|
|
Pascal Vaillant PVI : PROTHČSE VOCALE INTELLIGENTE
La langue dans laquelle les messages sont générés est modélisée par un « lexique-grammaire » qui englobe tant l'information lexicale que l'information grammaticale servant ŕ la production de phrases.
Le formalisme utilisé pour la représentation est celui des grammaires d'arbres adjoints (ou « TAG » : Tree Adjoining Grammar ) [Joshi et coll. 1975; Abeillé 1993]. Chaque entrée lexicale est représentée dans ce formalisme par au moins un arbre élémentaire dont l'une des feuilles, appelée l'ancre , est instanciée. Cette ancre correspond ŕ l'élément lexical : c'est le mot français qui exprime cette entrée. L'arbre syntaxique élémentaire au sein duquel elle s'inscrit correspond ŕ la tournure en laquelle elle s'emploie. Ainsi aucun lexčme n'est-il représenté dans le dictionnaire sans un minimum d'information sur les structures grammaticales dans lesquelles il s'insčre.
Un exemple minimal d'arbre élémentaire correspondant ŕ une entrée lexicale est montré fig. 12. Il s'agit du groupe nominal lexicalisant le concept ' papa '.
|
|
Tous les exemples ne sont pas aussi simples que celui qui précčde. L'intéręt de stocker l'information lexicale dans des arbres syntaxiques est de disposer, au niveau męme de l'entrée lexicale, de la connaissance sur la façon dont la langue opčre pour exprimer les relations microsémantiques du sémčme avec son contexte.
Il s'agit en somme de répondre ŕ la question suivante : connaissant un concept, comment l'exprimer dans un syntagme français correct ; et si ce concept est prédicatif, comment exprimer dans un syntagme français correct ce concept et ses relations actancielles ?
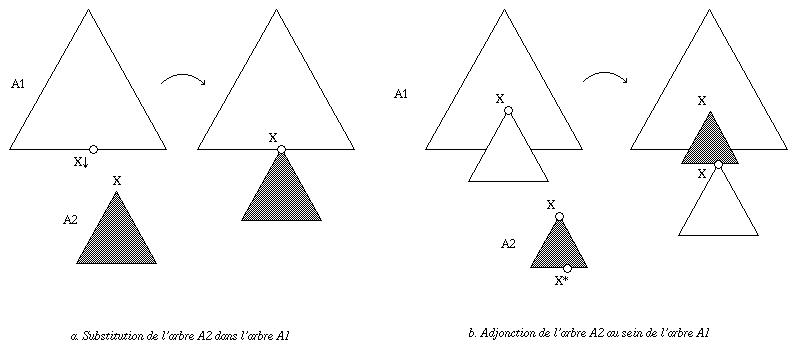
Les arbres élémentaires correspondant ŕ des sémčmes prédicatifs contiennent la réponse ŕ cette question sous la forme de noeuds non instanciés qui peuvent s'unifier avec des syntagmes correspondant aux actants. L'opération d'unification mise en oeuvre est appelée substitution (fig. 13.a).
|
Ainsi le sémčme ' donner ' s'exprime-t-il souvent en français par le verbe " donner " [4] dans une tournure du type : « X donne Y ŕ Z » ; oů X, Y et Z sont des groupes nominaux exprimant respectivement l'actant agent , l'actant objet et l'actant récepteur du sémčme. L'entrée du lexique correspondant ŕ cette tournure est l'arbre élémentaire représenté fig. 14.
![[P: [GN: ?(agnt)][GV: [V: DONNER][GN: ?(objt)][GP:
[Prep: Ŕ][GN: ?(rcpt)]]]]](tagdonne.gif)
|
Si l'agent de " donner " se trouvait ętre " papa ", une unification de l'arbre élémentaire exprimant " papa " (dont la tęte est un noeud de type GN) serait possible avec le GN non instancié correspondant ŕ l'agent, X, dans l'arbre fig. 14. L'opération de substitution , ŕ partir de ces deux arbres élémentaires, donnerait alors l'arbre représenté fig. 15.
