Victor Rosenthal : Approche microgťnťtique du langage et de la perception
--- page 27---
7. Processus perceptifs de la lectureLe langage se prťsente toujours dans un certain format, c'est-ŗ-dire sous la forme d'un signal (sťquences sonores, formes visuelles, configurations tactiles) modal dťterminť. Ses diffťrents formats- auditif, visuel, tactile- ne sont pas strictement ťquivalents, et si les caractťristiques de chacun sont susceptibles de nous apprendre quelque chose sur le langage [45] cela vaut ťgalement pour leurs diffťrences. Les travaux rťsumťs dans ce qui suit n'ont au dťpart ťtť entrepris que dans le but d'explorer les processus de la comprťhension du langage se situant en amont de la dťsambiguation morpho-syntaxique, de īconcrťtiser' en quelque sorte la thťorie de la catťgorisation lexicale en la rattachant au traitement du signal langagier dans une modalitť donnťe : la vision. Puisque l'objectif ťtait de spťcifier d'une faÁon dťtaillťe et chronologique les traitements qui, partant d'un signal langagier aboutissent ŗ une interprťtation conventionnelle de ce dernier, il fallait aborder la forme physique de ce signal tel qu'il se prťsente dans la modalitť considťrťe. Et c'est ainsi que les recherches sur la comprťhension du langage se sont progressivement transformťes en ťtude des processus perceptifs de la lecture.
Contrairement ŗ la parole oý il n'existe pas de sťparation temporelle [46] , ędes blancs' entre les mots, l'ťcriture (et l'imprimť) telle que nous la pratiquons aujourd'hui [47] comporte des espaces blancs qui individualisent les mots, leur confťrant ainsi un statut de stimuli distincts. Dans une ťcriture orthographique, les mots sont composťs de lettres. Avec quelques vingt-six lettres de l'alphabet nous pouvons composer un nombre quasiment infini de mots. Les lettres forment des mots, les mots forment des phrases, les phrases des paragraphes, des chapitres÷ Il existe ainsi plusieurs niveaux de description qui peuvent intťresser la thťorie du traitement perceptif de l'ťcrit. On peut caractťriser les mots, notamment les mots en minuscules comme dans ce texte, ŗ partir des lettres dont ils se composent mais on peut ťgalement dťcrire leur forme globale. Il est sans doute tentant d'appliquer une sorte de īlogique compositionnelle' pour dťcrire la reconnaissance des mots au cours de la lecture : puisque les mots sont composťs de lettres, la reconnaissance des mots doit passer par la reconnaissance de leurs lettres. Et en effet, force est de reconnaÓtre que 26 unitťs gťnťriques (lettres) sont plus faciles ŗ gťrer et ŗ apprendre que quelques dizaines de milliers de formes globales non-gťnťriques (mots). Les recherches modernes sur les processus de la lecture sont indissociables du dťbat concernant les unitťs de base de l'analyse visuelle de l'ťcrit : s'agit-il de mots entiers, de lettres ou encore de leurs traits constitutifs (boucle, barre..)? Les questions de savoir comment de telles unitťs fixes d'analyse sont traitťes et reconnues par le systŤme visuel et si ce dernier est ťquipť pour procťder de la sorteont toutefois rarement ťveillť l'intťrÍt des spťcialistes de la lecture ou de la reconnaissance des mots.
Deux approches de la lecture, l'une globale (parce qu'elle privilťgiait le format mot), l'autre analytique (parce qu'elle privilťgiait les formats infralexicaux tels que lettres ou leurs traits constitutifs) se sont trŤs tŰt cristallisťes, et leur rivalitť a pavť l'histoire des recherches psychologiques sur la reconnaissance visuelle des mots. L'approche analytique s'est structurťe ŗ partir et autour de la rťaction (virulente) de Wundt ŗ la publication des Recherches Psychologiques Expťrimentales sur la Lecture de Erdmann et Dodge (1898) qui montraient au moyen d'expťriences tachistoscopiques que, par unitť de temps constante, on reconnaÓt quatre ŗ cinq fois plus de lettres dans des mots que dans des sťquences de lettres sans signification. Ces observations corroboraient les travaux antťrieurs de Cattell (1886) qui avaient dťjŗ mis en ťvidence ce que l'on allait plus tard appeler 'word-superiority effect', ŗ savoir que par exemple le temps nťcessaire pour reconnaÓtre un mot est sensiblement plus court que la somme des temps que prend la reconnaissance des lettres individuelles dont ce mot est composť. La rťaction de Wundt ťtait comprťhensible dans la mesure oý ces rťsultats montraient la pertinence du format lexical (global) dans la lecture et de ce fait ťtaient en contradiction flagrante avec le fond mÍme de la conception ťlťmentariste des processus mentaux dont Wundt ťtait, aux cŰtťs d'Ebbinghaus, le plus illustre promoteur. Wundt contestait en particulier les mťthodes tachistoscopiques utilisťes par Cattell et Erdmann et Dodge, et cela mÍme lorsque son propre ťlŤve Zeitler a obtenu les mÍmes rťsultats que Cattell tout en suivant les recommandations de son maÓtre [48] . Avec le temps, les conclusions de Cattell et d'Erdmann et Dodge ont ťtť confirmťes et consolidťes par beaucoup d'autres recherches (cf. Johnson, 1975; Neisser, 1967) . De surcroÓt, on a montrť qu'un mot frťquent est reconnu plus rapidement qu'un mot peu frťquent, mÍme plus court (cf. Solomon & Howes, 1951; Solomon & Postman, 1952) , qu'une lettre est identifiťe plus rapidement dans un mot que dans un non-mot (cf. Reicher, 1969; Wheeler, 1970) ou que les propriťtťs de la forme globale du mot affectent sa reconnaissance, tant sur le plan qualitatif (i.e. type d'erreurs) que quantitatif (i.e. le temps de rťaction, cf. par exemple Havens & Foote, 1963) . Tous ces rťsultats semblaient ainsi parachever la dťmonstration du caractŤre erronť de la īlogique compositionnelle' Ė par exemple, il semblait dťsormais exclu que les mots soient reconnus au cours de la lecture au moyen d'un processus de reconnaissance sťquentielle des lettres- et l'on croyait pouvoir clore le dťbat concernant les unitťs de base de l'analyse visuelle de l'ťcrit (cf. Henderson, 1987; Huey, 1908; Neisser, 1967; Scheerer, 1981; Woodworth, 1938) .
C'est la proposition (faite par quelques auteurs autour de 1975) que la reconnaissance des lettres peut procťder en parallŤle qui a permis de relancer l'approche analytique (Adams, 1979; Henderson, 1987; McClelland, 1976) . Plusieurs expťriences ont alors ťtť entreprises dans le but explicite de mettre en cause l'hypothŤse que la forme globale du mot joue un rŰle substantiel dans son identification. Ainsi, on a montrť :
- que la reconnaissance des mots, pseudo-mots [49] et non-mots est perturbťe d'une faÁon comparable lorsqu'on mťlange les majuscules et les minuscules (cAsE mIxInG Adams, 1979) ;
- qu'il est possible d'obtenir un effet d'amorÁage orthographique entre les mots formťs ŗ partir des mÍmes identitťs littťrales (hand- HAND) mais dont la forme globale est diffťrente (Evett & Humphreys, 1981; Humphreys, Evett, Quinlan, & Besner, 1987) ;
- que le changement du format du mot (target ∆ TARGET) au cours de la saccade oculaire n'affecte pas le temps de lecture ŗ haute voix de ce mot (McConkie & Zola, 1979; Rayner, McConkie, & Zola, 1980) .
Ces rťsultats s'ajoutant ŗ ceux de Paap, Newsome, and Noel (1984) , qui suggťraient que ce n'est pas la ressemblance de la forme des mots mais celle de la forme des lettres qui est ŗ l'origine de la difficultť de dťtecter certaines erreurs typographiques dans les tāches de ęcorrections d'ťpreuves' , semblaient ainsi, aux yeux de nombreux auteurs, lťgitimer dťfinitivement les thťories de la lecture dans lesquelles la reconnaissance des lettres (en parallŤle) constitue la base sinon exclusive du moins essentielle de la reconnaissance des mots. La quasi-totalitť des modŤles de reconnaissance visuelle des mots proposťs ŗ partir du dťbut des annťes 1980 adhŤre ŗ cette vision compositionnelle ou analytique des processus de la lecture (cf. Adams, 1979; Besner & Johnston, 1989; Grainger & Jacobs, 1996; Johnson & Pugh, 1994; Johnston & McClelland, 1980; McClelland & Rumelhart, 1981; Paap, Newsome, McDonald, & Schvaneveldt, 1982) .
Ce rappel historique permet de situer le contexte thťorique sur le fond duquel j'allais m'employer ŗ īconcrťtiser' la thťorie de la catťgorisation lexicale ŗ la fin des annťes 1980. Les modŤles les plus influents ťtaient issus des recherches tachistoscopiques sur la reconnaissance de mots isolťs. Ils ignoraient largement les effets du contexte, de la syntaxe et de la sťmantique sur la reconnaissance mÍme du mot et de ce fait se qualifiaient difficilement comme des modŤles de la lecture. Quant ŗ la reconnaissance du mot, mÍme au sens trŤs limitť du terme, ces modŤles se bornaient ŗ indiquer l'existence d'un ęmťcanisme' de reconnaissance des lettres sans spťcifier concrŤtement comment cette reconnaissance s'effectue au niveau visuo-perceptif. Sur bien de plans, l'objectif principal des modŤles qui ont jouť un rŰle dťterminant dans ce domaine au cours des 20 derniŤres annťes n'ťtait pas tant la description du processus de reconnaissance visuelle des mots ou de la lecture mais celle de l'accŤs au lexique ŗ partir du stimulus prťsentť dans la modalitť visuelle (voir notamment Henderson, 1987, pour une discussion) . On n'y trouve aucune description des processus censťs Ítre mis en ķuvre dans l'analyse visuelle et qui permettraient la reconnaissance (en parallŤle) des lettres [50] . On n'y trouve pas davantage d'explication de la faÁon dont peut s'effectuer l'interface entre le traitement purement perceptif et les traitements linguistiques et cognitifs. Pourtant il ne fait dťsormais aucun doute que ces derniers interviennent avant l'identification explicite du mot (voir les ouvrages ťditťs par Besner & Humphreys, 1991, pour plus de dťtail; Coltheart, 1987a) . Ainsi, une thťorie ou un modŤle des processus perceptifs de la lecture se doit de fournir une description de l'interface entre ces diffťrents traitements avant qu'ils n'aient conduit ŗ l'identification du mot.
