LA MICROSÉMANTIQUE [*]
François Rastier
C.N.R.S.
SOMMAIRE
1. Lanalyse du
lexique
1. 1. Les approches
disciplinaires
1. 2. Types de
lexique et méthodes de codage
1. 3. Unités et
types de système
2. Définition
3. Les unités
microsémantiques
3. 1. Typologie des
sèmes
3. 2. Représentation
des sémies
3. 3. Les paliers
lexicaux
Excursus n°1
: Les morphèmes ont-ils une signification ?
Excursus n°2
: Les morphèmes ont-ils une référence ?
4. Les classes
lexicales
5. La microsémantique et le contexte
5. 1. Pour une
théorie du contexte
5. 2. La lexie comme
contexte
5. 3. La lexie en
contexte : de la signification au sens
6. Les opérations
interprétatives
6. 1. Les conditions
des opérations interprétatives
6. 2. Les substrats
des opérations interprétatives
6. 3. Les domaines
de modélisation
6. 4. Méthodologie
descriptive
7. Application : un
système dinterprétation en contexte
7. 1. Problématique
7. 2. Objectifs
7. 3. Conditions
danalyse
7. 4. Architecture
et mise en uvre
1. L'analyse du lexique ![]()
Le lexique tient encore aujourdhui un rôle central en linguistique. Depuis une vingtaine dannées, avec laffaiblissement progressif du paradigme formaliste, on a assisté à une réhabilitation du lexique. Alors que naguère les items lexicaux nétaient considérés que comme des variables à instancier au moment propice, depuis quinze ans se multiplient les grammaires lexicales, qui stockent dans le lexique les traits morphologiques, sémantiques et syntaxiques. Cest un indice de lintérêt croissant à légard de la sémantique, et en même temps une limite de fait : on déplace les problèmes de la syntaxe vers le lexique. Cependant, les formalismes syntaxiques ont beaucoup progressé avec les grammaires dunification (cf. Abeillé, 1993), et les liens entre lexique et syntaxe se sont précisés dans ce cadre théorique. Pour aller plus loin, il faut préciser la méthodologie de description du lexique, de manière à « remplir » ces formalismes.
La question théorique du rapport entre le lexique et le texte reste posée. À présent que lon dispose de dictionnaires électroniques importants, lanalyse sémantique des textes sans préanalyse syntaxique va se développer. Doù lintérêt que présente la sémantique lexicale pour la sémantique des textes.
Distinguons tout dabord les différentes approches du lexique, car selon les disciplines la notion de lexique reçoit des définitions diverses.
1.1. Les approches disciplinaires ![]()
Chaque discipline, selon ses objectifs propres, aborde le lexique par des voies différentes. La psychologie cognitive a accumulé une littérature considérable sur le «lexique mental», et tenté de reconstituer lorganisation du lexique en mémoire, notamment par la mesure des temps daccès. LIA a utilisé le formalisme des réseaux sémantiques pour représenter les taxinomies lexicales, dans des domaines limités. La linguistique informatique a construit des dictionnaires électroniques pour les traitements automatiques. On a cependant sous-estimé les différences dapproche entre ces disciplines, car à lépoque du cognitivisme triomphant un même formalisme, celui des réseaux sémantiques, devait rendre compte de ces trois types de lexique. Mais les convergences temporaires que signalait l'usage des réseaux sémantiques n'étaient dues qu'à une communauté de présupposés empruntés à la philosophie du langage du positivisme logique. On peut les résumer ainsi : (i) Le lexique serait un ensemble d'étiquettes (labels) qui représentent des concepts, et par là des choses ; (ii) de même que les concepts sont hiérarchisés par degrés d'abstraction croissante, le lexique s'organiserait en taxinomies arborescentes [1]. Or le lexique d'une langue n'est pas une nomenclature qui quadrillerait uniformément une réalité supposée. En outre, il ne se laisse pas organiser en taxinomies arborescentes (sauf précisément les parties du lexique structurées par des disciplines comme la zoologie). En filant la métaphore de larbre, disons que le lexique dune langue nest pas ramifié à limage dun chêne centenaire, mais ressemblerait tantôt à une garrigue arborée, tantôt à un taillis sous futaie.
Pour poser correctement les problèmes de la description lexicale, il faut dabord récuser les critères ontologiques traditionnels, qui voudraient que les noms représentent des objets (malgré Langacker, 1991 b), les verbes des actions, etc. En effet, toute partie du discours peut indifféremment désigner une catégorie ontologique quelconque : un verbe peut désigner une « substance » (ex. neiger), un nom une « action » (ex. course), un adverbe une « qualité », etc.
Ensuite, il faut admettre que descriptions et représentations puissent différer selon les disciplines : par exemple, le lexique mental selon la psychologie peut différer du lexique selon la linguistique, car l'organisation en mémoire, qui varie sans doute passablement selon les individus, ne prouve rien sur la structure linguistique, même si elle est contrainte par cette structure.
Enfin, il faudra sans doute admettre que les modes de structuration du lexique varient selon les domaines et les champs décrits.
1.2. Types de lexique et méthodes de codage ![]()
Mis à part le codage par le signifiant phonique utilisé par les systèmes de traitement automatique de la parole, il faut distinguer deux sortes de codage du lexique, qui procèdent de méthodologies distinctes voire opposées.
La méthode traditionnelle, dite sémasiologique, est employée par la plupart des dictionnaires. Elle code les unités lexicales par leur signifiant graphique. À chaque signifiant, on associe l'ensemble des signifiés que ce signifiant est susceptible de véhiculer, et l'on cherche ensuite à structurer leur inventaire. À leur origine, chez Quillian (1968), les réseaux sémantiques étaient utilisés pour formaliser la représentation sémasiologique : il mettait par exemple en rapport les diverses significations du mot plant (considéré comme un pur signifiant) : soit 'plante', 'planter', et 'implantation industrielle'.
Cependant, les significations associées à un même signifiant n'ont pas nécessairement d'éléments communs (on parle alors d'homonymie) ; et quand elles en ont (on parle alors de polysémie), elles ne se rencontrent pas dans les mêmes contextes, n'ont pas la même histoire, n'appartiennent généralement pas au même niveau de langue, etc. Les interdéfinir conduit alors à des impasses, comme celle où sengagent Langacker (1987) quand il interdéfinit les diverses significations de ring, qui vont de l'arène à l'anneau nasal, sous le prétexte qu'elles désignent des objets circulaires (à l'exception notoire tout de même du ring de boxe) ; ou Kintsch (1991), quand il interdéfinit bank (rivage) et bank (banque).