![[P: [GN: PAPA][GV: [V: DONNER][GN: ?(objt)][GP: [Prep:
Ŕ][GN: ?(rcpt)]]]]](tagpadon.gif)
|
Le lexique contient parfois plusieurs arbres élémentaires pour une seule entrée ; ces différents arbres correspondent ŕ des tournures différentes en lesquelles le sémčme peut se lexicaliser. Ainsi les deux arbres rangés sous l'entrée " voir " (fig. 16.a. et b.) permettent-ils d'exprimer tous deux le sémčme " voir " avec un agent et un objet ; mais le premier convient ŕ un objet pouvant s'exprimer sous forme de groupe nominal (par exemple « Papa voit le chat »), tandis que le second convient ŕ un objet pouvant s'exprimer sous forme de phrase (par exemple « Papa voit que le chat mange »).
![a. [P: [GN: ?(agnt)][GV: [V: VOIR][GN: ?(objt)]]] ; b.
[P: [GN: ?(agnt)][GV: [V: VOIR][PS: [Conj: QUE][P: ?(objt)]]]]](tagvoir.gif)
|
Ce modčle de stockage lexicalisé des connaissances grammaticales réemploie deux fois une information quasiment identique lorsque deux verbes, par exemple, s'expriment avec la męme tournure (« X donne Y ŕ Z », « X pręte Y ŕ Z »). Mais vue la disponibilité immédiate de l'information qu'il apporte, il ne pourrait devenir rentable de tenter de faire des économies sur ce point que si l'on avait ŕ gérer d'importantes classes de verbes ŕ emploi similaire. Ce n'est pas le cas dans l'application PVI.
Le modčle TAG prévoit une opération d'unification complexe capable de rendre compte des modifications et des ajouts : l' adjonction [Abeillé 1993]. Cette opération consiste en quelque sorte en deux substitutions simultanées ; plus précisément, elle permet d'intercaler un arbre, dit auxiliaire , au niveau d'un noeud intermédiaire d'un arbre syntaxique. La tęte de l'arbre auxiliaire s'unifie au niveau de ce noeud intermédiaire, tandis qu'en un noeud particulier, le pied de l'arbre auxiliaire, se rebranche la partie de l'arbre d'origine située en aval du noeud intermédiaire (fig. 13.b).
La modélisation sous forme d'arbres élémentaires auxiliaires convient particuličrement aux entrées lexicales qui ne constituent pas en elles-męmes des tętes sémantiques, mais qui apportent juste une modification ŕ un autre sémčme : adverbes, adjectifs ... Ainsi l'arbre élémentaire correspondant ŕ " peut-ętre " est-il représenté fig. 17.
![[V: [V: *(pied)][Adv: PEUT-ĘTRE]]](tagptetr.gif)
|
Dans le cas des adjectifs, on peut trouver sous la męme entrée lexicale ŕ la fois un arbre élémentaire « initial », utilisé lorsque l'adjectif est la tęte sémantique d'une phrase, (fig. 18.a), et un arbre élémentaire auxiliaire, utilisé lorsque l'adjectif n'est le modifieur d'un actant plus important dans le message (fig. 18.b).
![a. [P: [GN: ?(qual)][GV: [V: ĘTRE][Adj: GENTIL]]] ; b.
[N: [Adj: GENTIL][N: *(pied)]]](taggenti.gif)
|
Il convient de noter que notre modčle du lexique TAG n'est pas entičrement lexicalisé, contrairement ŕ ceux que Schabes ou Abeillé utilisent pour l'analyse [Schabes et coll. 1988]. Il contient des arbres non-terminaux que nous utilisons pour factoriser des tournures grammaticales systématiques ; ainsi le complément instrumental peut, dans le cas général - s'il n'est pas spécifié dans l'arbre élémentaire du verbe auquel il s'applique - s'exprimer par un groupe prépositionnel « avec X ». Cette tournure est représentée dans le lexique par l'arbre de la figure 19, auquel le groupe nominal complément d'instrument est substitué (noeud en bas ŕ droite), tandis que l'arbre dérivé est lui-męme adjoint ŕ un autre arbre, au niveau du noeud correspondant au prédicat.
![[GV: [GV: *(pied)(prédicat)][GP: [Prep: AVEC][GN:
?(instr)]]]](tagavec.gif)
|
De męme, au cours de la génération, il est possible qu'un prédicat, considéré comme annexe relativement ŕ un autre, et normalement exprimable par un arbre P (phrase) complet uniquement, vienne s'adjoindre sous la forme d'une proposition subordonnée relative enchâssée dans un groupe nominal ŕ la phrase du prédicat « principal ». Ceci est rendu possible par l'existence de procédures de transformation réguličre d'arbre P en arbre CP (complément propositionnel), du type :
| « le chat mange la viande » | --> | « [le chat] qui mange la viande » | |
| « le chat mange la viande » | --> | « [la viande] que le chat mange » |
Nous reviendrons sur ces mécanismes en § 4.2.2. Il reste que ce lexique TAG non entičrement lexicalisé se révčle d'une particuličre souplesse pour les besoins d'un module de génération.
