre icÙne.
Au niveau du sËme : la compatibilitÈ atomique se calcule au niveau du sËme, entre un sËme intrinsËque de l'icÙne ´ candidat ª et un sËme extrinsËque de l'icÙne ´ prÈdicat ª. La compatibilitÈ est nulle si les sËmes sont orthogonaux (attribut diffÈrent). Si l'attribut est le mÍme, elle est Ègale au produit des valeurs attachÈes ý cet attribut dans l'un et l'autre sËme. Par exemple la compatibilitÈ sÈmantique est nulle entre /animÈ =+/ et /petit =+/ , positive entre /animÈ =+/ et /animÈ =+/ , nÈgative entre /animÈ =+/ et /animÈ =≠/ .
|
(1) |
Les valeurs des sËmes extrinsËques sont des coefficients rÈels. Ce choix de modÈlisation permet de rÈgler finement le caractËre plus ou moins contraignant (´ sÈlectionnel ª) d'un trait extrinsËque. Les valeurs des sËmes intrinsËques, elles, sont entiËres : gÈnÈralement {+1,≠1}, ou, dans le cas du sËme spatial /dimension/, {1,2,3}.
Au niveau des structures de traits : les signifiÈs des icÙnes sont reprÈsentÈs par des ensembles de traits. Le calcul de la compatibilitÈ sÈmantique entre deux ensembles de traits se fait entre deux ensembles homogËnes de couples attribut-valeur. Ce sont d'une part les sËmes extrinsËques attachÈs ý un actant donnÈ de l'icÙne prÈdicat - dÈpouillÈs donc du type de relation casuelle, avec seulement le couple attribut-valeur -, et d'autre part les sËmes intrinsËques de l'icÙne candidat.
La compatibilitÈ du deuxiËme ensemble avec le premier est dÈfinie comme la somme des compatibilitÈs sÈmantiques des sËmes communs aux deux ensembles, rapportÈe au nombre total de sËmes dans le premier ensemble :
|
(2) |
( e 1 est l'ensemble des sËmes filtrants)
Au niveau d'une relation actancielle : la compatibilitÈ sÈmantique est ý ce niveau le degrÈ d'affinitÈ d'une icÙne candidate s j ý une place actancielle d'une icÙne prÈdicative s i .
C'est donc la compatibilitÈ sÈmantique de l'ensemble des sËmes intrinsËques de s j avec l'ensemble des sËmes extrinsËques de s i pour le cas c k :
| C ( SE( s i , c k ) , SI( s j ) ) | (3) |
Cette grandeur exprime la plus ou moins grande ´ conformitÈ ª du contenu sÈmantique intrinsËque de s j avec les contraintes que s i impose ý son actant pour le cas c k , contraintes modÈlisÈes par les sËmes extrinsËques (ß 2.1.2). Elle conditionne l'unification de s j comme actant de s i (fig. 8).
|
Pour chaque icÙne prÈdicative de la sÈquence d'entrÈe, il s'agit donc de remplir au mieux tous les rÙles casuels : le mÈcanisme de distribution d'actants ý l'icÙne prÈdicative fonctionne en essayant de trouver la combinaison qui maximise globalement la valeur des attributions d'actant.
Nous appelons affectation une combinaison possible d'attributions d'actants pour l'icÙne prÈdicative s i . C'est donc une application de l'ensemble des cas de s i :
{ c 1 , c 2 , ... c k },
dans un ensemble d'icÙnes de la sÈquence d'entrÈe candidates ý en Ítre les actants :
{ s i1 , s i2 , ... s ij }.
Soit A une application de ce type :
| A = {< c x , s iy >}, o˘ x appartient ý [1,k] et y appartient ý [1,j]. | (4) |
Nous cherchons ý maximiser une valeur globale pour cette affectation. Cette valeur globale est la somme des valeurs de chacune des attributions individuelles < c x , s iy > qui constituent l'application A :
| V(A) = V( s i , {< c 1 , s i1 >, < c 2 , s i2 >, ... < c k , s ik >}) = Somme j dans [1,k] V( s i , c j , s ij ) | (5) |
La valeur de chaque attribution individuelle d'actant, V( s i , c j , s ij ), n'est pas la simple compatibilitÈ sÈmantique de l'icÙne s ij avec le cas c j de l'icÙne s i (…q. 3). Il faut en effet tenir compte, pour Èvaluer la valeur d'une attribution d'actant ý un prÈdicat dans le contexte d'une sÈquence d'icÙnes, d'un facteur qui est la distance de l'icÙne candidate au prÈdicat.