Les modŤles issus des expťriences tachistoscopiques avec des mots imprimťs prťsentťs isolťment me semblaient, par ailleurs, clairement inadaptťs pour rendre compte de la lecture de l'ťcriture manuscrite. Par exemple, les modŤles qui postulent que les mots sont reconnus au moyen du traitement en parallŤle de toutes les lettres ignorent le fait qu'il est trŤs souvent impossible d'identifier les lettres d'un mot manuscrit sans avoir une hypothŤse sur l'identitť de ce mot (cf. Parisse, Rosenthal, Imadache, Andreewsky, & Cochu, 1990) . Quelles que soient les spťcificitťs de l'ťcriture manuscrite et de l'imprimť, la lecture de l'une et de l'autre s'est dťveloppťe sur la base des mÍmes capacitťs perceptives et de la mÍme pratique du langage.
Enfin, les modŤles issus des recherches tachistoscopiques sur les mots isolťs ont beaucoup de mal sinon ŗ expliquer, du moins ŗ intťgrer les donnťes provenant de l'observation de certains comportements pathologiques en lecture. Il s'agit notamment du comportement des dyslexiques profonds (cf. Coltheart, 1980; Coltheart, Patterson, & Marshall, 1987) . A la suite d'une lťsion cťrťbrale, ces patients sont incapables de reconnaÓtre les lettres de l'alphabet et ne peuvent pas lire les pseudo-mots [51] ou les non-mots. Ils sont nťanmoins capables de lire certains mots, avec plus ou moins de difficultťs selon leur catťgorie grammaticale. Ainsi, alors que les mots fonctionnels, tels qu'articles ou conjonctions sont trŤs rarement lus, les mots-pleins (noms, adjectifs, verbes) posent moins de difficultťs, ŗ ceci prŤs que leur lecture est susceptible de se traduire par des paralexies sťmantiques (par exemple, lorsque prÍtre est ťnoncť en lecture ŗ la place de ťglise ). Ce comportement appelle trois observations :
- la reconnaissance des lettres n'est pas une condition sine qua non pour la reconnaissance des mots;
- la syntaxe intervient dans la reconnaissance des mots en lecture; sinon, comment expliquer la diffťrence entre la lecture des mots-pleins et des mots fonctionnels?
- la sťmantique intervient avant l'identification complŤte du mot; sinon, comment expliquer les paralexies sťmantiques de ces patients?
Ce comportement pathologique ne semble nullement Ítre le fruit d'un traitement aberrant, ni d'ailleurs d'un systŤme crťť de novo suite ŗ la lťsion cťrťbrale. Il s'agit plutŰt d'une interruption de la chaÓne logique des traitements qui fait apparaÓtre dans le comportement des produits inachevťs des traitements, produits qui dans des conditions normales auraient ťtť davantage ťlaborťs (Rosenthal, 1988; Semenza et al., 1988) . 0n peut en effet trouver des effets analogues chez des sujets normaux. C'est par exemple le cas de l'amorÁage subliminal ou parafovťal; ainsi, lorsqu'on prťsente ŗ un sujet des couples de mots sťmantiquement proches ( table - chaise ) de telle sorte que le premier mot ne puisse pas Ítre identifiť (soit qu'il est prťsentť d'une faÁon trop brŤve, soit qu'il est prťsentť dans la zone parafovťale de la rťtine qui ne permet pas d'identifier un mot) on trouve un effet de facilitation (temps de reconnaissance plus court) sur le second mot. Ainsi, bien que le sujet ne soit pas capable d'identifier le premier mot, il est clair qu'il a d› en faire un certain traitement sťmantique qui influence ŗ son tour l'identification du second mot (cf. Marcel, 1983) .
L'utilisation quasi exclusive des mots isolťs dans les recherches neuropsychologiques soulŤve d'ailleurs autant d'objections que lorsqu'il s'agit de travaux avec les lecteurs normaux. Le cťlŤbre patient agnosique (Sch.) de Gelb et Goldstein (1938) ťtait capable de lire des livres et des journaux (mÍme s'il se plaignait que cela le fatiguait beaucoup). Il a toutefois ťchouť ŗ toutes les prťsentations tachistoscopiques de mots isolťs; mÍme lorsque le temps de prťsentation ťtait de 2 sec. il ne pouvait rien lire et disait : 'On ne peut pas lire cela, il faudrait connaÓtre la stťno'. Il arrive aux dyslexiques profonds, qui ťprouvent tant de difficultťs ŗ lire les listes de mots concoctťes par les expťrimentateurs, de lire le quotidien du jour ou une revue. Comment y parviennent-ils alors qu'ils ne peuvent correctement lire ŗ haute voix plus de 40% de mots prťsentťs isolťment? Ces exemples montrent que la lecture (ŗ haute voix) ou l'identification de mots isolťs ne peut Ítre prise pour le critŤre de la capacitť de lire.
A partir de ces observations il m'est apparu que le traitement perceptif du langage ťcrit comporte ŗ la fois des processus locaux et globaux et que ces derniers atteignent ŗ une ťtape prťcoce du traitement un niveau d'ťlaboration tel que l'intervention des processus linguistiques et cognitifs devient possible, et cela avant ou sans l'identification explicite du mot. Mais aucune ťtude n'offrait de rťelle proposition quant ŗ la nature de ces traitements ou ŗ leur structure logique.
Certains travaux dans le domaine de l'analyse des mouvements oculaires en lecture paraissaient instructifs ŗ cet ťgard. Il est connu depuis le 19 Ťme siŤcle que les mouvements oculaires en lecture ne sont pas uniformes, le regard se posant successivement sur chaque lettre, mais saccadťs, de sorte que seule une partie du mot est en gťnťral fixťe et certains mots ne le sont mÍme pas du tout. Deux questions viennent immťdiatement ŗ l'esprit dŤs que l'on prend connaissance de ces faits : qu'est-ce qui est fixť et qu'est-ce qui dťtermine l'emplacement des fixations?
Il faut prťciser que la rťtine de l'homme n'est pas une structure homogŤne mais diffťrenciťe notamment par la distribution des cŰnes et des bātonnets. Le centre de la rťtine ou la fovťa comporte la plus grande concentration de cŰnes et c'est ťgalement la partie de l'ķil oý la vision est la plus nette; en fait, lorsqu'on parle des fixations du regard on entend par lŗ fixations fovťales. La partie extrafovťale de la rťtine comporte une concentration dťcroissante des cŰnes, au fur et ŗ mesure que l'on s'ťloigne de la fovťa. On dťfinit en gťnťral l'empan de la zone fovťale ŗ 2Ä, c'est-ŗ-dire 1Ä ŗ gauche et 1Ä ŗ droite du centre de la fixation. La description de la zone extrafovťale est plus complexe. On distingue en gťnťral une zone parafovťale qui s'ťtend jusqu'ŗ 5Ä ŗ gauche et ŗ droite de la fixation (c'est-ŗ-dire entre 1Ä-5Ä) et une zone pťriphťrique ŗ partir de 5Ä. Toutefois ces zones sont loin d'Ítre homogŤnes. Il est certain qu'un mot ou un objet complexe ne peut Ítre explicitement identifiť dans la zone extrafovťale (mÍme ŗ 4Ä) mais une lettre isolťe ou une couleur peuvent l'Ítre jusqu'ŗ 15Ä ŗ 20Ä du centre de fixation. Toutefois, cette mÍme lettre ne pourra pas Ítre identifiťe ŗ la mÍme distance du centre si elle est ŗ l'intťrieur d'un mot. Il n'en reste pas moins que, bien que ni un mot ni une lettre ŗ l'intťrieur d'un mot ne puissent Ítre explicitement identifiťs dans la zone parafovťale, puisque la longueur moyenne d'une saccade dťpasse la largeur de l'empan fovťal, l'emplacement d'une nouvelle fixation ne peut Ítre dťterminť que dans la zone parafovťale (Loftus, 1983; Rayner & Pollatsek, 1987) . Il y a environ cent ans, Dodge (1907) a montrť que la prťsentation parafovťale d'un mot accťlŤre sa dťnomination en lecture lorsque ce mot est par la suite fixť dans la fovťa. Ainsi donc, l'exposition parafovťale ne sert pas seulement ŗ dťterminer l'emplacement de la prochaine fixation elle fournit ťgalement des renseignements sur le mot.