Les mécanismes d'unification de traits proposés dans le modčle TAG n'ont pas été ici implantés rigoureusement. Les phénomčnes d'accord sont implantés de façon plus « efficace », mais moins « propre », sous la forme de buts PROLOG gelés ([PrologIA 1993], § 2.2, p. R 2-9).
Un but gelé, en PROLOG, est un but qui conditionne le résultat final du but qui l'appelle, mais qui n'entrave pas le déroulement de la résolution des buts suivants. Il reste en attente de résolution tant qu'une certaine variable, que l'on précise lors de l'appel, n'est pas instanciée. Lorsque la variable s'instancie, la résolution du but reprend normalement, et conduit ŕ une réponse définitive (solutions possibles ou échec).
Le but gelé permet donc en quelque sorte de fournir une instruction au systčme, en lui laissant la possibilité de ne s'en préoccuper que lorsqu'il aura réuni les données suffisantes pour le faire.
Dans le cas qui nous intéresse, les rčgles d'accord sont codées sous la forme de conditions posées ŕ l'émergence męme d'une solution au prédicat de base de données. Ainsi, alors qu'un arbre initial simple, comme celui de " papa " (fig. 12), est une solution inconditionnelle au prédicat de base de données arbre :
arbre(<lex_papa,n>,<<GN,
<<Nom,<lex_papa,n>>>>,
nil>) ->;
un arbre initial, en revanche, qui subordonne des groupes devant s'accorder, sera codé avec une condition gelée (donc en partie droite de la clause de Horn) correspondant ŕ l'instanciation de l'accord. Ainsi pour " donner " (fig. 14) :
arbre(<lex_donner,n>,<<Ph,
<<GN,_n0>,
<GV,
<<Vb,<lex_donner,n>>,
<GN,_n1>,
<GP,_n2>>>>>,
<agent,<GN,_n0>>.<objet,<GN,_n1>>.<recepteur,<GP,_n2>>.nil>)
->
freeze(_n0,nominatif(_n0))
freeze(_n1,accusatif(_n1))
freeze(_n2,datif(_n2))
freeze(_n0,accord(<GN,_n0>,<Vb,<lex_donner,n>>));
On voit dans cet exemple quatre buts gelés :
freeze(_n0,nominatif(_n0))
freeze(_n1,accusatif(_n1))
freeze(_n2,datif(_n2))
correspondent ŕ des rčgles de sélection de cas syntaxiques qui ne servent bien entendu, en français, qu'aux pronoms. Ainsi nominatif, accusatif, datif, s'appliquent-ils trivialement ŕ tout groupe nominal composé d'un substantif, mais déterminent en revanche, quand il s'agit par exemple du pronom personnel de la premičre personne du singulier, respectivement les formes « je », « me », et « me ». Ces buts dépendent de l'instanciation des variables correspondant aux noeuds GN ŕ substituer.
freeze(_n0,accord(<GN,_n0>,<Vb,<lex_donner,n>>))
correspond ŕ l'accord du verbe avec le sujet. Il dépend de l'instanciation de la variable correspondant au groupe nominal sujet. Lorsque celui-ci s'instancie (c'est-ŕ-dire lorsque l'opération de substitution est effectuée sur ce noeud), la résolution de ce but accord est relancée. Elle va aboutir ŕ aller chercher les traits morphosyntaxiques nombre et personne du GN sujet, et ŕ les instancier ainsi pour le verbe.
La rčgle accord/2 est une rčgle complexe, qui s'oriente vers des actions différentes selon qu'il s'agit d'accorder un verbe avec un nom, un adjectif avec un nom ... Elle sait dans quel cas il s'agit d'accorder en personne et en nombre (verbes), en genre et en nombre (adjectifs) ...