Les sÈquences d'icÙnes en entrÈe de PVI s'inscrivent en effet dans une linÈaritÈ syntagmatique, et sont sujettes aux phÈnomËnes les plus universels liÈs ý cette dimension des systËmes de signes, ý savoir l'effet de rÈcence et ses corrÈlats. On considËre certes que les messages produits dans le contexte d'utilisation de ce systËme n'ont pas de syntaxe , mais cela n'exclut pas qu'ils aient une syntagmatique .
Ainsi lors de l'analyse d'une sÈquence longue comme PAPA / VOIR / CHAT / GENTIL / MANGER / VIANDE, au moment de dÈcider de l'affectation du sujet du prÈdicat GENTIL, c'est la proximitÈ de CHAT qui devra dÈcider de son choix de prÈfÈrence ý PAPA - qui autrement, hors de tout contexte, a la mÍme compatibilitÈ sÈmantique avec cet adjectif.
Nous dÈfinissons donc la valeur de l'attribution de l'icÙne s ij comme actant, pour le cas c j , de l'icÙne prÈdicat s i , comme Ètant la compatibilitÈ sÈmantique de s ij avec le cas c j de s i , multipliÈe par un coefficient qui est une fonction D de la distance entre s i et s ij :
| V ( s i , c j , s ij ) = D ( s i , s ij ). C ( SE( s i , c j ), SI( s ij ) ) | (6) |
| ---> | Le choix de la fonction D s'est fait purement par t‚tonnements, en essayant diverses fonctions dÈcroissantes et en testant leur adÈquation avec les rÈsultats attendus sur un corpus donnÈ. Nous avons finalement arrÍtÈ le choix sur la fonction en2 .ln(L ) , o˘ n est la distance entre les deux icÙnes, et L une constante comprise entre 0 et 1, appelÈe localite, et qui dÈtermine la vitesse de dÈcroissance en fonction de la distance (une constante de localitÈ Ègale ý 1 signifie aucune dÈcroissance quelle que soit la distance, une constante Ègale ý 0 signifie que le coefficient tombe ý 0 dËs la premiËre icÙne aprËs le prÈdicat). Cette fonction ne prÈtend ý aucune validitÈ de modÈlisation cognitive ou autre. |
|---|
Une affectation n'intËgre pas systÈmatiquement une attribution d'icÙne ý chacun des actants possibles : les attributions individuelles ayant une valeur infÈrieure ý un certain seuil (constante seuil) sont rejetÈes, et la place actancielle reste vacante.
Chaque affectation A calculÈe par le moteur PROLOG ý ce niveau, pour chaque icÙne prÈdicative s i , est donc un ensemble de couples < c j , s ij > tel que chacun de ces couples vÈrifie :
et dont la valeur totale est
| V ( A ) = Somme < c j , s ij > dans A V ( s i , c j , s ij ) | (7) |
|
Une interprÈtation de la sÈquence d'icÙnes d'entrÈe est un ensemble d'affectations correspondant chacune ý l'une des icÙnes prÈdicatives de la sÈquence.
Le mÈcanisme de base de l'analyse de la sÈquence d'entrÈe doit aboutir ý une interprÈtation de celle-ci. Il consiste donc en :
L'Ètape (a) est effectuÈe lors d'un premier parcours rapide de la sÈquence, o˘ l'on regarde dans le dictionnaire, pour chaque icÙne, si elle a des sËmes extrinsËques ou non.
L'Ètape (b) consiste, pour chaque icÙne identifiÈe comme prÈdicative, ý en construire toutes les affectations possibles, ý calculer pour chacune sa valeur, puis ý les ordonner par un algorithme de tri de type " quicksort " [Bratko 1990].