Quand elle traite de la polysémie, la méthode sémasiologique conduit souvent, pour pouvoir structurer linventaire des acceptions, à conserver le préjugé métaphysique que chaque mot aurait un sens principal, naturel ou commun, dont dériveraient tous les autres. La notion de sens prototypique est l'aboutissement de cette tradition qui donne le primat à l'ordre référentiel, quand elle suppose un objet prototypique représenté par un concept prototypique [2]. Par ce primat, la méthode sémasiologique définit les mots par les choses, et maintient lillusion archaïque que la langue est une nomenclature.
Lautre méthode, dite onomasiologique, part des classes de signifiés pour les structurer. Les dictionnaires thématiques ou notionnels en adoptent certains principes. Les promoteurs de cette méthode estimaient que ces classes étaient des zones conceptuelles, mais cette hypothèse séduisante n'est pas nécessaire. L'essentiel réside dans le caractère différentiel de la méthode : le sens d'un mot se définit non par rapport à ses autres sens, mais par rapport au sens des mots voisins, aussi bien dans l'ordre paradigmatique que dans l'ordre syntagmatique. Dans le premier ordre, un mot se définit d'abord par rapport à ceux qui lui sont le plus proches, c'est-à-dire ceux qui lui sont opposés. Par exemple,frère se définit par rapport à sur, naître par rapport à mourir, etc. Les expériences d'association lexicale ont confirmé depuis un siècle les corrélats psychologiques de cette organisation : l'association préférentielle se fait entre antonymes.
La signification d'un mot varie donc avec les classes où il se trouve inclus, en langue comme en discours. La théorie des classes lexicales fonde alors l'analyse de la signification lexicale. Cest là une application élémentaire du principe herméneutique que le global détermine le local.
À un niveau de complexité supérieur, l'ordre herméneutique exerce en outre un primat sur la méthode onomasiologique, car les classes lexicales, tant dans l'ordre paradigmatique que dans l'ordre syntagmatique, dépendent des conditions herméneutiques de la production et de l'interprétation, et non pas exclusivement du système de la langue.
La méthode sémasiologique est ordinairement employée par la lexicographie, branche de la linguistique appliquée qui préside à la rédaction des dictionnaires ; la méthode onomasiologique reste en général lapanage de la lexicologie, branche de la linguistique théorique qui décrit le lexique des langues. Du moins, quand la lexicologie recourt à cette méthode, elle fait droit au caractère systématique des langues. Dans la pratique, pour des applications en terminologie par exemple, les deux méthodes peuvent parfaitement être utilisées conjointement. Lessentiel est de rester conscient de leurs présupposés, pour éviter les résultats indésirables.
Remarque La sémantique cognitive aurait pu réaffirmer l'autonomie et la prééminence du niveau conceptuel en adoptant la méthode onomasiologique. Il n'en a rien été. Chaque mot reste pour ainsi dire isolé dans la triade (signe /concept /référent) qui détermine sa signification. On part donc du signifiant à quoi l'on réduit en fait le signe pour viser le concept et, à travers lui, le référent. Cette méthode sémasiologique est généralement employée (cf. Katz et Fodor, 1963, pourbachelor ; Fillmore, 1982, pour write ; Lakoff, 1987, pour over). Elle se heurte bien entendu au fait que les divers signifiés d'un mot n'appartiennent pas aux mêmes classes sémantiques. Le problème embarrassant (car mal posé) de la polysémie se trouve alors traité par la notion de prototype : un « sens » serait le prototype des autres. Il semble exclu de formuler des critères linguistiques pour discerner le prototype, car les différents sens sont censés appartenir à la sphère conceptuelle : « Les structures sémantiques [...] sont caractérisées relativement à des domaines cognitifs, et un domaine peut être n'importe quelle sorte de conceptualisation : une expérience perceptive, un concept, un complexe conceptuel, un système de connaissance élaborée, et ainsi de suite » ["semantic structures [ ] are characterized relative to "cognitive domains", where a domain can be any sort of conceptualization : a perceptual experience, a concept, a conceptual complex, an elaborate knowledge system, and so forth"] (Langacker, 1986, p. 4). Retenons que l'importance considérable donnée au problème de la polysémie est sans doute un artefact de la méthode sémasiologique traditionnelle adoptée par les sémantiques cognitives.
1.3. Unités et types de système ![]()
On peut douter cependant que le lexique relève du système de la langue. L'inventaire des unités lexicales est ouvert, et varie notablement selon les locuteurs, les discours et les genres ; en outre, il évolue rapidement dans certains secteurs. Deux distinctions s'imposent : elles intéressent les paliers de la complexité lexicale et les degrés de systématicité qui les structurent.
1 - Les principaux paliers de la complexité lexicale sont au nombre de deux :
a) Le morphème est le signe linguistique minimal. Par exemple, le mot rétropropulseurs comprend cinq morphèmes : rétro-, pro-, puls-, -eur, -s. Un mot est composé d'un ou plusieurs morphèmes. Ils se divisent en un signifiant (manifeste ou non : ex. en français le signifiant zéro du singulier des « substantifs ») et d'un signifié, le sémème [3].
b) La lexie est le groupe de morphèmes intégré qui
constitue l'unité de signification. C'est une unité fonctionnelle,
vraisemblablement mémorisée en compétence. Une lexie peut n'être composée que
d'un seul morphème (par exemple, la préposition à). Pour les lexies
complexes, composées de plusieurs morphèmes, on peut distinguer des degrés
d'intégration, selon qu'elles s'écrivent en un ou plusieurs mots. Quand elles
s'écrivent en un mot, leur intégration est maximale, car on ne peut y insérer
aucun morphème. Quand elles s'écrivent en plusieurs mots, on peut distinguer
celles qui n'admettent pas l'insertion (ex. à la queue leu leu) et celles qui
l'admettent (dans monter en hâte au créneau, la lexie en hâte est insérée dans la
lexie monter
au créneau). Il reste que la lexie est le syntagme le plus fortement
intégré. Une lexie est composée d'un ou plusieurs morphèmes lexicaux (ou lexèmes :
ex. poireau,
pomme de
terre) ou grammaticaux (grammèmes : ex. car, au fur et à mesure). Le
signifié d'une lexie est une sémie. Il se compose ainsi dun ou
plusieurs sémèmes.