Dans tous les cas, les données qui s'instancient tout d'abord sont celles qui ont un ancrage lexical : ainsi le nom commun a-t-il de façon univoque, dans le lexique morphologique (§ 4.3.2), un trait de genre et un trait de personne (c'est toujours la troisičme) [5]. Dčs que cet ancrage lexical est trouvé, les buts accord en attente se dégčlent successivement, au fur et ŕ mesure de l'instanciation des traits morphosyntaxiques sur les noeuds terminaux de l'arbre, pour arriver en fin de compte ŕ une instanciation de ces traits sur l'ensemble de l'arbre.
| ---> | Les seuls phénomčnes d'unification relativement complexes qui justifient le modčle des traits d'unification amont et aval en TAG [Vijay-Shanker & Joshi 1988] sont les opérations d'adjonction qui modifient la structure de traits des lemmes situés sous le noeud oů se fait l'adjonction. Ainsi le passé composé est-il modélisé par une adjonction de verbe auxiliaire sur un noeud V. Certains traits de nombre et de personne sont reportés sur le participe passé, qui change en revanche de mode verbal ; l'auxiliaire, lui, reçoit les traits de personne et de nombre du sujet, ainsi que le mode verbal du verbe principal avant l'adjonction. Ce phénomčne, l'accord des participes, n'est actuellement pas correctement modélisé dans PVI. |
|---|
La génération de phrases en français ŕ partir d'une représentation du sens consiste en fin de compte ŕ transformer un graphe en un (ou plusieurs) arbres. Ce processus, qui est donc une hiérarchisation de graphe, est décrit dans les paragraphes qui suivent.
Une premičre passe permet d'engendrer ŕ partir du graphe un premier arbre syntaxique, qui correspond ŕ l'expression simple du premier prédicat et de ses arguments, sans ajout ni modifieur.
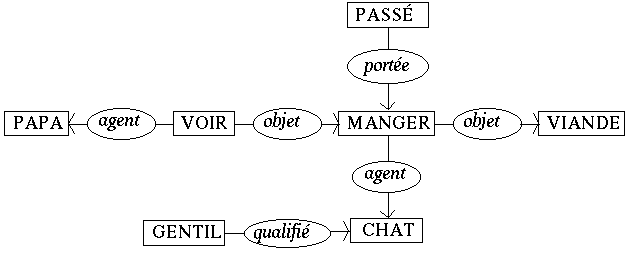
Il faut rappeler que le graphe se présente sous la forme d'une liste de structures prédicat-liste d'arguments ; ainsi un graphe relativement complexe comme celui de la figure 20 (« Papa voit que le gentil chat a mangé la viande ») est-il représenté linéairement par la séquence [VOIR : agent = PAPA, objet = MANGER], [GENTIL : qualifie = CHAT], [MANGER : agent = CHAT, objet = VIANDE], [AVANT : quand = MANGER] :
voir(agent(papa).objet(manger).nil).gentil(qualifie(chat).nil).\
manger(agent(chat).objet(viande).nil).avant(quand(manger).nil).nil
|
La premičre passe de hiérarchisation correspond donc ŕ la recherche d'un arbre de couverture du graphe, dont le noeud tęte, celui par lequel commence le parcours du graphe, est le premier prédicat de la liste (celui qui arrive en tęte dans l'ordre de topicalité). Ainsi, la premičre passe sur le graphe [MANGER : agent = CHAT, objet = VIANDE], [AVANT : quand = MANGER] donne-t-elle l'arbre correspondant ŕ la phrase « le chat mange la viande ». La premičre passe sur le graphe [VOIR : agent = PAPA, objet = MANGER], [GENTIL : qualifie = CHAT], [MANGER : agent = CHAT, objet = VIANDE], [AVANT : quand = MANGER] donne l'arbre correspondant ŕ la phrase « Papa voit que le chat mange la viande ».
Ce parcours se réalise par appel récursif de la rčgle de hiérarchisation lorsqu'elle se porte sur des actants qui sont eux-męme des prédicats (tels MANGER qui, dans l'exemple ci-dessus, est ŕ la fois l'objet de " voir " et la tęte sémantique d'une autre proposition).
En effet, l'opération atomique de conversion de la structure de graphe (§ 3.2) en structure d'arbre syntaxique (§ 4.1) est la sélection, pour un noeud donné du graphe, d'un arbre élémentaire du lexique-grammaire TAG exprimant ce noeud et ses éventuels actants (exemple fig. 21).