Pour ce qui concerne enfin l'Ètape (c), l'unification est implicite (car les mÍmes identificateurs PROLOG sont utilisÈs dans le calcul de chaque affectation) ; en revanche, trois opÈrations sont effectuÈes avant que le rÈsultat de l'analyse ne soit rendu au module suivant :
Les affectations Ètant triÈes par ordre de valeur (Èq. 7) dÈcroissante, le programme PROLOG, lorsqu'il calcule toutes les interprÈtations possibles par produit cartÈsien des affectations des prÈdicats de la sÈquence, renvoie donc ses rÈsultats dans un ordre correspondant. Ainsi si les affectations possibles pour la premiËre icÙne prÈdicative de la sÈquence sont, dans l'ordre, A 11, A 12, ... A 1m1 ; si les affectations possibles pour la seconde icÙne prÈdicative sont, dans l'ordre, A 21, A 22, ... A 2m2 ; et ainsi de suite jusqu'ý la niËme et derniËre icÙne prÈdicative, dont les affectations possibles sont A n1, A n2, ... A nmn ; alors l'ordre dans lequel apparaissent les interprÈtations possibles de la sÈquence est :
| A 11, | A 21, | ... | A n1 |
| A 11, | A 21, | ... | A n2 |
| ... | |||
| A 11, | A 21, | ... | A nmn |
| ... | |||
| ... | |||
| ... | |||
| A 1m1, | A 2m2, | ... | A nmn |
Si nous considÈrons que la somme des valeurs des affectations de chaque icÙne prÈdicative constitue une grandeur reprÈsentant une sorte d' ´ harmonie sÈmantique ª globale de l'interprÈtation, alors cet ordre, sans assurer une dÈcroissance de cette grandeur, assure que la premiËre interprÈtation fournie en est au moins un maximum absolu (c'est la somme des maxima locaux).
Deux catÈgories d'icÙnes ont un traitement spÈcial au cours de l'analyse.
Cette catÈgorie regroupe les icÙnes des taxËmes ' qualifieurs ' (adjectifs comme ' bon ', ' drÙle ', ' grand ' ...), ' modalitÈs ' (' non ', ' peut-Ítre ', ' s˚rement '), ' mots simples ' (mots isolÈs comme ' bonjour ', ' merci ', ' pardon ' ...), ' temps ' (' passÈ ', ' futur ') et ' emphase ' (' interrogation ', ' exclamation ').
Le fait de considÈrer ces icÙnes comme ´ sans Èpaisseur ª est un artifice qui traduit la rÈcursivitÈ du processus psychologique de prÈdication. En pratique, cette ´ astuce ª permet de prendre en compte certains phÈnomËnes prÈsents dans les corpus, comme l' ´ entassement ª d'adjectifs.
Ces icÙnes ´ non prÈdicables ª sont les ' temps ', les ' modalitÈs ', les ' emphases ' d'une part ; les ' expressions figÈes ' et les ' phrases ý trous ' d'autre part.
Les trois premiers taxËmes sont des marqueurs d'inflexions sÈmantiques de haut niveau, qui s'appliquent dÈjý ý des prÈdicats ; il est pratiquement inimaginable, dans un langage ordinaire, qu'ils puissent eux-mÍmes devenir objets d'un autre prÈdicat [3].
Les deux derniers regroupent des phrases toutes faites, sans actant ou complÈtables au plus par un actant optionnel, prÈsentes dans l'interface de PVI pour permettre des saisies rapides de messages urgents du type ´ attendez! ª, ´ je ne comprends pas ª, ou ´ [ j'ai ] un problËme ª, ´ [ je m' ] appelle x ª ... Ces icÙnes forment des messages prÈformatÈs, et il ne convient pas qu'elles entrent elles-mÍmes dans la composition de messages classiques.
La premiËre passe d'analyse (ß 2.2.3) fonctionne en cherchant une combinaison d'affectations pour chaque icÙne prÈdicative de la sÈquence d'entrÈe, donc ý chaque fois une combinaison d' applications de l'ensemble des cas vers l'ensemble des icÙnes. Elle ne prend donc en compte qu'une seule icÙne par place d'actant.
Il existe pourtant, dans les corpus, de nombreux exemples d'ÈnumÈrations, qu'il conviendrait de comprendre comme des surcharges d'un mÍme rÙle casuel par ´ entassement ª d'actants homogËnes.