Soit :
|
Signes |
Lexie |
Morphème |
|
Signifiés |
Sémie |
Sémème |
Ces distinctions ne sont pas habituelles, car on considère ordinairement que le mot est lunité linguistique de base, sans doute parce que le mot est la plus petite unité que lon croie susceptible de référence. Ce critère logique a conduit à distinguer entre les mots capables de référer isolément (catégorématiques) et les autres. Hors de ce critère fort discutable, convenons que le mot est une unité graphique, qui dépend des conventions décriture [4]. À ce titre, en tant que chaîne de caractères, le mot a été pris pour unité de base par la quasi-totalité des systèmes de traitement automatique du langage. Si beaucoup se sont étendus ou cherchent à sétendre aux lexies, peu pratiquent systématiquement lanalyse sémantique des morphèmes, sauf pour les grammèmes liés, comme en français ceux du genre et du nombre, qui ne sont alors traités que dans le cadre de lanalyse syntaxique.
2 - Les trois degrés de systématicité (système fonctionnel de la langue, normes sociales, normes idiolectales) ont été définis (cf. lauteur, 1987a, ch. III). Seuls relèvent du système fonctionnel de la langue l'inventaire des morphèmes et les règles de leur combinaison. Les lexies et leur référenciation relèvent d'autres normes sociales, qui peuvent avoir un champ d'application régional, professionnel, voire purement local. Par exemple, le mot trottoir ne signifie pas la même chose pour les services de la voirie et pour ceux de l'équipement, et l'on en devine les conséquences. Il existe aussi des lexiques maison : chez Michelin par exemple, on appelle les transparents des cellos. Enfin, l'usage privé du langage obéit à des normes idiolectales, qui touchent par exemple la signification des noms propres, et telles que Médor désigne rigidement tel affectueux petit chien, ou celle des déterminants, telles que la voiture renvoie sauf mention au véhicule que possède le locuteur.
2. La définition ![]()
1. Le problème de la définition a été obscurci par une longue tradition philosophique qui fait de la définition du mot une identification de la chose qu'il est censé représenter, et dans le meilleur des cas une description des propriétés de cette chose. La plupart des théories des propriétés dont on dispose aujourd'hui témoignent des préoccupations ontologiques de la philosophie du langage. Par exemple, la théorie de Katz et Fodor (1963), puis la théorie des postulats de sens développée par Fodor (1975) à la suite de Carnap lient ces propriétés à des conditions de dénotation nécessaires et suffisantes (désormais : CNS). Leur champ d'application est plus étroit que la théorie de la définition chez Aristote, qui reconnaissait en outre des propriétés non nécessaires (l'accident), ou non suffisantes (le propre). Lindigence du modèle des conditions nécessaires et suffisantes a favorisé par contraste le succès de la théorie de la typicalité développée par Rosch et ses collègues.
Le problème de la définition reste fondamental pour la lexicographie, mais aussi pour la lexicologie. Le concept de définition, fort utilisé, nest pas lui-même clairement défini. Traditionnellement, on en reste au mot, comme Fodor ou Rosch, mais la linguistique doit poser le problème de la définition des signifiés du morphème et de la lexie. Le problème de la définition se pose en effet différemment selon la taille des unités lexicales et les types de systématicité qui les régissent.
Pour la définition du mot, on dispose de divers genres, comme la définition dictionnairique (chevêche : petite chouette), didactique (un rat, c'est comme une souris, sauf que c'est plus gros), cruciverbiste, etc. Entre le défini et le définissant, il n'y a jamais d'identité, mais une équivalence. Tous les genres respectent une règle interprétative fondamentale en loccurrence : les différences entre le défini et le définissant ne sont pas considérées comme pertinentes. Seul le modulo de l'équivalence varie avec les genres de définition.
Pour la lexicologie, la définition est la description des unités sémantiques dont se compose le sens des unités lexicales. Cette description comporte deux aspects corrélatifs : l'identification des traits de sens pertinents, que l'on appelle les sèmes, et l'identification des relations entre ces sèmes, qui permet de décrire le sens comme une structure et non comme un inventaire de traits. Le défini lexicalise de façon synthétique ce que le définissant lexicalise en général de façon analytique : les sèmes du défini sont réitérés dans le définissant. On peut appeler expansivité la propriété universelle des langues qui permet que des unités de sens soient expansées dans des unités de complexité plus grande : le rapport entre un titre et le texte qu'il introduit en illustre un cas limite. La propriété converse est la rétractivité, qui permet les pratiques de résumé. Expansivité et rétractivité sont des propriétés herméneutiques : c'est par convention locale soumise à conditions que l'on admet l'équivalence d'unités, quel que soit leur degré de complexité relatif.
2. On a souvent prétendu que les sèmes sont des unités ultimes, minimales, peu nombreuses. Le nombre des sèmes n'est fini que dans un corpus fermé. Leur caractère ultime ou minimal dépend uniquement des besoins de la description linguistique. Quant aux primitives, leur nombre dépend de la théorie descriptive, dont elles constituent les relations élémentaires ; il serait inutilement présomptueux de les ériger en universaux cognitifs, comme on le fait volontiers aujourd'hui [5].
Les sèmes sont dénommés par des paraphrases de longueur variable (de la lexie au syntagme complexe). Ces paraphrases peuvent être à leur tour expansées. Si l'on adopte une représentation des unités lexicales par des graphes sémantiques, tout nud d'un graphe peut être expansé en un autre graphe.
Les paraphrases qui dénomment les sèmes sont intralinguistiques : ce sont des mots de la même langue que l'unité quelles définissent. Leur catégorie morphologique est indifférente, et lon peut utiliser des verbes, des adjectifs, des prépositions, etc. On peut au besoin employer une autre langue, au risque que ces paraphrases s'allongent. Certains auteurs usent de signes graphiques : par exemple, chez Langacker un trait gras signifie /saillance/, une flèche /mouvement/, etc. Ces notations ne sont pas des formalisations géométriques mais de simples codifications, qui reposent sur des conventions d'écriture, telles que tel signe graphique équivaudra à telle expression linguistique. Les analyses en composants graphiques sont des variantes notationnelles de l'analyse sémique.
L'analyse sémique produit des définitions rationalisées. Elle repose sur le même principe que les définitions ordinaires, mais les unités définissantes sont standardisées, et surtout choisies conformément à des principes de pertinence.
Le caractère circulaire des définitions il est des cercles vertueux reflète le fonctionnement métalinguistique propre aux langues. La possibilité de s'auto-définir est une propriété des langues qui les différencie de tous les autres systèmes de signes. Cette propriété a été obscurcie par la théorie des types de Russell, utilisée pour résoudre des paradoxes logiques, comme celui du barbier du régiment qui doit se raser lui-même, ou celui du catalogue des catalogues qui doit se mentionner lui-même. Si le mot défini et la définition n'ont pas le même statut, cela n'entraîne pas que le premier appartienne au langage et le second à un métalangage. La sémantique de la définition rend inutile la notion de métalangage. Admettons toutefois par compromis que toute langue est aussi son métalangage, ou du moins reste susceptible d'emplois métalinguistiques.