Quelle est la nature de ces renseignements et en quoi consiste le traitement effectuť en vision parafovťale ťtaient des questions qui ont acquis ŗ ce stade une importance primordiale. Sur le plan physique, la vision parafovťale est caractťrisťe par une faible rťsolution spatiale, de sorte qu'elle ne permet pas l'analyse d'un dťtail interne ŗ une forme (e.g. une lettre dans un mot). Cette faible rťsolution spatiale convient toutefois parfaitement pour caractťriser grossiŤrement une forme globale (e.g. un mot). D'un autre cŰtť, la vision fovťale dont la sensibilitť spatiale convient trŤs bien pour caractťriser finement un ťlťment local (e.g. une lettre) intervient normalement ŗ la suite du traitement parafovťal et en gťnťral (sauf refixation du mot ŗ un autre endroit) ne couvre qu'une partie du mot fixť. M'appuyant entre autres sur ce raisonnement, j'ťtais arrivť ŗ la conclusion qu'un traitement infra-lexical partiel intervient localement ŗ la suite du traitement global et en fonction de celui-ci. Ce qu'il fallait spťcifier avant tout ťtait la nature du traitement global qui semblait intervenir en premier lieu. Sans aborder cette question sur le plan phťnomťnologique, ŗ savoir ce qui permet au sujet d'identifier explicitement un mot ou du moins lui procure la vision du mot, cette notion de traitement global antťrieur ŗ un traitement local partiel et fin paraissait paradoxale. En effet, si un traitement global du mot permet de caractťriser ce dernier pourquoi revenir pour traiter localement une partie de ce mot? La seule solution logique [52] semblait supposer que le traitement global ne permet pas de caractťriser complŤtement le mot. Cette proposition s'inspirait d'ailleurs des expťriences de Dodge et d'autres travaux plus contemporains du mÍme genre (Rayner, McConkie, & Ehrlich, 1978) , qui montraient que la vision parafovťale d'un mot accťlŤre son traitement lorsque ce dernier est par la suite fixť au niveau de la fovťa.
--- page 32---
8. Catťgorisation globale- discrimination localeIl paraissait alors intťressant d'ťlargir le champ de recherches sur la lecture ŗ la reconnaissance automatique de l'ťcriture manuscrite (reconnaissance off-line ) [53] en dťfinissant un systŤme de reconnaissance basť sur une analyse de la forme globale des mots et sur quelques algorithmes morpho-syntaxiques et sťmantiques. Outre d'aborder un problŤme non rťsolu dans le domaine de la reconnaissance des formes sur ordinateur, cette dťmarche prťsentait ŗ mes yeux l'avantage de devoir spťcifier ce que l'on entend par traitement global de la forme du mot d'une faÁon suffisamment prťcise pour que ce traitement puisse Ítre implťmentť sur ordinateur. L'idťe d'associer le traitement de la forme globale, morpho-syntaxique et sťmantique s'appuyait sur la constatation que les dyslexiques profonds, incapables de reconnaÓtre les lettres, sont nťanmoins capables de lire certaines classes grammaticales de mots sans faire beaucoup de confusions visuelles (du genre vison -> vision ) mais ťventuellement des erreurs sťmantiques (cf. ci-dessus). Le traitement global des mots semblait ainsi Ítre associť ŗ des traitements syntaxiques et sťmantiques (cf. Parisse, 1987).
Avec deux ťtudiants en thŤse, Christophe Parisse et Abdelmalek Imadache, nous nous sommes engagťs dans la rťalisation matťrielle du projet. TrŤs rapidement, nous nous sommes heurtťs au problŤme du traitement de la forme ťminemment variable que constitue le tracť d'un mot manuscrit, forme de surcroÓt informativement trŤs pauvre. Les premiers essais nous ont conduits ŗ comprendre que le postulat d'une reconnaissance globale cachait une montagne et qu'il ťtait impossible, vu la complexitť et la variabilitť du signal ťcrit, de pouvoir directement caractťriser un mot en s'appuyant sur l'ensemble de ses propriťtťs spatiales. Il faut en effet souligner que les mťthodes mathťmatiques globales (par exemple, les transformations Karhunen-Loeve, Fourier ou Hadamard) s'appliquent trŤs mal ŗ la dimension spatiale ou, plus exactement, sont trop sensibles aux variations locales. Il est donc devenu clair que pour pouvoir analyser d'une faÁon globale une forme non gťomťtrique, sans avoir au prťalable une idťe sur l'identitť de cette forme, il est nťcessaire de tailler dans ses propriťtťs spatiales (ou dans sa description topologique). Il fallait donc passer impťrativement par une simplification relativement grossiŤre des mots ťcrits afin de pouvoir procťder ŗ une premiŤre catťgorisation de ces mots. Cette catťgorisation prťliminaire pouvait alors Ítre complťtťe par des traitements d'un autre type, non plus globaux mais locaux. L'implťmentation d'une mťthode de simplification du tracť, qui consistait ŗ approximer d'une faÁon relativement grossiŤre le contour extťrieur des mots (voir les profils grossiers dans Figure 2 et 3), a permis d'obtenir des rťsultats d'une qualitť tout ŗ fait inattendue, justifiant a posteriori l'approche adoptťe (ce travail a ťtť dťtaillť dans la thŤse de doctorat de Parisse soutenue en 1989 [54] et dans Parisse, 1996) .
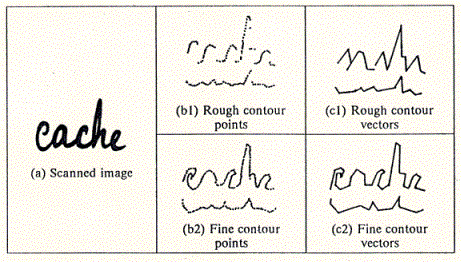
Figure 2.
Exemples de traitements rťalisťs sur le mot manuscrit 'cache'
saisi au scanner.
La colonne du milieu montre les points du
contour supťrieur et infťrieur selon la finesse
de la
rťsolution (grossiŤre en haut, fine en bas) choisie, la
colonne de droite montre les profils vectorisťs
utilisťs.
.
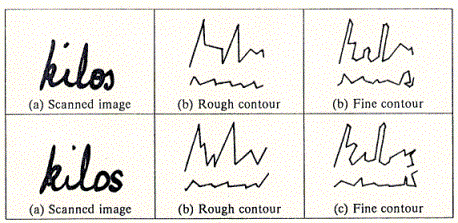
Figure 3.
Comparaison de deux occurrences du mot manuscrit 'kilos'
et
des profils grossiers (colonne du milieu) ou fins (colonne de
droite) obtenus.
Ainsi donc est apparue la solution du paradoxe du traitement global et une explication fonctionnelle des traitements rťalisťs en vision parafovťale. Avec une faible rťsolution spatiale, on nťglige naturellement les variations locales non substantielles. Cette faible rťsolution convient cependant trŤs bien pour catťgoriser grossiŤrement la forme globale et dťtermine ipso facto les parties de cette forme qu'il est utile d'examiner d'une faÁon plus fine pour identifier cette forme. Nous avons postulť un principe gťnťral sous-tendant la perception de l'ťcrit (et sans doute de portťe plus gťnťrale) aux termes duquel la catťgorisation des mots sur la base d'une approximation grossiŤre de leur forme globale est complťtťe logiquement par une discrimination locale orientťe par les propriťtťs catťgorielles de ces mots (Parisse et al., 1990) . Un concept relativement analogue a ťtť par la suite proposť par Sanocki (1993) .
Le principe catťgorisation sur la base d' approximation globale suivi de discrimination au moyen de vťrification locale offre une explication fonctionnelle de ęlaprťcťdence perceptive' de l'information globale par rapport ŗ l'information locale, souvent rapportťe dans la littťrature mais aussi souvent contestťe, faute de justification fonctionnelle satisfaisante (cf. Kimchi, 1992; Navon, 1977; Peressotti & Job, 1991) . En effet, cette succession dans le temps ne s'explique pas tout simplement par une diffťrence d'ťchelle (global vs. local), car une diffťrence d'ťchelle n'implique pas un ordre temporel. Elle ne peut s'expliquer que par les discontinuitťs structurelles correspondant aux diffťrences de la nature du traitement, tant sur le plan de l'objectif recherchť que sur le plan qualitatif [55] .
Ce principe ne peut de toute ťvidence Ítre spťcifique au traitement de l'ťcrit et semble instancier plus gťnťralement la structure du traitement visuel des formes (Navon, 1977; Navon, 1991; Sanocki, 1993) . Il paraÓt d'ailleurs inconcevable qu'une telle structure fondamentale sur le plan fonctionnel ne soit pas sous-tendue par une organisation neurophysiologique et anatomique compatible. Les ťtudes anatomiques et physiologiques des voies magnocellulaire (M) et parvocellulaire (P) montrent, en effet, que l'information rťtinienne est traitťe ŗ deux reprises et d'une faÁon non redondante (cf. Lehmkuhle, 1993) . Il faut rappeler que les cellules M sont plus rapides que les cellules P, en raison de leur plus large diamŤtre axonal et que chacun des deux systŤmes ťchantillonne l'image rťtinienne avec une rťsolution diffťrente. La voie M, dont le champ rťceptif est plus vaste et qui est plus sensible aux faibles frťquences spatiales, semble fournir une information spatiale grossiŤre nťcessaire ŗ l'identification des formes ťlťmentaires et ŗ la sťgrťgation figure - fond. La voie P, dont le champ rťceptif est plus ťtroit, est en revanche plus sensible aux hautes frťquences spatiales. Cette voie ťchantillonne l'image rťtinienne avec une meilleure rťsolution, fournissant ainsi des informations sur les dťtails locaux. Il semble donc que la voie M traite rapidement l'information relative ŗ la forme grossiŤre globale et que la voie P traite par la suite l'information relative aux dťtails fins et ŗ la couleur (cf. Leventhal, Rodieck, & Dreher, 1981; Merigan & Maunsell, 1993; Shapley & Perry, 1986) . Autrement dit, la voie M semble fournir une premiŤre dťfinition grossiŤre ou approximative de l'identitť du stimulus et de sa position dans l'espace (ainsi que sur la rťtine), dťfinition suffisante pour guider le traitement parvocellulaire et permettre au systŤme oculomoteur de ęplacer' certaines parties du stimulus sur la fovťa. Par ailleurs, certaines donnťes anatomiques montrent que la voie M peut Ítre sťlectivement atteinte chez les patients prťsentant des troubles acquis (maladie d'Alzheimer et certains cas de glaucome) ou dťveloppementaux de la lecture (Breitmeyer, 1993; Eden, Stein, Wood, & Wood, 1994; Eden, Stein, Wood, & Wood, 1995; Lehmkuhle, 1993; Livingstone, Rosen, Drislane, & Galaburda, 1991; Lovegrove & Williams, 1993; Stein & Talcott, 1999; Stein & Walsh, 1997) .