![[X] <-(agnt)- [DONNER] ¶ -(objt)-> [Y] ¶ -(rcpt)-> [Z]
donne l'arbre correspondant ŕ *X donne Y ŕ Z*](convdonn.gif)
|
Ŕ chaque étape de la premičre passe de hiérarchisation du réseau, le programme transforme donc un noeud, le noeud « courant », en arbre syntaxique élémentaire, puis appelle récursivement la fonction de hiérarchisation sur les noeuds qui se trouvent eux-męmes au bout des relations casuelles du noeud courant.
Le processus PROLOG essaie ainsi un par un, au noeud n , tous les arbres élémentaires du lexique TAG correspondant ŕ l'entrée n , jusqu'ŕ ce qu'il en trouve un lui permettant d'aboutir avec succčs ŕ un arbre de couverture (partielle) du graphe : ŕ chacune de ces sélections, il essaie d'appliquer récursivement le męme traitement aux noeuds situés directement en aval de n : n 11 , n 21 , ... n m1 . La génération réussie de l'arbre au niveau n dépend alors de la génération réussie des arbres lexicalisant n 11 , n 21 , ... n m1 , puis de leur unification réussie sur les noeuds ŕ substituer dans l'arbre de n . Si cette unification ne peut aboutir pour tous les n i1 , alors on essaye, s'il y en a, un autre arbre élémentaire lexicalisant n - et ainsi de suite jusqu'ŕ épuisement de la liste. Ce processus est illustré sur la figure 22.
![1. X[GN] voit que Y[P]. 2. X <- [GN: Papa]. 3. Y <- [P:
Z mange T]. 6. avoir-V-V* se greffe ŕ *manger*.](generatn.gif)
|
Ainsi lorsqu'il tente de lexicaliser le noeud " voir " (fig. 22, opération 1), le programme tente-t-il tout d'abord le premier arbre élémentaire qui lui est fourni par le lexique TAG ŕ l'entrée " voir " : l'arbre représenté fig. 16.a. C'est lorsqu'il échoue ŕ unifier la partie du graphe représentant l'objet de " voir " (" manger " et ses actants) ŕ un noeud de substitution étiqueté GN, qu'il abandonne finalement cet arbre élémentaire pour essayer - avec plus de succčs - l'arbre de la fig. 16.b.
Certains actants, lorsque leur type de relation casuelle avec le prédicat n'est pas inclus dans l'une des représentations de l'entrée lexicale de celui-ci, sont également traités dans cette phase de premier parcours, mais avec une méthode différente : ils sont intégrés par substitution ŕ un arbre auxiliaire non-terminal, du type de celui qui représente les compléments d'instrument (fig. 19), et l'arbre dérivé est lui-męme adjoint ŕ l'arbre de la phrase en cours au noeud courant (qui représente le prédicat).
Cette premičre passe de hiérarchisation permet ainsi d'aboutir, ŕ partir du premier prédicat du graphe, ŕ une phrase qui est déjŕ au moins un squelette du message final.
Cette premičre passe peut néanmoins laisser des parties de graphe non parcourues. En effet le processus décrit ci-dessus (§ 4.2.1), par nature, ne suit les arcs relationnels que dans le sens des flčches. En d'autres termes, le graphe n'admet pas systématiquement un arbre de couverture connexe.
Dans de tels cas, les différentes parties non connexes du graphe, qui n'ont pas encore été traitées, sont elles-męmes parcourues tour ŕ tour, dans l'ordre correspondant ŕ la topicalité du message (ordre qui a été préservé dans toutes les phases de traitement depuis l'analyse). Le programme essaye dans cette phase d'exprimer ces parties supplémentaires suivant deux stratégies :
Cette stratégie s'applique simplement lorsque l'information ŕ adjoindre est un prédicat qui a déjŕ une lexicalisation possible sous forme d'arbre auxiliaire. C'est le cas par exemple pour un adjectif (fig. 18.b), ou pour un temps verbal, qui se traduit par l'adjonction d'un verbe auxiliaire [6] (fig. 22, opération 6).
Lorsque l'information ŕ rajouter s'exprime sous la forme d'un arbre ŕ tęte P relativement simple, le programme dispose en outre de stratégies lui permettant de transformer celles-ci en arbres auxiliaires GN-GN* correspondant ŕ des propositions subordonnées relatives enchâssées (§ 4.1.3).