Le caractère circulaire des définitions ne serait regrettable que si l'on voulait constituer la sémantique des langues en une axiomatique qui briserait cette circularité, en négligeant que la relation de définition instaure une équivalence (de modulo conventionnel), mais non une identité.
3. Les débats sur l'analyse sémique ont abordé trois questions : la possibilité même de la définition, la critique des CNS, la critique des inventaires (checklist). Ces débats se sont éteints sans sêtre apaisés, et lon en a gardé limpression fausse que la question était tranchée.
Fodor et ses collaborateurs ont été les champions de la lutte contre les définitions (cf. Fodor et al., 1980). Récanati en a gardé la certitude que certains mots navaient pas de définition ; ils devraient pouvoir nêtre employés nulle part, ou partout, comme des jokers. Hors de cette position extrême, certains auteurs estiment que le sens lexical nest pas analysable, et quil consiste dans la description des objets désignés, les mots qui ne désignent pas dobjet se trouvant alors privés de sens. Ce parti-pris métaphysique ne sappuie pas sur des raisons linguistiques, et interdit toute étude du lexique. Les confusions quil favorise conduisent à des paradoxes : Jackendoff affirme par exemple que les oies et les canards ne diffèrent que par une nuance géométrique, et que lon na pas à distinguer par des critères linguistiques le sens du mot duck du sens du mot goose.
La critique des CNS a été menée aussi par Fodor et ses collègues, qui ont voulu leur substituer des postulats de sens, tels par exemple que si lon est célibataire, on nest pas marié, ou si lon est rouge, on est coloré. En fait, ces postulats ne sont quune variante notationnelle des CNS : ce sont des composants stockés sous la forme de règles dinférence.
Enfin, par la critique des checklist theories of meaning, Fillmore visait pour lessentiel la théorie de Katz et Fodor (1963) : il a souligné à bon droit, après Weinreich, que lénumération de sèmes ne permettait pas de représenter la structure des significations lexicales. Aussi proposons-nous une représentation structurée des sémies (cf. infra, § 3. 2).
4. Les débats sur la définition opposent en fait deux conceptions :
a) La conception essentialiste estime que la signification nest pas analysable parce que les objets mondains ou mentaux quelle représente ne consistent pas en qualités. Elle appuie les diverses théories des stéréotypes, prototypes et archétypes lexicaux qui toutes réifient un noyau de sens infrangible et en fin de compte indépendant de la langue.
b) La conception nominaliste ou plus précisément non-réaliste développée par la sémantique interprétative, et compatible avec certaines formes dherméneutique, estime que le sens lexical est analysable, parce quil nest pas gagé sur des objets extralinguistiques. En outre, à la différence des objets, il nest pas doté dune identité à soi qui définirait un noyau de sens invariant et primordial. Sa définition dépend de conditions objectives telles que le contexte (local puis global) et la situation, mais encore de conditions subjectives qui sont celles de linterprétation : une définition ne décrit pas un être, mais les traits du sens lexical pertinents pour les objectifs de la pratique en cours.
Remarque On oppose souvent de nos jours, pour
discuter de la représentation du lexique, le dictionnaire et lencyclopédie. Ce
problème nous a été légué par Leibniz, qui distinguait la caractéristique
(comme description calculatoire des essences, et auxiliaire de la logique) de
lencyclopédie, auxiliaire de lhistoire. Cela correspond à deux conceptions du
lexique : comme reflet de vérités métaphysiques, ou comme reflet
dopinions sociales.
Partisan comme avant lui Carnap des conditions nécessaires et suffisantes,
Katz a opposé le dictionnaire à lencyclopédie pour préférer le premier. Eco à
linverse à préféré la seconde, en lui donnant une grande publicité. Depuis,
toute théorie du lexique se voit un jour affrontée à un faux dilemme, et sommée
de choisir entre ces deux « formats ». On en a même fait un critère
discriminant entre la sémantique vériconditionnelle et la sémantique cognitive
(cf. Geeraerts, 1993).
Nous refusons ce dilemme, car dune part il ne rompt pas avec la conception lexicographique du lexique, qui en fait une nomenclature plus ou moins étendue, sans récuser explicitement les conceptions adamiques du langage comme inventaire de noms. Mais surtout, il maintient la perspective référentielle. Le dictionnaire (à la Katz) comme lencyclopédie, telle quelle est présentée aussi bien par Putnam, Petöfi [6] ou Eco, substituent la description des choses à la description des mots, et saccordent également avec le réalisme qui a toujours caractérisé le courant dominant de la philosophie du langage occidentale.
Dans le même temps, la notion de connaissance reste le principe organisateur du lexique, comme sil se bornait à refléter un savoir partagé sur le monde. Mais elle ne rend pas compte des processus sémantiques qui permettent la création de nouvelles acceptions et de nouveaux emplois, parfois demeurés isolés, et, dans leur contingence, non-dérivables de connaissances même encyclopédiques.
La conception encyclopédique ne résout pas mieux le problème de la pertinence que la conception dictionnairique ; au contraire, elle la pose avec plus dacuité, car elle multiplie à linfini les informations sans permettre déliminer celles qui sont non-pertinentes. Seule une stratégie interprétative appuyée sur une herméneutique philologique permet de requérir les connaissances utiles à la lecture, comme déliminer celles qui sont oiseuses.
Si, comme nous lavons souligné, linterprétation dun texte, et en particulier lassignation de sens à ses unités lexicales requiert des connaissances encyclopédiques, nécessaires sans dailleurs être suffisantes, cela nentraîne aucunement que son lexique doive être structuré comme une encyclopédie. Les connaissances encyclopédiques nécessaires ne relèvent dailleurs généralement pas de la linguistique, mais dautres sciences. Elles nont pas à être représentées dans le lexique, et ny sont dailleurs pas représentables, eût-il un format encyclopédique. En somme, sauf pour les applications qui lexigent, le lexique ne doit être structuré ni comme un dictionnaire, ni comme une encyclopédie : il échappe aux contraintes de ces genres lexicographiques qui relèvent de la linguistique appliquée, non de la linguistique théorique.