Sur le plan de l'objectif recherchť, il s'agit d'une part, d'une catťgorisation (ou d'une prť-catťgorisation) de la cible perceptive (approximation globale) et d'autre part, d'une discrimination locale permettant de sťlectionner le bon mot dans un sous-ensemble de candidats possibles (vťrification locale). J'insiste sur cette finalitť, pour souligner que ce n'est pas le caractŤre global ou local qui serait en soi suffisant pour une reconnaissance adťquate. Un dyslexique profond atypique que j'avais ťtudiť avec Martine Dťsi ťtait en mesure d'identifier (au moins implicitement) les lettres et nťanmoins faisait de nombreuses paralexies sťmantiques en lecture de phrases. Ce comportement n'a de sens que si l'on retient, conformťment au principe catťgorisation globale - discrimination locale , la finalitť de chaque opťration. Ainsi, il apparaÓt clair que ce n'est pas en soi la capacitť de reconnaÓtre les lettres (donc d'effectuer un traitement local), mais celle de conduire les vťrifications locales dťterminťes par les approximations qui est nťcessaire pour une lecture correcte.
Sur le plan qualitatif, la succession traitement grossier - traitement fin est motivťe par la nature du problŤme de la reconnaissance des formes non-gťomťtriques (et donc non-dťductibles) et par la prise en compte de la morphologie de la rťtine et de la structure des mouvements oculaires. La catťgorisation globale effectuťe dans la zone parafovťale (ŗ faible dťfinition) dťtermine l'emplacement de la vťrification locale, effectuťe dans la zone fovťale (ŗ haute dťfinition). Ainsi semblent s'expliquer deux ťnigmes : celle de la saccade et, du moins partiellement, celle de la dťtermination de l'emplacement de la fixation par la vision parafovťale (cf. Parisse et al., 1990; Rosenthal, Parisse, & Chainay, soumis) .
Cette structure de traitement oý se succŤdent processus globaux grossiers et locaux fins est d'ailleurs compatible avec des observations concernant le champ visuel de certains dyslexiques. Ces observations portent sur des dyslexiques dont le champ de vision relativement fine est anormalement large, de sorte que leurs champs de vision parafovťale et pťriphťrique sont trŤs excentrťs. Contrairement aux sujets normaux, ces dyslexiques sont capables d'identifier des couleurs ou des lettres isolťes projetťes trŤs loin dans la pťriphťrie de la rťtine; or ils prťsentent de graves difficultťs d'apprentissage de la lecture. Ces difficultťs, surmontables avec une stratťgie impliquant l'utilisation des parties trŤs excentrťes du champ visuel, ce qui induit des mouvements oculaires erratiques et de grande amplitude (Geiger & Lettvin, 1987; Grosser & Spafford, 1989) , ne semblent explicables que si l'on suppose que le champ de la vision assez grossiŤre est fonctionnellement indispensable pour le traitement perceptif au cours de la lecture. L'anomalie de la rťtine qui en apparence confŤre ŗ ces patients des capacitťs visuelles assez exceptionnelles se rťvŤle en fait un handicap pour le traitement perceptif. Ces observations corroborent d'une faÁon particuliŤrement nette le principe structurel impliquant obligatoirement la sťquence catťgorisation globale- discrimination (vťrification) locale.
Le principe catťgorisation globale - discrimination locale comporte aussi un autre postulat important : la vťrification locale est par dťfinition restreinte ŗ la zone du mot (i.e. lettre ou groupe de lettres) qui est morphologiquement critique pour la discrimination, autrement dit la vťrification n'est pas exhaustive mais sťlective . Ainsi donc, contrairement aux modŤles basťs sur le principe du traitement en parallŤle de toutes les lettres (Adams, 1979; Besner, Coltheart, & Davelaar, 1984; Coltheart, 1981; Grainger & Jacobs, 1996; Johnston & McClelland, 1980; McClelland & Rumelhart, 1981) nous avons ťtť amenťs ŗ postuler que seules certaines lettres ŗ l'intťrieur du mot- ŗ savoir les lettres discriminantes par rapport ŗ l'ensemble des mots de la langue ayant la mÍme forme globale- sont rťellement traitťes au cours de la lecture normale. Cela conduit ŗ prťdire que la discrimination locale (au moyen d'une fixation fovťale) porte sur la partie du mot morphologiquement discriminante ou critique.
Cette prťdiction ťtait en accord avec les rťsultats obtenus par Underwood et ses collaborateurs (Everatt & Underwood, 1992; Underwood, Clews, & Everatt, 1990) . Ces auteurs ont contrastť des mots ŗ dťbut ęinformatif' et terminaison īredondante' avec des mots ŗ dťbut īredondant' et terminaison īinformative' et ont montrť, en enregistrant les mouvements oculaires des sujets, que le regard avait tendance ŗ se poser sur la partie īinformative' du mot. Les rťsultats de Underwood n'ont toutefois pas ťtť reproduits par d'autres chercheurs. En particulier, Rayner et Morris (1992) qui ont utilisť la mÍme procťdure et le mÍme matťriel mais avec un appareil d'enregistrement plus prťcis n'ont pas observť d'avantage pour les parties īinformatives' . Un dťbat s'en est suivi dont on trouvera les diffťrents ťlťments dans l'ouvrage ťditť par Underwood (1998) . Il m'est apparu assez rapidement qu'une partie du problŤme rťsidait dans la faÁon fort intuitive dont Underwood dťsignait ce qu'il appelait partie īinformative' ou īredondante' . Une partie du dťbut ou de la fin du mot ťtait informative si aucun autre mot de la mÍme longueur n'avait les mÍmes 4-6 lettres initiales ou finales. Sachant que la partie informative ťtait censťe attirer la fixation, on pouvait lťgitimement se poser la question de savoir en quoi consiste cette informativitť (au niveau fovťal) si la fixation de cette partie du mot ne fournit aucune information discriminante. Bien au contraire, c'est seulement si cette partie partageait des lettres avec d'autres mots de la mÍme longueur que l'on pouvait considťrer qu'il est informatif (sur le plan de la discrimination entre mots semblables) de fixer ce mot. Un autre problŤme avec cette dťmarche rťsidait dans la supposition qu'il est possible de dťterminer ŗ 4Ä ou 5Ä du centre de la fixation qu'un mot partage des lettres avec un autre mot. A cette distance du centre l'acuitť visuelle est insuffisante pour dťterminer des lettres individuelles (Anstis, 1974; Olzak & Thomas, 1986) , en fait seule la forme globale du mot y est accessible. Ce qui a par ailleurs contribuť ŗ la confusion et ťtait ŗ l'origine d'une polťmique (cf. Liversedge & Underwood, 1998; Rayner & Morris, 1992; Rayner, Reichle, & Pollatsek, 1998) c'ťtait l'inconsťquence d'Underwood qui hťsitait entre plusieurs qualifications (sťmantique, orthographique, morphologique) de son concept d'informativitť [56] .
--- page 36---
9. Similaritť orthographiqueLe postulat du traitement sťlectif des lettres au cours de la lecture en fonction de leur caractŤre orthographiquement discriminant instancie le principe thťorique catťgorisation globale - discrimination locale , dans la mesure oý seule une catťgorisation globale du mot permet de dťterminer quelles sont ses lettres discriminantes. Cette dťtermination suppose que la similaritť orthographique est fondťe sur la similaritť des formes globales des mots. Le concept de similaritť orthographique usuellement proposť dans les recherches sur la lecture est fort diffťrent. Le plus connu est celui de la similaritť de voisinage (Landauer & Streeter, 1973) dťfinit par la diffťrence sur une seule lettre entre un mot et d'autres mots de la langue, en respectant les positions des lettres (voir aussi le concept de N-metric Coltheart, Davelaar, Jonasson, & Besner, 1977, qui en est l'expression la plus courante) . Ce concept de similaritť de voisinage (ou de voisinage orthographique) est fondť sur l'idťe que l'identification des mots intervient au niveau d'un code abstrait oý ce qui est pertinent ce n'est pas la forme du stimulus mais les identitťs abstraites des lettres (Adams, 1979; Besner et al., 1984; Coltheart, 1981; Evett & Humphreys, 1981; Saffran, 1980) . La dťfinition du voisinage orthographique ne tient donc aucun compte de la similaritť des formes, celles des mots ou celles des lettres (ainsi table est un voisin orthographique de sable en dťpit de la dissimilaritť de leurs formes globales), elle renvoie seulement de la correspondance de toutes les identitťs des lettres moins une [57] (cf. Massaro & Cohen, 1994) .
Au contraire nous avons dťfini la similaritť orthographique sur la base de la similaritť des formes globale des mots. Dans ce cadre, les mots appartenant ŗ la mÍme classe de formes ne peuvent diffťrer que sur des lettres de forme similaire. Les lettres de forme similaire correspondent aux lettres de la mÍme hauteur qui ne modifient pas la forme globale du mot sur le plan d'une dťfinition spatiale assez grossiŤre (voir aussi Walker, 1987) . La similaritť orthographique correspond ainsi ŗ la similaritť des formes globales des mots au niveau de la dťfinition spatiale qui est insensible aux variations internes des lettres (e.g. concavitť). Les seuls critŤres discriminants sont ici la hauteur de la lettre et sa position (haute, mťdiale, basse) sur l'axe vertical. Nous obtenons ainsi quatre classes de lettres ŗ l'intťrieur desquelles les substitutions sont permises (car elles ne modifient pas la forme du mot). Ces classes comportent les ascendeurs (b, d, f, h, k, l, t), les descendeurs (g, j, p, q, y), les lettres mťdiales (a, c, e, m, n, o, r, s, u, v, w, x, z) et les lettres mťdiales accentuťes (ŗ, ť, Ť, Í, ő, i, Ô, ý, Ł).