Dans la mesure du possible, l'ordre de topicalité du message est conservé lors de la génération. On en voit un exemple lorsque l'on compare les réponses fournies par PVI ŕ la séquence CHAT / MANGER / OISEAU / GENTIL et ŕ la séquence OISEAU / GENTIL / MANGER / CHAT, respectivement :
> test(chat.manger.oiseau.gentil.nil);
Séquence : chat.manger.oiseau.gentil.nil
Graphe :
manger(agent(chat).objet(oiseau).nil).gentil(qualifie(oise\
au).nil).nil
Phrase : Le chat mange le gentil oiseau. (2417 ms)
> test(oiseau.gentil.manger.chat.nil);
Séquence : oiseau.gentil.manger.chat.nil
Graphe :
gentil(qualifie(oiseau).nil).manger(agent(chat).objet(oise\
au).nil).nil
Phrase : L'oiseau que le chat mange est gentil. (2317 ms)
Dans les deux cas, l'analyse aboutit au graphe représenté fig. 23 (car les « contraintes » sémantiques conservées dans le dictionnaire d'icônes interdisent que ce soit l'oiseau qui mange le chat). Mais dans le premier cas, la topicalité du message porte d'abord sur l'action de manger (le prédicat MANGER apparaissait avant le prédicat GENTIL dans la séquence d'entrée), alors que dans le second cas, elle porte d'abord sur l'état de gentil -lesse de l'oiseau.
![[CHAT] <-(agnt)- [MANGER] -(objt)-> [OISEAU] <-(qual)-
[GENTIL]](chmaoige.gif)
|
Ŕ la génération, le premier parcours de hiérarchisation du réseau va donc aboutir, pour le premier cas, ŕ « Le chat mange l'oiseau », et pour le second cas, ŕ « l'oiseau est gentil ». Les prédicats restant sont alors exprimés dans les deux cas par adjonction ŕ la phrase déjŕ formée ; adjonction d'un adjectif épithčte dans le premier cas, adjonction d'une subordonnée relative dans le second cas. Ce qui aboutit finalement aux phrases : « le chat mange le gentil oiseau », et « l'oiseau que le chat mange est gentil ».
Lorsque le programme a déjŕ engendré une phrase correspondant au premier parcours du graphe, il essaye, on l'a vu, d'exprimer l'information restante par des adjonctions dans la męme phrase. Il dispose en outre d'une autre stratégie, qui est de commencer une nouvelle phrase pour le nouveau prédicat ŕ exprimer.
En fait, comme le langage PROLOG est non-déterministe, toutes les solutions possibles sont systématiquement calculées. Ainsi un graphe comme [VOIR : agent = MOI, objet = CHAT], [GENTIL : qualifié = CHAT] peut-il s'exprimer par la phrase « je vois le gentil chat », ou, secondairement, par « je vois le chat ; le chat est gentil » [7]. Bien entendu, l'interface ne peut présenter, elle, qu'une seule sortie ŕ la fois, et c'est donc dans ce cas la premičre phrase qui sera, seule, affichée et transmise ŕ la synthčse vocale.
Dans certains cas, le choix n'existe pas et le systčme doit générer son message en plusieurs phrases. Ainsi lorsqu'il faut exprimer deux propositions de męme niveau, dont aucune n'est subordonnée ŕ l'autre, et qui ont un actant en commun. Dans un tel cas, on ne dispose, d'une part, ni de la possibilité d'exprimer l'une de ces propositions sous la forme d'une subordonnée relative, ni d'autre part de la possibilité de coordonner des groupes verbaux. Ainsi l'analyse de MOI / MANGER / BOIRE aboutit-elle nécessairement ŕ « je mange ; je bois ».
Lorsque le systčme crée un arbre correspondant ŕ une nouvelle phrase, alors qu'il en a déjŕ engendré au moins une pour exprimer le męme graphe, il s'assure également que le groupe nominal sujet de cette nouvelle phrase n'a pas déjŕ été formulé tel quel dans l'une des phrases précédentes. Si c'est le cas, alors dans la nouvelle phrase, ce groupe nominal est transformé en pronom sujet.
La phase la plus triviale de la génération, enfin, est de transformer l'arbre, ou la foręt d'arbres syntaxiques, en une chaîne de caractčres qui puisse ętre affichée ŕ l'écran et envoyée au module de synthčse vocale.