5. Les problèmes de la polysémie et de lambiguïté qui préoccupent la sémantique tributaire de la philosophie du langage sont pour lessentiel des artefacts de la conception essentialiste de la signification. Il est bien rare que dans une pratique déterminée on ait à distinguer, parmi les acceptions de plateau, un plateau géographique dun plateau de service, de spectacle, de tourne-disque ou de machine-outil. Peu importe dès lors que ces acceptions aient en commun le sème /horizontalité/, lequel dailleurs nest pas actualisé en toute occurrence. Pire, les traits communs à une classe dacceptions sont eux-mêmes des artefacts dune perspective sémasiologique : si lon compare lassiette du cavalier et lassiette de service, on sera tenté dinclure dans leur définition un sème /stabilité/, ce qui serait en règle générale erroné pour la seconde acception, pour laquelle ce sème nest pas définitoire, relativement à plat et à couvert, par exemple.
Lambiguïté, conçue comme indétermination référentielle (et non comme équivocité) relève également dune conception substantialiste. Une phrase comme Jai raté mon bus, mais je vais lattraper dans cinq minutes est ambiguë pour une sémantique référentielle, car le bus que jai raté nest pas le même véhicule que celui que jespère prendre ; en revanche pour une conception interprétative, les traits pertinents sont les sèmes /transport en commun/, /urbain/, /routier/, communs aux deux sémies (bus et le pronom l), et qui ne permettent pas de les différencier.
Le problème de la définition concerne le palier du mot, mais certaines des précisions que nous venons de donner intéressent également les paliers supérieurs. Dune part, on la vu, en raison de lexpansivité et de la rétractivité. Dautre part, la description sémantique dune phrase ou dun texte obéit aux mêmes principes fondamentaux que celle dun mot, et une paraphrase réglée peut être appelée lecture descriptive.
3. Les unités microsémantiques ![]()
La microsémantique est la sémantique du palier inférieur du texte. Elle prend pour limite supérieure la sémie [7]. Les signifiés des morphèmes ont été peu étudiés, sans doute parce que les morphèmes nont pas de référence, et que traditionnellement on identifie les significations aux référents. Len-deçà du mot a été négligé comme lau-delà de la phrase en raison de critères logiques complémentaires : la référence, propriété du mot, trace la limite inférieure ; la vérité dont est susceptible la phrase, la limite supérieure.
La microsémantique se divise en trois sections : la théorie des sèmes, la théorie des unités lexicalisées, et la théorie des relations contextuelles. Nous allons les aborder successivement.
3.1. Typologie des sèmes ![]()
Un sémème est un ensemble structuré de traits pertinents, les sèmes. Ils sont définis comme des relations dopposition ou déquivalence au sein de classes de sémèmes : par exemple, bistouri soppose à scalpel par le sème /pour les vivants/. L'opposition sémique /animal/ ou /végétal/ différencie venimeux de vénéneux. Mausolée soppose à mémorial par le sème /présence du corps/ [8], mais lui est équivalent par le sème /monument funéraire/. Comme les sèmes sont des unités propres à une langue, nous ne formulons pas dhypothèse universaliste à leur égard. Leur pertinence est rappelons-le soumise aux conditions herméneutiques générales précisées naguère (lauteur, 1987a).
1 - On distingue deux sortes de sèmes :
a) Les sèmes génériques sont hérités des classes hiérarchiquement supérieures, et indexent le sémème dans ces classes. Ils notent des relations déquivalence entre sémèmes.
La distinction entre sèmes génériques et spécifiques est doublement relative : dune part, un sème qui a le statut de trait générique dans un sémème peut revêtir celui de spécifique dans un autre ; dautre part, cette distinction dépend évidemment de la définition des classes, qui peut varier avec le corpus, comme avec les objectifs de la description.
2 - Quils soient génériques ou spécifiques, les sèmes peuvent revêtir deux statuts différents, qui caractérisent leur mode dactualisation, entendue comme instanciation du type par loccurrence.
a) Les sèmes inhérents sont définitoires du type. Ils sont hérités par défaut du type dans loccurrence, si le contexte ny contredit pas.
Chacun des sèmes du type est un attribut à valeur typique. Par exemple, dans corbeau l'attribut (ou axe sémantique) <couleur a pour valeur typique /noir/. On dira alors que /noir/ est un sème inhérent à corbeau. Pour ce qui concerne les sèmes inhérents, la valeur typique est héritée par défaut dans l'occurrence. Mais une détermination contextuelle peut fort bien empêcher cet héritage et imposer à l'attribut <couleur une valeur atypique (ex. « le corbeau orange descendant sur moi » (Jean Giraudoux, Suzanne et le Pacifique, 1921, p. 143). Aucun sème inhérent n'est donc manifesté en tout contexte.
b) Les sèmes afférents se divisent en deux sortes.
Les premiers notent des relations applicatives d'une classe minimale de sémèmes (taxème) ou de sémies (taxémie) dans une autre. Par exemple les membres du taxème //homme, femme// sont en français le but d'une relation d'application qui a pour source les membres du taxème //force, faiblesse//. Cette sorte d'application rend compte des phénomènes dits de connotation, ainsi que de phénomènes de prototypicalité [9]. Ces relations applicatives dépendent de normes sociales différentes du système de la langue (mais cependant à luvre dans tout texte). D'où sans doute le caractère « périphérique » souvent attribué aux sèmes afférents. On peut dire que ces sèmes afférents, socialement normés, sont associés au type sans avoir de caractère définitoire au même titre que les sèmes inhérents. À ce titre, ils ne sont actualisés dans loccurrence quen raison de prescriptions issues de son contexte. Ces sèmes sont des valeurs prises dans l'occurrence par des attributs facultatifs du type [10]. Ils ne sont pas hérités par défaut, mais doivent être actualisés par une instruction contextuelle. Par exemple, le sème /péjoratif/ afférent à corbeau [11] sera actualisé dans « un corbeau des sombres rancunes » (Louis-Ferdinand Céline, Mort à crédit, 1936, p. 781).
Une seconde sorte de sèmes afférents ne dépend pas de relations paradigmatiques entre classes, mais résulte uniquement de propagations de sèmes en contexte. On peut les appeler sèmes afférents contextuels. Leur mode dactualisation les distingue radicalement des précédentes sortes de sèmes, car il ne met pas en jeu le rapport entre types et occurrences, mais uniquement les rapports entre occurrences. Traditionnellement, les sèmes afférents contextuels ne sont pas représentés dans le type lexical. Ils sont propagés dans loccurrence par le contexte, notamment au moyen de déterminations ou de prédications. Par exemple, dans le corbeau apprivoisé le sème /apprivoisé/ doit être représenté dans l'occurrence de corbeau. Ce sème, certes local, doit y être stocké pour permettre ultérieurement la construction de l'acteur Corbeau lors de l'analyse du texte.