A partir de ce concept de similaritť orthographique, nous pouvons dťfinir le caractŤre orthographiquement discriminant d'une lettre par l'existence ou non des mots de la mÍme forme globale relativement ŗ la position de cette lettre (letter slot) dans le mot (ŗ savoir si la substitution de cette lettre par une autre lettre de la mÍme classe crťe un mot du franÁais). Ainsi, par exemple, le s dans ma s que est discriminant et donc critique pour son identification en raison de l'existence de ma r que et ma n que . Ce n'est pas le cas du s dans de s tin car aucune substitution de cette lettre (par une autre lettre de la mÍme classe) ne fera un mot du franÁais.
On notera que cette dťfinition du caractŤre discriminant des lettres n'a de sens dans le cadre de l'hypothŤse du traitement sťlectif des lettres que si le nombre des lettres discriminantes est nettement infťrieur au nombre des lettres dans le mot. Nous avons entrepris une analyse de 24.589 mots du franÁais, ŗ savoir de tous les mots de quatre ŗ dix lettres de la base des donnťes BRULEX (Content, Mousty, & Radeau, 1990) qui contient le dictionnaire des frťquences des mots franÁais (Imbs, 1971) , afin de disposer de donnťes statistiques sur la distribution des formes lexicales (en fonction de nos quatre critŤres) et sur la discriminabilitť des positions des lettres ambiguős. Les seuls mots exclus de l'analyse ťtaient ceux qui commenÁaient par une majuscule et les abrťviations. Le programme recensait d'abord l'ensemble des formes globales et des positions des lettres discriminantes du corpus. Ce premier recensement a montrť que 5891 (23,9%) mots du corpus ont une forme unique (ne partagent leur forme globale avec aucun autre mot). Les analyses de la distribution des formes globales et de la discriminabilitť des positions des lettres ambiguős ont ťtť conduites avec les 18.698 mots qui partagent leur forme globale avec d'autres mots. Les rťsultats peuvent Ítre rťsumťs comme suit : 8878 (47,5%) de ces mots peuvent Ítre identifiťs en vťrifiant une position de lettre ambiguő, 13.128 (70,2%) de ces mots peuvent Ítre identifiťs en vťrifiant jusqu'ŗ deux positions de lettre ambiguős et 15.813 (84,6%) mots, en rťsolvant jusqu'ŗ trois positions de lettre ambiguős. Ainsi, ŗ partir de la classification des formes lexicales en fonction de nos quatre critŤres, prŤs de 50% des mots du franÁais qui ont une forme globale ambiguő (ŗ savoir, qui partagent leur forme globale avec d'autres mots) peuvent Ítre identifiťs avec la vťrification d'une seule position de lettre ambiguő et plus de 70%, de deux positions [58] . Ces taux d'identification seraient encore plus importants s'ils tenaient compte des mots ŗ forme unique. De plus, si on prend en compte la contribution d'autres sources d'information pertinente (par exemple, syntaxiques, sťmantiques, textuelles, esthťtiques...), pratiquement n'importe quel mot du franÁais est identifiable en contexte avec la vťrification d'une ou tout au plus de deux de ses lettres. Ainsi, l'hypothŤse du traitement sťlectif des lettres en fonction de leur caractŤre orthographiquement discriminant s'avŤre tout ŗ fait intťressante sur le plan du calcul.
Nous avons procťdť ŗ une premiŤre ťvaluation de cette hypothŤse au moyen d'une expťrience de dťtection de lettres (letter cancellation task, voir Healy, 1994, pour plus de dťtail sur cette technique) . Les sujets devaient cocher toutes les occurrences de la lettre s pendant qu'ils lisaient un texte dont ils devaient retenir le contenu. Ce texte comportait entre autres 60 mots-test (mots pleins), dont 30 critiques et 30 non-critiques en ce qui concerne le statut morphologique de la lettre cible s . Ainsi, par exemple, le s dans s apeur et vi s age est critique (ŗ cause de v apeur et vi r age ) et, inversement, le s dans s ource ou de s tin n'est pas critique car aucune substitution de cette lettre par une autre lettre de la mÍme classe ne crťe un mot du franÁais. La variable dťpendante dans cette expťrience ťtait le nombre d'omissions (oubli de cocher) de la lettre cible. Les rťsultats (cf. Figure 4) ont montrť que les sujets omettent deux fois plus de lettres non-critiques que de lettres critiques et cela quelle que soit la position de la lettre dans le mot (1 Ťre , 3 Ťme ou 5 Ťme -7 Ťme ) ou la frťquence du mot [59] . Ainsi donc, les lettres morphologiquement non critiques pour la reconnaissance des mots ne sont pas aussi visibles ou repťrables lors de la lecture que les lettres critiques, et cela malgrť une consigne explicite de cocher toutes les occurrences d'une lettre donnťe. Cet effet de lettre critique corrobore notre postulat sur le caractŤre sťlectif des discriminations locales et, ipso facto , celui de la prťcťdence perceptive de la catťgorisation de la forme globale des mots par rapport ŗ la discrimination locale de certaines de leurs lettres. Comment en effet savoir ŗ l'avance quelle est la zone critique pour la discrimination (sťlective) sans disposer d'hypothŤses sur l'identitť du mot, c'est-ŗ-dire sans l'avoir catťgorisť au prťalable !
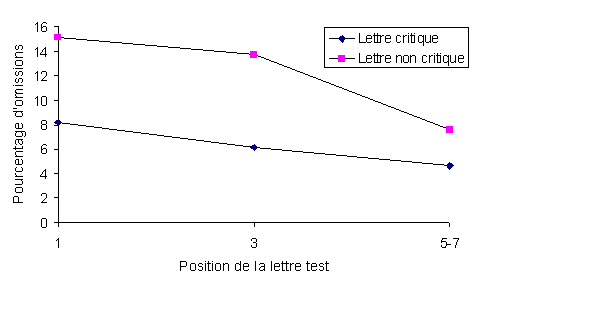
Figure 4.
Pourcentages d'omission de la lettre-cible en fonction de son
statut morphologique
(critique vs. non critique) et de sa
position dans le mot.
Cette premiŤre observation de l'effet de lettre critique n'ťtait pas exempte de quelques interrogations. Tout d'abord, puisque nous avons utilisť des textes rťels, l'on pouvait se demander s'il n'y avait pas de biais induit par le contexte, si par exemple les mots contenant la lettre critique n'ťtaient pas souvent des mots inattendus et les mots contenant la lettre non critique, des mots contextuellement prťvisibles. DeuxiŤmement, nous n'avons observť aucun effet de frťquence lexicale alors que Healy (1976) avait trouvť un lťger effet de frťquence dans une tāche de dťtection de lettres. Healy ťtait certes la seule ŗ avoir trouvť un effet de frťquence dans cette tāche. Toutefois, depuis les premiŤres ťtudes de Solomon et Postman (1952) , la frťquence lexicale est l'un des facteurs les plus ťtudiťs dans les recherches sur la reconnaissance des mots. Ce sont les effets de frťquence lexicale qui ont au dťpart motivť le principe des modŤles de type Ďcriterion bias' (Broadbent, 1967; Morton, 1969) , et la prise en compte de ces effets joue un rŰle important dans plusieurs autres modŤles, y compris des modŤles rťcents (cf. par exemple Grainger & Jacobs, 1996; McClelland & Rumelhart, 1981) . Pour nous, l'absence d'un effet de frťquence dans notre expťrience s'expliquait par deux raisons : (a) les effets de frťquence ne relŤvent que de l'utilisation de mots isolťs, principalement dans des tāches de dťcision lexicale (voir aussi Balota & Chumbley, 1984; Besner & McCann, 1987) oý se crťe une sorte de biais heuristique en faveur des mots frťquents; (b) ces effets ne peuvent intervenir qu'au niveau du mot entier et non pas au niveau de la lettre. Puisque la tāche de dťtection de lettres est censťe sonder l'ťtape de discrimination locale des lettres ambiguős, cette tāche ne devait pas Ítre affectťe par la frťquence lexicale. L'absence de tout effet de frťquence ťtait donc conforme ŗ notre attente. Cependant, compte tenu du rťsultat antťrieur de Healy et du statut des effets de frťquence dans ce domaine nous ne pouvions pas en rester lŗ. Et cela d'autant moins que l'on pouvait se demander si nous avions utilisť des contrastes (entre mots frťquents et non frťquents) suffisants.
L'effet de frťquence qu'avait trouvť Healy (1976) , au demeurant assez lťger, s'ťtait produit dans une tāche de dťtection de lettres dans un assemblage de mots en dťsordre (scrambled text). La divergence entre ses rťsultats et les nŰtres pouvait donc rťsulter de ce fait. Dans notre expťrience les sujets devaient lire attentivement le texte tout en cochant la lettre prť-dťsignťe, or cette tāche dans le cas d'un assemblage de mots en dťsordre, ne requiert pas nťcessairement une discrimination complŤte des mots [60] et est par consťquent plus affectťe par la catťgorisation globale qui s'adresse par dťfinition au format mot.
Afin d'ťvaluer cette explication et partant la question de savoir si l'effet de lettre critique observť dans notre expťrience initiale pouvait Ítre d› ŗ un biais contextuel nous avons repris cette expťrience initiale en mťlangeant les mots de ces textes de maniŤre ŗ les mettre en dťsordre. Cette expťrience utilisait donc le principe de cochage de lettres avec les mots en dťsordre, la tāche des sujets consistant ŗ cocher au fur et ŗ mesure et aussi rapidement que possible toutes les occurrences de la lettre s sans jamais revenir en arriŤre. Les rťsultats ont ŗ nouveau montrť que les sujets omettent presque deux fois plus de lettres non-critiques que de lettres critiques (23,1% vs. 13,9%, F(1,29) = 30,92, p < 0,0001). Cette fois-ci, les lettres tests dans les mots frťquents ont ťtť plus souvent omises que dans les mots peu frťquents (F(1,29) = 4,18, p = 0,05) dans une proportion quasiment identique ŗ celle dťcrite par Healy.