![[P: [GN: [Nom: PAPA]][GV: [Vb: VOIR][PS: [Cnj: QUE][P:
[GN: [Def: LE][Nom: [Adj: GENTIL][Nom: CHAT]]][GV: [Vb: [Vb:
AVOIR][Vb: MANGER]][GN: [Def: LE][Nom: VIANDE]]]]]]]](arbrgenr.gif)
|
Un parcours en profondeur de l'arbre permet de construire la liste des noeuds terminaux. Ceux-ci sont des éléments lexicaux du type <Étiquette de catégorie, <Entrée lexicale, <Identificateur, <Liste de traits morphosyntaxiques> > > >.
Grâce ŕ ces informations, on peut aller récupérer dans le lexique morphologique la forme de surface qui correspond ŕ la déclinaison adéquate de l'entrée lexicale. Voici un exemple de déclinaisons d'un lemme telles qu'elles se présentent dans le lexique des formes morphologiques :
lexical(<Adj,lex_gentil>,"gentil",adj.mas.sing.nil) ->;
lexical(<Adj,lex_gentil>,"gentille",adj.fem.sing.nil) ->;
lexical(<Adj,lex_gentil>,"gentilles",adj.fem.plur.nil) ->;
lexical(<Adj,lex_gentil>,"gentils",adj.mas.plur.nil) ->;
Enfin, de derničres retouches « cosmétiques » sont apportées ŕ la concaténation des formes de surface trouvées dans le lexique morphologique :
Une premičre évaluation du systčme a été menée suivant le principe du banc d'essai, c'est-ŕ-dire « en laboratoire » : un ensemble de 200 séquences d'icônes, correspondant dans leur structure ŕ des expressions produites spontanément en situation réelle [8] a été soumis ŕ PVI pour interprétation et génération. Concrčtement, c'est un fichier contenant la liste des séquences d'identificateurs qui a été fourni en entrée au systčme. Le but de ce banc d'essai était de tester les performances du programme de traduction sur des entrées formatées, indépendamment de l'interface.
Les résultats fournis par le programme ont été classés en quatre catégories :
Les résultats du classement ont été les suivants :
| Catégorie I : | 147 séquences ; | ||
| Catégorie II : | 15 séquences ; | ||
| Catégorie III : | 15 séquences ; | ||
| Catégorie IV : | 18 séquences ; |
Ceci signifie aue l'ensemble des phrases correctement traitées représente 73,5% du total. Ou encore, si l'on décide de compter comme « acceptables » les séquences qui ont été soit correctement interprétées et générées, soit ŕ la rigueur correctement interprétées mais imparfaitement générées (c'est-ŕ-dire en groupant les catégories I et II), que le taux d'acceptabilité de PVI, sur ce banc de tests, est de 80,5%.
Ce score sur banc d'essai n'a toutefois absolument pas la valeur d'un taux d'acceptabilité par l'utilisateur, qu'il revient ŕ ce dernier d'évaluer.
L'évaluation sur site a été conduite par des orthophonistes et des ergothérapeutes au CRRF de Kerpape de décembre 1995 ŕ mai 1996. Un prototype, livré avec une version de test de l'interface, contenant 152 icônes, a été testé par chacun des quatre utilisateurs pendant une période d'un mois. Un retour d'expérience plus qualitatif a pu ŕ cette occasion ętre recueilli, et a enseigné en premier lieu qu'il restait encore beaucoup ŕ faire pour transformer PVI en un produit acceptable.
Il a tout d'abord été souligné qu'un taux d'erreur donné pouvait paraître beaucoup moins acceptable en conditions réelles d'utilisation que sur banc d'essai. Il faut garder ŕ l'esprit qu'une personne souffrant de handicaps moteurs, qui accčde aux icônes par le truchement d'un dispositif de désignation ŕ défilement colonne/ligne, peut passer plusieurs minutes ŕ composer une séquence complčte. Il est compréhensible dans ces conditions que toute réponse insatisfaisante soit ressentie par lui comme extręmement frustrante. Des améliorations ergonomiques ont été suggérées ; nous avons ainsi en fin de compte, dans la derničre version du systčme, remplacé les messages d'erreur initialement programmés par de simples transcriptions linéaires de la séquence d'entrée brute. Ce type de résultat, s'il ramčne finalement ŕ celui que donnerait un simple systčme de désignation sans traitement intelligent, est en tout cas trčs largement mieux toléré par les utilisateurs que le « message incompris » des premičres versions.