Une deuxiËme passe d'analyse prend en charge ces phÈnomËnes. Elle consiste ý reprendre une ý une les icÙnes qui n'ont pas ÈtÈ affectÈes lors de la premiËre passe, et ý calculer pour chacune d'elles quel serait son score d'affectation ý tel ou tel actant de tel ou tel prÈdicat. Le meilleur de ces scores, s'il dÈpasse un seuil donnÈ (seuil_icone_isolee), dÈtermine alors une dÈcision de rÈaliser l'affectation concernÈe.
On peut par suite avoir, dans le graphe rÈsultant de cette analyse, une surcharge d'actants du type :
[ALLER : agent = MOI, destination = PLAGE, agent = PAPA, agent = MAMAN]
(rÈsultat de l'analyse de MOI / ALLER / PLAGE / PAPA / MAMAN).
3. Le module de transfert lexical
![]()
Le rÈsultat d'une analyse est une interprÈtation de la sÈquence (ß 2.2.3), c'est-ý-dire une sÈquence d'affectations du type < s i , < c j , s ij >>. Ce format est topologiquement Èquivalent ý un graphe conceptuel [Sowa 1984]. Ainsi les interprÈtations [MANGER : agent = MOI, objet = VIANDE, instrument = FOURCHETTE] (´ je mange la viande avec la fourchette ª), et [VOIR : agent = MOI, objet = MANGER], [MANGER : agent = CHAT] (´ je vois que le chat mange ª) sont respectivement Èquivalentes aux graphes conceptuels reprÈsentÈs fig. 10 et fig. 11.
![[MOI] <-(agent)- [MANGER] ∂ -(objet)-> [VIANDE] ∂
-(instr)-> [FOURCHETTE]](fomomavi.gif)
|
![[MOI] <-(agent)- [VOIR] -(objet)-> [MANGER] -(agent)->
[CHAT]](movochma.gif)
|
Il y a nÈanmoins dans la reprÈsentation linÈarisÈe du graphe une information supplÈmentaire, qui rÈside dans l' ordre dans lequel les affectations sont mises. Retrouver cette information dans le graphe conceptuel Èquivaudrait ý en numÈroter les concepts.
Cet ordre a une importance en ce qu'il reflËte en partie l'ordre originel de la sÈquence d'icÙnes d'entrÈe. Celui-ci peut Èventuellement avoir une signification, non en tant que manifestation d'une structure syntaxique, mais en tant que la topicalitÈ du message, c'est-ý-dire l'ordre d'importance des concepts exprimÈs.
Cet ordre est prÈservÈ ý travers l'ordre des icÙnes prÈdicatives de la sÈquence d'entrÈe. Ainsi l'analyse des sÈquences MOI / VOIR / CHAT / MANGER et CHAT / MANGER / VOIR / MOI conduit-elle respectivement aux interprÈtations [VOIR : agent = MOI, objet = MANGER], [MANGER : agent = CHAT], et [MANGER : agent = CHAT], [VOIR : agent = MOI, objet = MANGER]. Ces deux reprÈsentations linÈaires sont de la mÍme faÁon topologiquement Èquivalentes au graphe de la figure 11, mais la premiËre reflËte l'attention portÈe sur l'action VOIR, alors que la seconde reflËte l'attention sur l'action MANGER.
L'information de topicalitÈ du messsage, prÈsente dans cette reprÈsentation pivot, n'est malheureusement pas assez souvent transcrite au niveau de la phrase gÈnÈrÈe, car le module de gÈnÈration de PVI est trop rudimentaire pour mettre en oeuvre toutes les tournures par lesquelles la langue franÁaise peut traduire ce type d'information (parmi lesquelles l'une des plus importantes est par exemple la voix passive, qui n'est pas gÈrÈe par le module de gÈnÈration). Pour un exemple de traduction de la topicalitÈ au niveau de la phrase franÁaise, voir ß 4.2.2.
Le graphe conceptuel ´ orientÈ ª qui constitue la reprÈsentation fournie ý la sortie du module d'analyse est converti en un format adaptÈ ý l'entrÈe du module de gÈnÈration. Ce format est une sorte de nouveau graphe conceptuel ´ enrichi ª, o˘ ý chaque noeud conceptuel est attachÈ une place libre rÈservÈe ý des informations morphosyntaxiques. Ces informations ne sont pas instanciÈes ý l'entrÈe du module de gÈnÈration, mais s'instancient au fur et ý mesure de l'application de rËgles d'accord et de rection.