Remarque On peut voir là un artifice de présentation. Mais on peut admettre à l'inverse que le contexte « déforme » les occurrences par rapport au type. Et, mieux encore, comme le type n'est qu'une reconstruction conventionnelle à partir des occurrences, que les occurrences modifient le type par la création et /ou la délétion de traits. Cela concorde avec ce que l'on sait du fonctionnement dit métalinguistique des langues, comme avec les analyses de la sémantique lexicale diachronique.Philosophiquement parlant, la position non-réaliste que nous adoptons ici va à l'encontre de la tradition aristotélicienne courante en philosophie du langage : le type ne représente pas une substance dont les occurrences marqueraient les accidents ; il n'est lui-même qu'une collection structurée d'accidents, momentanément considérés comme invariants. Dès lors que lon renonce à lontologie des substances, cette modification de la notion de type simpose.
3 - Cette typologie appelle quelques précisions.
a) Rappelons que types et occurrences nont pas le même statut. Le sémème-type et la sémie-type relèvent comme tels de la compétence linguistique telle que lon peut la reconstituer. Ils sont donc des artefacts du linguiste. En revanche les occurrences sont des objets du linguiste, et relèvent de la « performance » des énonciateurs. Aussi les sémèmes et les sémies occurrences que l'on rencontre dans les textes peuvent différer des types [12], comme on la vu pour corbeau.
b) Lactualisation de tous les sèmes, inhérents ou afférents, dépend dans tous les cas du contexte, car même les sèmes inhérents peuvent être virtualisés par le contexte. Laction du contexte, à ce palier danalyse, engage en bref trois types de normativité : (i) permettre ou interdire lactualisation de sèmes inhérents ; (ii) prescrire lactualisation de sèmes afférents socialement normés ; (iii) propager doccurrence en occurrence des sèmes afférents contextuels. Lactualisation des uns comme des autres dépend ainsi du contexte, soit quil la prescrive, soit quil ne linterdise pas.
c) La distinction entre sèmes afférents et inhérents reste relative : elle marque une différence de degré plutôt que de nature, si lon considère la longueur et la complexité des parcours interprétatifs qui permettent de les actualiser.
d) Le concept dattribut (dans la terminologie de lIA) ou daxe sémantique (dans la terminologie structuraliste) a une importance cruciale si lon traite des rapports entre type et occurrence. Un attribut définit en effet une zone de pertinence. La description choisit les attributs en fonction du domaine de lapplication : par exemple, Airbus na pas les mêmes attributs dans un manuel dentretien et dans une publicité de compagnie aérienne.
Du fait que certains attributs prennent indifféremment une valeur ou une autre, on a conclu à linefficacité de lanalyse sémique, en arguant dacceptions contradictoires. Par exemple, Piotrowski (1993, p. 72) relève que lueur désigne une lumière tantôt vive et tantôt faible, tantôt brève et tantôt durable. Une analyse statique de la signification ne peut rendre compte de ce genre de phénomène ; en revanche, une étude dynamique du sens lexical permet de décrire comment le contexte sélectionne des acceptions, et quelles soient contradictoires entre elles ne suscite de difficultés que pour une étude sémasiologique [13].
Les attributs appartiennent à la signification en langue, leurs valeurs au sens en contexte. Les normes intermédiaires responsables des afférences socialement normées définissent des valeurs préférentielles.
e) La distinction entre actualisation et virtualisation doit être spécifiée en degrés de pertinence. On peut en distinguer quatre, selon que le sème est neutralisé (exclu) ou virtualisé (mais réactualisable), actualisé, ou saillant. Par exemple, dans Guillaume était la femme dans le ménage [14], le sème /sexe féminin/ est neutralisé dans femme si lon se reporte au texte. Par ailleurs, le sème /humain/ est actualisé, mais non mis en saillance ; en revanche, /faiblesse/ est saillant, bien quafférent (pour une analyse, cf. 1987 a, ch. III).
Ces quatre degrés de pertinence sont autant de cas limite, et lon pourrait sans doute définir des degrés de saillance et de virtualisation ; il faudrait pour cela décrire lunivers sémantique comme un continuum à seuils, ce qui pose le problème de sa modélisation topologique.
3.2. Représentation des sémies ![]()
Un formalisme simple pour représenter les sémies-types paraît être celui des graphes conceptuels ; en l'occurrence nous les dironssémantiques, car nous ne formulons pas dhypothèse réaliste sur leur statut mental.
L'usage des graphes conceptuels (cf. Sowa, 1984) pour la représentation sémantique peut favoriser l'implantation informatique, et évite les écueils propres aux théories qui admettent des inventaires non structurés de sèmes. Toutefois des remaniements paraissent nécessaires pour mieux exploiter les possibilités de ces graphes. En premier lieu, une redéfinition systématique des primitives utilisées par Sowa, notamment des cas. Ensuite, il faut utiliser la possibilité d'établir des liens, polyadiques (et non seulement binaires) ; corrélativement, admettre des liens alternatifs, pour les relations attributives en particulier, afin d'admettre des occurrences peu typiques. Malgré tout, les graphes conceptuels restent peu aptes à représenter les dynamiques contextuelles et conviennent surtout à des représentations lexicales simples, qui présentent les significations-types de façon statique.
Les nuds des graphes sont étiquetés par les sèmes. Les liens des graphes sémantiques sont étiquetés par des primitives (notamment les relations casuelles). Ces primitives sont des catégories descriptives, non des unités de la langue décrites. On peut les considérer comme des universaux de méthode, cest-à-dire des principes de représentation. Les hypothèses cognitives formulées à leur égard ne nous retiendront pas ici. Par souci d'efficacité descriptive, on peut considérer que les primitives sont diversement spécifiées selon les domaines d'application, c'est-à-dire, linguistiquement parlant, les discours voire les genres. Ainsi la primitive casuelle LOC (locatif) peut être spécifiée en toutes sortes de valeurs décrivant des positions dans l'espace ou le temps représentés.