L'effet de lettre critique s'est ainsi avťrť indťpendant du contexte (il n'a pas ťtť "fabriquť" par le hasard de la construction des textes expťrimentaux). L'absence d'un effet de frťquence dans notre expťrience initiale ne pouvait donc pas Ítre attribuťe ŗ la faiblesse du contraste entre les mots frťquents et non frťquents, puisque ce mÍme contraste a permis d'observer un effet de frťquence dans un autre contexte expťrimental. Bien au contraire, conformťment ŗ notre attente, l'effet de frťquence lexicale s'est avťrť Ítre un effet hors contexte. Une comparaison de ces rťsultats avec ceux de l'expťrience initiale a par ailleurs montrť que les sujets ont fait deux fois plus d'omissions dans la condition des mots en dťsordre que dans la condition d'une prose normale [61] (voir Figure 5).
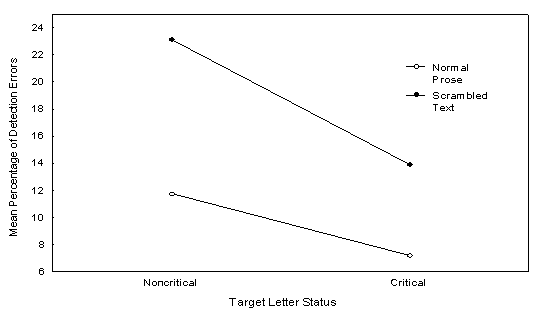
Figure 5.
Pourcentages d'omission de la lettre-cible en fonction de son
statut (critique vs. non critique)
et du type de texte (prose
normale vs. mots en dťsordre).
Ce 'text superiority effect' corrobore le postulat d'une plus grande rťsonance de la catťgorisation globale (et donc du format mot) sur la dťtection de lettres dans le cas d'un assemblage de mots en dťsordre et dťmontre le caractŤre perceptif de l'effet de lettre critique. L'observation que les lettres sont plus visibles ou repťrables dans un texte que dans un assemblage de mots sans aucun sens suggŤre ťgalement que la discrimination locale n'est pas une ťtape obligatoire mais qu'elle dťpend du processus de lecture en cours. Nous y reviendrons plus loin.
La troisiŤme expťrience de cette ťtude avait pour objectif d'ťvaluer notre postulat de l'origine perceptive de l'effet de lettre critique, origine liťe ŗ l'ambiguÔtť des formes globales des mots. Ce postulat dťcoule de notre dťfinition de la similaritť orthographique en termes de similaritť des formes. Cette dťfinition contraste avec celle de la similaritť de voisinage oý le fait d'Ítre des voisins orthographiques est dťterminťe par la possession de toutes les lettres en commun sauf une, que ces mots aient des formes semblables ou non (Coltheart et al., 1977) . Rappelons que le concept de similaritť de voisinage s'appuie sur l'idťe que la reconnaissance des mots intervient au niveau d'un code abstrait et requiert d'une faÁon critique la manipulation d'identitťs abstraites des lettres (Adams, 1979; Besner et al., 1984; Coltheart, 1981; Evett & Humphreys, 1981) . C'est d'ailleurs dans ce cadre que se sont dťveloppťs, au cours des annťes 1990, les travaux sur les effets de la taille du voisinage orthographique et de la frťquence des voisins. Ces travaux ont dťbouchť sur une controverse entre les partisans de la prťťminence de la taille du voisinage avec ceux de la frťquence relative des voisins, controverse qui semble s'alimenter continuellement des rťsultats contradictoires obtenus par les deux camps (cf. Andrews, 1992; Andrews, 1997; Forster & Shen, 1996; Grainger & Jacobs, 1996; Grainger et al., 1989; Grainger et al., 1992; Pollatsek, Perea, & Binder, 1999; Sears, Hino, & Lupker, 1995; Sears, Lupker, & Hino, 1999; Snodgrass & Mintzer, 1993) .
Notre troisiŤme expťrience permettait de confronter ces deux visions de similaritť orthographique tout en ťtudiant en prioritť la question de l'origine (perceptive vs. abstraite) de l'effet de lettre critique : une lettre est discriminante (donc critique) parce que son remplacement par une autre lettre, quelle qu'elle soit, crťe un voisin orthographique de mÍme forme globale ou de forme diffťrente ( orage - otage ); ou une lettre est discriminante parce qu'elle diffťrencie des mots ayant la mÍme forme globale ( percher- pencher ). Pour cela, nous avons ŗ nouveau utilisť la technique de cochage de lettres pendant la lecture d'un texte. Ce texte comportait notammentdes mots :
- oý une substitution de la lettre test ' r ' ne pouvait crťer qu'un mot ayant la mÍme forme globale ( effarer- effacer )- condition de similaritť orthographique;
- oý une substitution de la lettre test ' r ' ne pouvait crťer qu'un voisin orthographique de forme globale diffťrente ( artiste - altiste )- condition de voisinage orthographique;
- oý aucune substitution de la lettre test ' r ' ne crťe un mot de la langue ( horizon - non-mot)- condition de contrŰle.
Les rťsultats ont montrť que la condition de similaritť orthographique diffŤre significativement des deux autres conditions [62] . Les sujets ont fait pratiquement deux fois plus d'omissions de la lettre test dans la condition de voisinage orthographique et dans celle de contrŰle que dans le cas de similaritť orthographique. Les conditions de contrŰle et de voisinage orthographique ont donnť lieu ŗ des taux d'omission quasiment identiques. L'effet de lettre critique ne s'est produit que dans le cas de similaritť orthographique oý la lettre test diffťrencie des mots ayant la mÍme forme globale. Ce n'est donc pas le fait de partager toutes les lettres sauf une qui est pertinent mais le fait de partager la mÍme forme globale. Dans ce dernier cas il existe une ambiguÔtť des formes qui appelle un examen local de la lettre discriminante. Que cette ambiguÔtť des formes globales des mots conduise les lecteurs ŗ porter leur attention sur la lettre qui diffťrencie ces mots, montre la prťcťdence perceptive de la catťgorisation des mots sur la base de leur forme globale par rapport ŗ la discrimination locale de certaines de leurs lettres.
Cette expťrience apporte donc une nouvelle confirmation du traitement sťlectif au cours de la lecture des lettres orthographiquement discriminantes et met en ťvidence l'origine perceptive de l'effet de lettre critique : c'est la similaritť des formes globales des mots qui dťtermine quelles sont les lettres orthographiquement discriminantes. Ce rťsultat devrait permettre ťgalement de mettre un terme ŗ une dťcennie de dťbats et de rťsultats contradictoires concernant les effets de la taille ou de la frťquence du voisinage orthographique. Le concept de voisinage orthographique sur la base du recoupement partiel des identitťs abstraites des lettres conduisait ŗ amalgamer les mots ayant la mÍme forme globale (comme dans la condition de similaritť orthographique) et les mots ŗ forme globale diffťrente (comme dans la condition de voisinage orthographique de notre expťrience). Ainsi, on avait confondu les situations de similaritť orthographique (dont l'effet sur la lecture a ťtť dťmontrť avec les expťriences qui viennent d'Ítre dťcrites) et les situations oý une substitution de lettre change la forme globale du mot (et dont l'effet s'est avťrť Ítre nul). Que cela ait conduit ŗ des rťsultats contradictoires ne devrait guŤre surprendre!
Une derniŤre expťrience dans le cadre de cette ťtude a permis de gťnťraliser l'effet de lettre critique et a montrť qu'il est indťpendant d'une technique expťrimentale donnťe. Dans cette expťrience basťe, sur l'enregistrement des mouvements oculaires, nous cherchions ŗ la fois une dťmonstration plus directe du traitement sťlectif des lettres au cours de la lecture et une indication de ce que le lecteur fixe du regard et pourquoi. Cette expťrience est intervenue sur le fond du dťbat concernant les dťterminants morpho-orthographiques ou purement oculomoteurs des emplacements des fixations dont il a ťtť question plus haut et que rťsume l'ouvrage ťditť par Underwood (1998) . A mes yeux, la dťfinition d'Underwood de ce qui constitue une partie informative du mot ťtait incohťrente et son idťe, que l'on fixe la partie du mot qui ne prťsente aucune ambiguÔtť, n'avait aucune justification fonctionnelle. Ces deux raisons suffisent pour expliquer l'ťchec de Rayner et Morris (1992) ŗ confirmer le rťsultat de l'expťrience initiale d'Underwood et al. (1990) .
Les concepts de similaritť orthographique et d'information discriminative dont le principe a ťtť discutť ci-dessus nous semblent fournir un cadre thťorique et opťratoire plus adťquat pour aborder la question des dťterminants du locus des fixations oculaires. Rappelons que le principe catťgorisation globale - discrimination sťlective locale s'inspire des propriťtťs de l'ķil (notamment de la morphologie de la rťtine) et des caractťristiques du comportement oculaire du lecteur, notamment en ce qui concerne la succession dans le temps de la vision parafovťale et fovťale. En effet, le format de la vision parafovťale est parfaitement adťquat pour une catťgorisation globale du mot sur la base d'une approximation (grossiŤre) de sa forme, et le format de la vision fovťale convient trŤs bien ŗ la discrimination locale fine d'une partie de ce mot. Une telle catťgorisation du mot sur la base de sa forme globale dťtermine ipso facto chez un lecteur qui connaÓt les mots de sa langue quelles sont les lettres qui distinguent ce mot d'autres mots ayant la mÍme forme globale. La vision parafovťale peut donc fournir une information prťcise sur l'emplacement dans le prochain mot dont l'inspection est la plus utile.