Les noeuds conceptuels du graphe en sortie de l'analyse sont des entrÈes du dictionnaire d'icÙnes, alors que les noeuds conceptuels du nouveau graphe doivent Ítre des entrÈes du lexique linguistique utilisÈ pour la phase de gÈnÈration. Cela signifie, en thÈorie, que le sens pourrait en outre Ítre redistribuÈ sur les concepts, reflÈtant en cela des diffÈrences entre les sÈmantiques des deux langages, le langage d'icÙnes utilisÈ en entrÈe, et la langue utilisÈe en sortie. Ce phÈnomËne est un poncif de la traduction : ainsi, en traduisant l'allemand ´ ¸ber den Fluþ schwimmen ª par le franÁais ´ traverser la riviËre ý la nage ª, le sËme / nage / passe du verbe principal ý un complÈment circonstanciel, tandis que dans le mÍme temps le sËme / traversÈe /, d'une prÈposition spatiale, est rÈintÈgrÈ au verbe principal (exemple empruntÈ ý Malmberg [1979]). Cependant, dans l'application PVI, ce phÈnomËne n'est quasiment pas reprÈsentÈ. En effet le code pictographique utilisÈ comme source principale de la base de donnÈes lexicale d'icÙnes (le code ´ Commun-I-Mage ª) a dÈjý, ý la base, ÈtÈ conÁu comme un catalogue de transcriptions pictographiques de lexËmes franÁais.
Un exemple d'utilitÈ actuelle du module de transfert lexical est la transformation de la coordination. Celle-ci se manifeste ý la sortie de l'analyse comme une surcharge d'actants. Elle est transformÈe, dans le rÈseau linguistique fourni en entrÈe au module de gÈnÈration, en un nouveau noeud prÈdicatif, ÈtiquetÈ " et ", et dont les actants sont les diffÈrents noeuds coordonnÈs qui se trouvaient originellement dans le mÍme rÙle casuel. Ainsi un graphe du type [ALLER : agent = MOI, destination = PLAGE, agent = PAPA, agent = MAMAN], devient-il un graphe [ALLER : agent = ET, destination = PLAGE], [ET : coordonne1 = MOI, coordonne2 = PAPA, coordonne3 = MAMAN]. Ce noeud " et " est destinÈ lors de la phase de gÈnÈration ý devenir un groupe nominal subordonnant plusieurs groupes nominaux plus simples entre lesquels s'intercalent des conjonctions de coordination ´ et ª.
L'existence de la couche de transfert lexical est en tout Ètat de cause un ÈlÈment important qui assure l'indÈpendance des modules d'analyse et de gÈnÈration. MÍme si cette couche joue un rÙle tÈnu dans la version actuelle de PVI, elle pourrait s'Ètoffer si un changement du langage d'icÙnes utilisÈ en entrÈe rendait cette Èvolution nÈcessaire. RÈciproquement, garder le module d'analyse tel qu'il existe dans l'application actuelle et ´ brancher ª, ý la place du module de gÈnÈration en franÁais, un module de gÈnÈration dans n'importe quelle autre langue, ne demande pas d'autre Èvolution qu'une modification du systËme de transfert lexical.
Suite ![]()
NB Ce chapitre fait partie
de la thËse ´ Interaction entre modalitÈs
sÈmiotiques : de l'icÙne ý la langue ª,
UniversitÈ Paris-XI (Orsay), 1997. EffectuÈe sous la direction de FranÁois Rastier)
Voir le rÈsumÈ de la thËse ![]()
NOTES :
[1] Ainsi, en langue, on les trouve mÍme souvent mentionnÈs dans les dictionnaires (par exemple ´ ABOYER : donner de la voix, en parlant d'un chien. ª, [Petit Robert]).
[2] Ces cycles sont la manifestation d'incohÈrences dans l'analyse ; toutefois, une exigence d'efficacitÈ a fait choisir de les Èliminer ý l'aveugle sans chercher ý lancer une deuxiËme passe d'analyse plus poussÈe.
[3] Cela se traduirait par des phrases du type ´ Je vois que l'action x s'est dÈroulÈe dans le passÈ ª, ou ´ Tu dÈclares que la connaissance du fait y est entachÈe d'incertitude ª ...
![]()
© Texto! 2001pour l'Èdition Èlectronique