À ces conditions, une sémie type peut être représentée par un graphe ; ainsi pour agriculteur, en suivant les conventions graphiques de Sowa, mais en modifiant linventaire de ses cas (ici, ERG abrège ergatif, et ACC, accusatif ) :
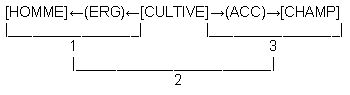
Cependant, les modes de représentation doivent sadapter au type de processus sémantique que lon veut modéliser. Or, la représentation des sémies-occurrences ne peut conserver le même format car elle doit en outre figurer les relations entre sémies, par des liens dinhibition et dactivation, tels quils sont utilisés par exemple dans les réseaux connexionnistes. Les liens dinhibition relient les sèmes contraires ou contradictoires, les liens dactivation les sèmes identiques [15].
La distinction entre liens et nuds, qui correspond en logique à celle qui sépare les prédicats des arguments, devient alors inutile. Dans la suite, nous ne reprendrons pas toujours la distinction homologue entre sèmes et primitives, considérant simplement les sèmes comme les primitives du domaine ou du champ sémantique à décrire. Par exemple, nous traiterons les primitives casuelles comme des sèmes afférents contextuels [16].
3.3. Les paliers lexicaux ![]()
Nous pouvons à présent caractériser brièvement les types dunité et les principes de leur combinaison. À chaque type dunité correspond un type de lexique.
a) Sans doute en raison des privilèges philosophiques dont jouit le mot, le lexique des morphèmes nest guère étudié ni utilisé en tant que tel. On peut distinguer en français quatre sortes de morphèmes : les lexèmes libres (comme les noms propres), les lexèmes liés (qui figurent dans des lexies complexes, comme puls- dans pulsion) ; les grammèmes libres (comme les prépositions) ou liés (comme les flexions).
Hors du contexte de la sémie, les sémèmes gardent une signification. Par exemple, le préfixe re- comporte le sème /itératif/, le suffixe -ette /diminutif/. Cette signification est constituée de sèmes spécifiques inhérents. En dautres termes, ces sémèmes ont des éléments de sémantème, mais pas de classème, car ils ne comportent pas de traits génériques. Par exemple le sémème damas- comporte le sème spécifique /moyen-oriental/, mais les sèmes génériques /armes/ et /tissus/ ne sont réalisés que dans les sémies damasquiné et damassé, respectivement.
b) Le lexique des lexies est beaucoup mieux décrit. Cependant lon a accordé un privilège exorbitant aux lexies qui correspondent à des mots simples, alors que les lexies complexes («mots composés» et «expressions»), sont moins bien décrites. En outre, parmi les lexies simples, on a accordé la préférence aux « mots pleins » ou lexies comprenant un lexème, en particulier les noms puis les verbes. Les « mots vides » ou lexies comprenant au moins un grammème, mais pas de lexème, ont été étudiés plutôt par la morphosyntaxe que par la lexicologie. Si bien quon ne dispose pas de sémantique unifiée des lexies.
c) Le lexique des phraséologies a été insuffisamment étudié. Ces syntagmes ou suites de syntagmes fortement intégrés, comme prendre ses désirs pour des réalités ou dans une situation où les difficultés essentielles qui se trouvaient devant nous sur la voie de la construction socialiste sont déjà surmontées (Jdanov) sont fort nombreux, et leur étude ne relève pas seulement de celle des dictons. Ce sont de véritables unités de communication, et elles devraient être traitées de la même manière que les lexies.
Rappelons enfin que les unités lexicales ne peuvent être isolées que pour des raisons de méthode. Elles ont une définition relationnelle dune part dans lordre paradigmatique (cf. infra sur les classes sémantiques) et dautre part dans lordre syntagmatique, notamment pour ce qui concerne la syntaxe. Lopposition entre syntaxe et lexique nest donc que relative [17], car à chaque sème défini dans lordre paradigmatique correspondent des valences syntagmatiques. Enfin, il y a une syntaxe interne aux lexies, et une sémantique propre à la combinaison des morphèmes dans la lexie.
Bien qu'élaborées pour décrire le palier textuel, les quatre composantes sémantiques (tactique, thématique, dialectique, dialogique ; voir lauteur 1989b) articulent aussi les niveaux inférieurs. Par exemple, dès le niveau de la lexie, on relève des phénomènes thématiques d'isotopie (ex. esp. chiq-it-it-o, dont les trois premiers sémèmes répètent le sème /infératif/ ; des intervalles dialectiques temporels (ex. un ex-mari) ou aspectuels (cf. informe vs difforme). La codification des genres peut même opérer en deçà du morphème, comme le montre cet extrait de Ligne A, le guide malin qui définit succinctement le genre nom de rame de RER : « Signification du nom des trains : la première lettre indique la gare terminus, la seconde indique la mission du train, et les deux dernières forment un nom mémorisable ». On trouvera aisément d'autres exemples au palier de l'énoncé, et cela aussi confirme l'unité des trois paliers de la sémantique, du mot au texte.
Cette question reste nécessaire, car la tradition en philosophie du langage a toujours pris pour base le mot, et la décomposition du mot en morphèmes conduit à un changement plus radical qu'il ne paraît. Pour peu que l'on admette que tous les morphèmes sont d'emblée égaux en droit devant la description linguistique, sans reformuler à leur propos la distinction métaphysique entre mots vides et mots pleins [18]. D'habitude, pour qu'on accorde une signification à un morphème, il faut qu'il soit libre, c'est-à-dire qu'il constitue un mot. Ainsi des grammèmes libres (ex. les prépositions) et des lexèmes libres (ex. les noms propres, généralement dépourvus d'affixes, et invariables). Il faut aussi, pour que la signification soit clairement identifiable, que le morphème libre n'appartienne qu'à un seul paradigme sémantique.
En revanche, on répugne à accorder une signification « pleine et entière » aux morphèmes liés : on préfère traditionnellement dire qu'ils concourent à la signification du mot dont ils sont les composants, en introduisant en outre une hiérarchie injustifiée entre les lexèmes liés (considérés comme fondamentaux, cf. les noms de racine, radical) et les grammèmes liés (jugés annexes, cf. le nom d'affixes). Cette répugnance a ses prétextes. D'une part la signification des morphèmes liés est toujours influencée par celle des autres morphèmes qui constituent le mot (nous illustrerons plus loin comment). En effet, quand le mot est un syntagme et se compose de plusieurs morphèmes, il existe naturellement une syntaxe, et aussi des relations sémantiques contextuelles internes au mot.