Cette proposition revient ŗ postuler que l'exploration parafovťale est sensible aux paramŤtres cognitifs et orthographiques, qu'elle permet de minimiser l'incertitude concernant le prochain mot dans le texte (voir aussi Legge, Klitz, & Tjan, 1997) et que la distribution de l'information discriminative (lettres) dťtermine le locus des fixations oculaires dans les mots dont la forme globale est ambiguő. Cette idťe va ŗ l'encontre de la thŤse de la dťtermination exclusive du locus des fixations par des contingences oculomotrices et les limites de l'acuitť visuelle (McConkie, Kerr, Reddix, & Zola, 1988; Nazir, Jacobs, & O'Regan, 1998; O'Regan & Jacobs, 1992; O'Regan, Levy-Schoen, Pynte, & Brugaillere, 1984; Vitu, O'Regan, & Mittau, 1990) . En particulier, l'idťe d'une position optimale du regard ('optimal viewing position') soutenue par O'Regan et ses collŤgues ne nous semble reflťter que la distribution statistique des lettres orthographiquement discriminantes dans les vocabulaires du franÁais et de l'anglais.
La proposition que les lecteurs fixent les lettres qui sont orthographiquement discriminantes ne semble pas toutefois dťcrire d'une faÁon satisfaisante le comportement oculomoteur au cours de la lecture. D'une part, les lecteurs ne passent pas systťmatiquement les mots ŗ forme globale non-ambiguő, pas plus qu'ils ne fixent tous les mots ŗ forme ambiguő. Plusieurs chercheurs ont en effet observť que la dťcision de fixer [63] un mot est fortement influencťe par le contexte et le processus de comprťhension en cours (Balota, Pollatsek, & Rayner, 1985; Ehrlich & Rayner, 1981; Rayner, 1998) . D'autre part, bien que la vision parafovťale permette toute une sťrie de traitements du mot, elle ne permet pas l'identification consciente de ce mot. Il y a donc une relation entre fixation centrale, discrimination et identification consciente du stimulus. Ainsi, la fixation ne sert pas seulement ŗ diffťrencier les lettres critiques, elle est aussi indispensable pour l'identification explicite du mot. Cela ne veut pas dire que la lecture comporte l'identification explicite de tous les mots. Le prťsent propos est tout simplement que l'identification explicite du mot passe par la fixation, mÍme si ce mot ne prťsente aucune ambiguÔtť morpho-orthographique. Si un mot n'est pas ambigu, il peut Ítre identifiť au moyen d'une fixation ŗ n'importe quelle location.
Ce long prťambule explique le contexte thťorique de notre expťrience. La dťcision de fixer un mot dťpend d'une part du processus de comprťhension en cours. Cette fixation constitue d'autre part le seul moyen d'identifier explicitement un mot au cours de la lecture [64] . La dťcision de fixer un mot rťpond ainsi ŗ un double objectif. Si cette dťcision intervient, les mots ambigus sont fixťs au niveau des lettres discriminantes, tandis que les mots non-ambigus sont fixťs ŗ l'endroit dťterminť par la commoditť oculomotrice.
Le matťriel expťrimental a ťtť, ŗ quelques amťnagements prŤs, le mÍme que dans la premiŤre expťrience de cochage des lettres. Les textes ont ťtť dťcoupťs en lignes ťcran afin de pouvoir les prťsenter ligne par ligne. Le sujet ťtait assis face ŗ l'ťcran de l'ordinateur (50 cm de distance), sa tÍte immobilisťe avec une fixation dentaire, et portait des lunettes munies de capteurs infrarouges permettant d'enregistrer les mouvements de ses yeux et les emplacements prťcis des fixations successives du regard (cf. Rosenthal et al., soumis, pour plus de dťtail) . Trois caractŤres espaces correspondaient dans ce cadre ŗ un degrť d'angle de vision. Nous avons pris comme critŤre de fixation de la lettre-cible (T) Ī 2 caractŤres espaces, ŗ savoir si le point de fixation ťtait sur la lettre-cible ou dans la limite de Ī 2 caractŤres espaces de la lettre-cible nous considťrions que cette derniŤre avait ťtť fixťe, sinon elle ne l'ťtait pas. T Ī 2 est en fait lťgŤrement infťrieur ŗ l'empan thťorique de la vision fovťale, mais cela permet de tenir compte du niveau de bruit du systŤme d'enregistrement. Comme la plupart des auteurs, nous n'avons pris en compte que les fixations ayant durť au moins 100 msec.
Les principaux rťsultats peuvent Ítre rťsumťs comme suit. Globalement, les sujets ont fixť autant de mots-tests comportant une lettre critique (69%) que de mots-test sans lettre critique (71%). La fixation des mots-test au niveau de la lettre-cible se produisait significativement plus souvent si cette lettre ťtait critique (78%) que si elle n'ťtait pas critique (65%) [65] . La Figure 6 montre les probabilitťs de fixer les mots-tests au niveau de la lettre-cible (T Ī 2) en fonction de son statut critique ou non-critique et de sa position dans le mot.
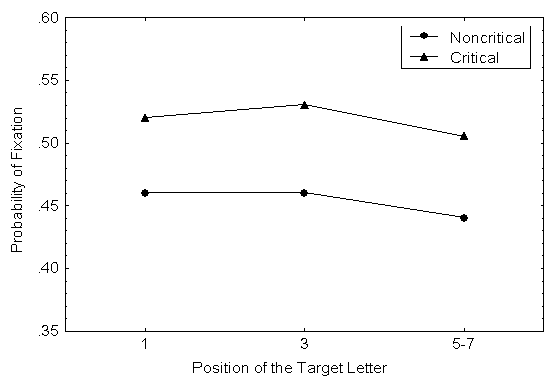
Figure 6. Probabilitť de fixer la zone de la lettre-cible (T Ī 2) en fonction de son statut (critique vs. non-critique) et de sa position dans le mot.
Les statistiques gťnťrales concernant l'ensemble des mots des textes montrent que les sujets ont directement fixť 44% des mots [66] . Les pourcentages de fixations varient en fonction de la longueur des mots (voir Figure 7), allant de 9% et 18% pour les mots ŗ une et deux lettres jusqu'ŗ 95% pour le mot ŗ seize lettres. Ce rapport entre la longueur du mot et la probabilitť de fixation est conforme ŗ d'autres travaux, toutefois nos pourcentages de fixation sont infťrieurs ŗ ceux rapportťs dans ces travaux (cf. Blanchard, Pollatsek, & Rayner, 1989; Rayner & Fischer, 1996; Rayner & McConkie, 1976; Rayner, Sereno, & Raney, 1996; Vitu, O'Regan, Inhoff, & Topolski, 1995) . Vitu et collaborateurs (1995) ont par exemple trouvť qu'en moyenne 58% des mots sont fixťs lors de la lecture de brefs passages de textes (nous ne trouvons que 44%, certes pour des textes plus longs). De plus, ces auteurs ont observť que 90% des mots de sept ŗ dix lettres sont fixťs, alors que nous ne trouvons que 68%.
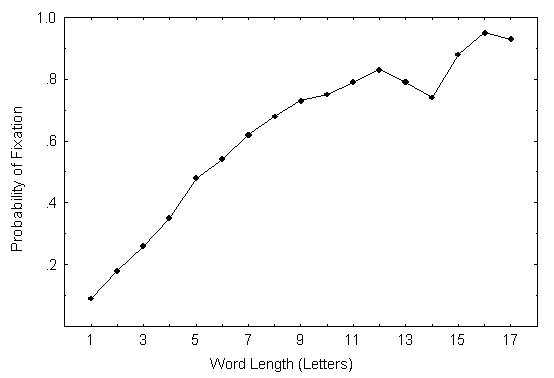
Figure 7 : Probabilitťs de fixer un mot (dans un texte) en fonction de sa longueur
Ces rťsultats jettent un ťclairage sur ce que le lecteur cherche lorsqu'il fixe un mot du regard. Tout d'abord, ils confirment l'existence de dťterminants orthographiques des loci de fixation en montrant un rapport systťmatique entre la distribution des fixations et la prťsence ou l'absence de lettres discriminantes : dans les mots ŗ forme ambiguő les fixations atterrissent dans la zone de la lettre discriminante, dans les mots ŗ forme non-ambiguő les fixations se distribuent sur tout le corps des mots. DeuxiŤmement, ces rťsultats montrent que la probabilitť de fixer un mot ne dťpend pas de son statut sur le plan de l'ambiguÔtť orthographique : les lecteurs fixent aussi souvent les mots ŗ forme ambiguő que les mots ŗ forme non-ambiguő.
L'observation d'un rapport systťmatique entre la prťsence de lettres discriminantes et le locus des fixations ŗ l'intťrieur des mots a d'intťressantes implications thťoriques. Cette observation montre que le traitement effectuť au niveau parafovťal est sensible aux propriťtťs orthographiques [67] des mots et qu'il guide dans une large mesure le mouvement oculaire au cours de la lecture. La dťtermination au niveau parafovťal des emplacements (letter slots) discriminants dans les mots ŗ forme globale ambiguő dťmontre qu'une catťgorisation de ces mots, sur la base de variations spatiales suffisantes pour caractťriser le contour externe des mots mais insuffisantes pour leurs propriťtťs internes (lettres), a pu avoir lieu. En effet, il ne faut pas perdre de vue que ce qui dans notre exposť correspond ŗ une ambiguÔtť orthographique ou ŗ un 'letter slot discriminant' n'est ambigu ou discriminant que par rapport ŗ une catťgorisation de la forme des mots sur la base des variations globales de leur contour externe. Ainsi, l'observation de l'effet de lettre critique dans la distribution des loci des fixations du regard sur les mots au cours de la lecture corrobore directement la thťorie de l'organisation perceptive en termes de catťgorisation de la forme globale suivie de discrimination sťlective locale .