Pour ce qui est du module linguistique proprement dit, un certain nombre d'erreurs sont apparues fréquemment, essentiellement dűes au module d'analyse (sur 34 occurrences d'erreurs pendant les évaluations, 3 seulement étaient attribuables au module de génération, et encore ont-elles pu ętre corrigées sans difficulté).
En définitive, il reste en effet dans PVI un problčme central, qui est celui de l'équilibre (fragile) que la conception du lexique doit permettre d'installer entre la précision d'interprétation et le pouvoir expressif. Les contraintes imposées ŕ l'interprétation par les restrictions de sélection (modélisées ici par les trait sémantiques extrinsčques), peuvent se révéler dans certains contextes trop faibles - et conduire ŕ des affectations d'actants inappropriées -, mais dans d'autres contextes trop fortes - et empęcher l'utilisateur de dire quoi que ce soit d'autre que ce qui a été prévu et prescrit dans un schéma actanciel étroit, toute autre interprétation étant rejetée, quelle que soit la maničre dont la séquence est tournée. Toutes les erreurs d'analyse sémantique relevées résultent au fond d'un déséquilibre de ce type.
Ce problčme de maniement délicat des unités primitives lexicales nous conduit ŕ évoquer le problčme plus vaste de la complexité croissante du lexique. Ajouter du vocabulaire ŕ PVI est une tâche plutôt simple tant qu'il s'agit de personnes, d'animaux familiers, de fruits et légumes ... bref de rajouter des membres ŕ des taxčmes déjŕ existants. Mais lorsqu'il s'agit de définir de nouveaux prédicats - disons de nouveaux « verbes » pour simplifier -, cette tâche implique de prévoir et de définir les différentes interactions sémantiques possibles de ces verbes avec les autres icônes déjŕ présentes dans le lexique. Ceci signifie définir des traits de sélection au niveau des verbes que l'on ajoute, mais également retoucher le lexique déjŕ existant en rajoutant des traits intrinsčques pour toutes les icônes susceptibles d'interagir de maničre particuličre avec ces verbes. Or ces nouveaux traits peuvent eux-męmes modifier les interactions de ces icônes avec d'autres verbes déjŕ existant, etc. En somme, chaque ajout d'un nouveau concept au lexique demanderait dans l'idéal un nouveau cycle complet de contrôle de cohérence et un nouveau re-réglage global.
Les principes d'analyse sémantique définis dans le cadre du projet PVI ont fait la preuve de leur intéręt et de leur validité sur un domaine miniature, ce qui est un résultat relativement positif dans le cadre d'un projet de recherche prospective. Les problčmes identifiés pendant le développement et confirmés par l'évaluation, en revanche, rendent inenvisageable le passage immédiat ŕ une phase de développement plus « industriel » et permettent d'identifier les points sur lesquels devraient porter des efforts de robustification.
Retour ŕ Pascal Vaillant PVI : PROTHČSE VOCALE INTELLIGENTE
NOTES
[4] Il y a aussi le substantif "don ", qui permet de regrouper le concept et ses actants sous un syntagme nominal, ŕ condition qu'il n'y ait pas de nuance aspectuelle ou temporelle ŕ exprimer, et que l'on puisse ou veuille éluder l'un des actants agent ou objet.
[5] Le trait nombre est dans cette version de PVI également toujours fixé - la plupart du temps au singulier -, car la marque du pluriel n'est pas traitée en analyse. Il existe donc également des noms fixés au pluriel, qui correspondent ŕ des collectifs (p.ex. "fruits ").
[6] Le passé est dans cette application systématiquement traduit par un passé composé, et le futur par un futur proche avec l'auxiliaire « aller » : les phrases engendrées aspirent ŕ une ressemblance avec du français oral.
[7] Il n'y a pas dans ce systčme de nuance entre la ponctuation « ; » et la ponctuation « . ». Le point-virgule dans cet exemple sépare bel et bien deux phrases différentes ; son choix est en fait imposé par les caractéristiques de certains systčmes de synthčse vocale placés en aval, et qui considčreraient le point comme une marque de fin de séquence ŕ synthétiser, oubliant ainsi la deuxičme phrase.
[8] On s'est inspiré de séquences fournies par les corpus du centre de Kerpape, en adaptant éventuellement le vocabulaire pour se replacer dans l'ensemble couvert par le lexique d'icônes (e.g. Maman acheter moi classeur devient Maman donner moi livre ).
![]()
© Texto! 2001pour l'édition électronique