D'un autre cŰtť, ces rťsultats montrent que la discrimination n'est ni une ťtape obligatoire ni qu'elle est nťcessairement motivťe par l'ambiguÔtť des formes lexicales. Les probabilitťs de fixation et les taux de fixation des mots dans nos textes montrent que la dťcision de fixer un mot est dťterminťe ŗ la fois par les impťratifs liťs ŗ l'interprťtation du texte en cours de dťploiement (voir aussi Balota et al., 1985; Ehrlich & Rayner, 1981; Rayner & Well, 1996) et par l'attitude phťnomťnologique du lecteur. Par attitude phťnomťnologique il faut entendre la dťcision du lecteur d'identifier consciemment le mot, car, faut-il le rappeler, seule une fixation semble permettre l'identification consciente d'un mot. Je n'ai pas d'explication satisfaisante de ce besoin d'identifier explicitement certains mots. La perception explicite thťmatise certains items du champ de la conscience [68] et ŗ ce titre la dťcision d'identifier un mot- et donc de thťmatiser ce qu'il signifie Ė relŤve du processus d'interprťtation du texte. Cela confŤre ŗ la conscience un rŰle structurel dans la comprťhension du langage, un rŰle dont il serait vain de chercher une mention dans les manuels de psycholinguistique (voir par exemple le trŤs complet handbook ťditť par Gernsbacher, 1994) .
Le fait de trouver que seul un mot sur deux [69] a ťtť fixť dans cette expťrience montre que l'information d'origine parafovťale n'est pas dťnuťe de sens, qu'elle en est au contraire suffisamment īimprťgnťe' pour contribuer ŗ l'interprťtation [70] du texte. Ce sens est sans doute partiel et mal diffťrenciť par rapport ŗ une dťfinition de dictionnaire du mot, mais mÍme incomplet et tacite ce sens contextuellement situť s'avŤre suffisant et appropriť pour contribuer ŗ l'interprťtation du texte dont le mot fait partie. On a abusivement identifiť le sens avec ce qui est explicite, articulť et dťfini, bref avec ce qui caractťrise une expťrience consciente d'un objet dťfini [71] . L'analyse du comportement oculaire des sujets au cours de la lecture suggŤre au contraire que le sens prťsente les mÍmes caractťristiques microgťnťtiques que les formes qui le recŤlent. Loin d'Ítre dťtachable de la forme qu'il signifie et qui le rťvŤle, le sens semble accompagner la microgenŤse perceptive de cette forme et emprunter son parcours de diffťrenciation du gťnťral et sous-dťterminť vers le spťcifique et dťfini.
![]()
NOTES
[45] Ne serait-ce sur la perception du langage, et qui dit perception dit ťgalement interprťtation.
[46] Comme en tťmoignent les exemples de segmentations alternatives du flux verbal prťsentťs dans le chapitre consacrť ŗ la catťgorisation lexicale. Les chansons de Bobby Lapointe ( Mon pŤre et ses vers ont les pieds fragiles ..) jouent souvent sur les dťcoupages alternatifs du flux verbal. Ce phťnomŤne, si imperceptible dans sa langue maternelle devient tout ŗ fait perceptible lorsqu'on ťcoute une langue qu'on maÓtrise mal.
[47] Cette sťparation physique des mots est intervenue trŤs tardivement dans l'histoire du langage ťcrit, principalement avec la gťnťralisation de l'imprimerie et la dťmocratisation de l'accŤs ŗ l'ťcrit. MÍme au cours des premiers siŤcles de l'imprimerie la sťparation des mots n'intervenait pas systťmatiquement ou alors en obťissant davantage ŗ des impťratifs typographiques qu'ŗ l'objectif de sťparer les mots par des blancs.
[48] Voir Scheerer (1981) au sujet de la rťaction de Wundt.
[49] Sťquences de lettres qui ne constituent pas des mots de la langue mais qui respectent les rŤgles morpho-phonologiques et orthographiques de la formation des mots, comme par exemple mirpe .
[50] Cela vaut ťgalement pour les modŤles dits ŗ double voie qui postulent l'existence d'un module de reconnaissance (globale) de mots- tels les logogens de Morton (1969; Patterson & Morton, 1985) - et d'un module de conversion des graphŤmes en phonŤmes qui prťsuppose donc au prťalable la reconnaissance des lettres. Tous ces modŤles s'inspirent du dispositif postulť initialement par Morton et se focalisent davantage sur les questions relatives ŗ la conversion ťcrit-oral qu'ŗ la reconnaissance visuelle. Tous dťbutent la description de la conversion ťcrit-oral avec les rťsultats des analyses visuelles dont ils ne spťcifient pas la nature (Coltheart, 1981; Coltheart, Curtis, Atkins, & Haller, 1993) .
[51] Voir note (pages prťcťdentes).
[52] Sans recourir ŗ l'idťe de la redondance du traitement perceptif.
[53] Il s'agit par exemple de convertir automatiquement le texte d'une feuille manuscrite (saisie au scanner) en document texte informatique pouvant Ítre affichť ŗ l'ťcran avec les caractŤres systŤme de l'ordinateur (et non en tant qu'image), repris avec un traitement de texte ou imprimť. La reconnaissance off-line de l'ťcriture manuscrite a peu ŗ voir avec la reconnaissance on-line oý le texte manuscrit est saisi au fur et ŗ mesure de l'ťcriture sur une tablette graphique. Dans ce dernier cas ce qui est analysť ce ne sont pas les propriťtťs spatiales d'une forme graphique (mot) mais la sťquence et l'amplitude des mouvements du graphiste. La reconnaissance de l'ťcriture manuscrite ne peut Ítre abordťe avec les logiciels OCR (Optical Character Recognition) dont le principe est fondť sur un simple pattern-matching- principe tout ŗ fait utilisable dans le cas des formes trŤs rťguliŤres de l'imprimť.
[54] (Parisse, 1989) . La thŤse d'Imadache, soutenue en 1990, portait sur la gťnťration automatique, ŗ partir d'un ťchantillon, des propriťtťs d'une ťcriture donnťe sur un grand lexique. Ce travail basť sur la mťthode d'approximation des contours et indispensable pour la poursuite de ce programme est plus spťcifiquement liť ŗ la reconnaissance automatique de l'ťcriture manuscrite.
[55] Par ailleurs il faut noter que les propriťtťs de l'entrťe se dťfinissent d'une faÁon diachronique au fur et ŗ mesure du traitement. Ainsi toutes les propriťtťs physiques du signal ne constituent pas l'entrťe initiale du systŤme. Seules certaines de ces propriťtťs constituent l'entrťe initiale, d'autres propriťtťs ne seront accessibles qu'ŗ des stades ultťrieurs (et certaines ne sont probablement jamais traitťes).
[56] Si je dťcris avec autant de dťtails le travail d'Underwood et le dťbat qui s'ensuivit c'est qu'aux yeux de nombreux chercheurs il en est rťsultť que l'emplacement des fixations fovťales n'est dťterminť que par des contingences oculomotrices, et que les propriťtťs orthographiques, morphologiques ou sťmantiques du prochain mot n'y joue aucun rŰle.
[57] Nous n'abordons pour l'instant que le concept de voisinage orthographique et non pas les travaux sur les effets du voisinage orthographique (cf. Andrews, 1992; Grainger, O'Regan, Jacobs, & Segui, 1989; Grainger, O'Regan, Jacobs, & Segui, 1992) sur lesquels nous reviendrons plus tard.
[58] Il est ŗ noter que la longueur moyenne des mots du franÁais hors contexte est d'environ 8,4 lettres et la longueur moyenne des mots dans un texte se situe entre 5,5 et 6 lettres. Cette diffťrence s'explique par la frťquence d'usage d'articles, prťpositions, pronoms et conjonctions qui sont en gťnťral des mots courts.
[59] L'effet global : F(1,53) = 25,03, p < 0,0001. 1 Ťre position : F(1,53) = 14,57, p < 0,0001; 3 Ťme position : F(1,53) = 14,75, p < 0,0001; 5 Ťme -7 Ťme position : F(1,53) = 4,10, p < 0,05.
[60] Il est difficile de lire rťellement quelque chose qui n'a pas de sens.
[61] 18,5% vs. 9,48%; F(1,60) =10,2, p <0,005.
[62] Similaritť (7,08) vs. voisinage (13,96), F(1,23) = 8,87, p < 0,01; similaritť (7,08) vs. contrŰle (13,34), F(1,23) = 17,78, p < 0,001.
[63] Il s'agit de la īdťcision' de fixer un mot et non pas du locus de la fixation dans ce mot.
[64] Ce qui ne signifie pas qu'un mot non fixť ne pŤse pas son poids dans le processus d'interprťtation.
[65] F(1,19) = 13,45, p < 0,002.
[66] Ce pourcentage direct ne tient pas compte des rťgressions ni des fixations sur les blancs entre les mots.
[67] La dťtermination des mots ŗ forme ambiguő et des 'letter slots discriminants' ne pourrait avoir lieu sans une mise en ķuvre des connaissances orthographiques du lecteur.
[68] Par exemple au sens que Gurwitsch a donnť ŗ ces concepts. Voir Thťorie du champ de la conscience (Gurwitsch, 1957) .
[69] Deux mots sur trois en ce qui concerne les mots de sept ŗ dix lettres (c'est-ŗ-dire essentiellement des mots pleins).
[70] Cette interprťtation (au sens conventionnel de tout ŗ l'heure) a ťtť au demeurent d›ment attestťe comme correcte au moyen d'un questionnaire.
[71] Le dťbat concernant la question de savoir si les sujets īaccŤdent' au sens des mots en vision parafovťale illustre bien ce propos (Inhoff & Rayner, 1980; Rayner & Morris, 1992) . Si on prÍte quelque crťdit ŗ notre propos, la rťponse devrait Ítre ŗ la fois oui et non, du moins tant que le verbe 'accťder' n'est pris que dans une acception trŤs gťnťrale plutŰt que comme dťnotant un processus psychologique spťcifique. A la question de savoir si une forme lexicale catťgorisťe en vision parafovťale a un sens, il est clair que la rťponse est oui. Ce sens est toutefois trop gťnťral et indťfini pour pouvoir Ítre considťrť comme le sens du mot en question.