En outre, les morphèmes liés, particulièrement les lexèmes, entrent avec les mots qui les incluent dans divers paradigmes. Leur polysémie [19] engage alors à conclure que leur signification est instable si l'on considère ses variations ou ténue, si l'on ne retient que ses traits invariants (constituant le noyau sémique). Par exemple, dans le paradigme courir, sauter, marcher, 'saut-' est défini par le sème générique /déplacement/ et par les sèmes spécifiques /verticalité/ et /itérativité/ (afférent). Mais qu'en est-il dans d'autres paradigmes comme dans sauteuse (vs poêle, faitout, marmite) ou sauterie (vs raout, réception, soirée, partie) ? Quand ces traits peuvent être « conservés », ils changent de statut : ils ne sont plus des sèmes inhérents) mais des sèmes afférents dont l'interprétant est précisément l'analogie des signifiants.
Cela a une conséquence sur les fondements méthodologiques de l'analyse sémique : les sémèmes des morphèmes liés ne peuvent être interdéfinis contrastivement qu'au sein de paradigmes groupant des unités de rang supérieur, les lexies. En outre ces unités doivent relever d'une classe morphologique identique ou équivalente. Le mot (ou lexie simple) est donc le contexte minimal de l'analyse sémique.
Si l'on applique fermement le principe qu'un morphème ne peut être défini qu'au sein d'un paradigme qui détermine sa signification (notamment le partage entre ses sèmes spécifiques et génériques), alors les morphèmes libres doivent être interdéfinis dans le cadre de syntagmes. On pourra opposerà et de dans à Paris et de Paris (cf. il vient à Paris, il vient de Paris) mais aussi à, par et sur dans le paradigme à terre, par terre, sur terre.
Les significations ainsi définies ne sont pas indépendantes du contexte, puisqu'elles sont d'emblée déterminées par la signification des morphèmes voisins, dans le contexte interne de la lexie ou du syntagme. Alors se dissipe le mythe d'une signification pure, attachée à un seul signe, et dénuée de tout effet de sens contextuel, telle que la philosophie du langage avait accoutumé de la concevoir.
On en vient à conclure, non sans paradoxe, que le morphème est la seule unité pourvue de signification, mais elle reste vague et impossible à préciser hors contexte. Cependant que les mots (ou plus exactement les lexies) auraient des sens, mais point de signification. En somme, la signification serait alors une propriété des morphèmes, et le sens une propriété de leurs combinaisons.
Le problème de la désignation ne se pose traditionnellement qu'au niveau du mot. La tradition veut donc que les morphèmes liés n'aient pas de référence. Quant aux morphèmes libres (qui « coïncident » avec des mots) seuls ceux qui sont quantifiables réfèrent, si l'on en croit par exemple Brekle : « Le problème de la désignation ne se pose pas dans le cas des mots non quantifiables » (1974, p. 24). Faute d'être quantifiables, les grammèmes libres ne référeraient donc pas [20]. Restent alors les lexèmes libres que sont les noms propres. Leur caractère quantifiable, bien que fort discutable, en ferait les seuls morphèmes pourvus d'une référence. Bref, la philosophie du langage, en sattachant au mot et en nattribuant pas de référence au morphème, sinterdit de constituer une sémantique fondamentale, puisqu'en linguistique on reconnaît pour signe élémentaire le morphème.
Il faut tenir compte ici des trois degrés de systématicité que nous évoquions, et qui jouent aussi au palier microsémantique un rôle régulateur.
a) Le premier procède du système fonctionnel de la langue définie comme système de signes (ici, de morphèmes). Ces prescriptions sont tout à la fois : (i) impératives (c'est pourquoi nous avons défini des sèmes inhérents) [21] ; (ii) imprécises (couvr- signifie par exemple 'superposition d'une protection [quelle qu'elle soit] à un objet [quel qu'il soit]') et ce vague est nécessaire pour pouvoir interpréter les nouveaux emplois et les néologismes ; (iii) soumises à des conditions multiples, puisque tout sème inhérent peut se trouver virtualisé par le contexte.
Si l'on convient de cela, les mots n'appartiennent pas à la langue fonctionnelle mais à la phraséologie. Ils sont déjà des syntagmes fort contraints certes dans leur syntaxe interne et comme tels dépendent déjà de la parole (au sens saussurien, ou de la compétence, au sens chomskyen). S'il n'a pas ordinairement la compétence de créer des morphèmes, tout locuteur a celle de créer des mots.
b) Le second type de systématicité est celui des normes sociales, telles qu'elles paraissent par exemple dans la phraséologie. Dans un état de langue donné, elles règlent nécessairement toute production linguistique. Elles rendent compte de la stabilisation du lexique à certaines combinaisons de morphèmes, alors que bien d'autres seraient parfaitement licites mais restent inusitées voire non attestées (cf. e.g.désherber, herbage vs *herber ; hauteur vs * basseur).
En outre, elles rendent compte de l'indexation des acceptions dans des domaines sémantiques déterminés (par exemple blanquette signifie /blancheur/ et /diminutif/ et pourrait convenir sans contredire aux prescriptions de la langue à toutes sortes de choses blanches, et non seulement à certain vin blanc et certain ragoût en sauce blanche qui tous deux relèvent du domaine //alimentation//). Ces domaines sont évidemment liés à des conventions sociales, non à la structure fonctionnelle de la langue. Même dans un domaine bien défini, les normes qui fixent la signification du mot, et par suite sa référence, n'ont pas de régularité prévisible. Prenons un exemple dans le domaine de la zoologie, bien structuré par ses traditions académiques et scientifiques. Dans buse variable, variable signifie 'dont la couleur varie selon les individus', alors que dans lièvre variable, variable signifie 'qui change de couleur selon les saisons'.
Lindexation des sémies dans des dimensions évaluatives reste également imprévisible. Par exemple, innommable comprend le sème /péjoratif/, ineffable le sème /mélioratif/ (alors que son radical vient simplement du latin fari, parler). En somme, par leur composition, ces deux mots seraient parasynonymes, si les sémèmes qui constituent leurs sémies se composaient « régulièrement » ; et pourtant ils sont antonymes.
On objectera peut être que les normes qui déterminent les acceptions selon les contextes internes ou externes du mot ne relèvent pas de la linguistique restreinte, car elles règlent des usages linguistiques, mais non le système tel quon lidéalise. Et pourtant elles constituent vraisemblablement un puissant facteur d'évolution linguistique. En variant, elles modifient la signification et la référence des mots, et modifient par là leurs paradigmes de définition. Les évolutions diachroniques en dépendent pour une grande part (cf. Rastier, à paraître, a).
Pour conclure à présent du sens à la référence qu'il détermine, ces trois types de systématicité correspondent à trois stades de fixation de la référence ou, en d'autres termes, de construction de l'impression référentielle [22].
(ii) Les mots isolés tels qu'ils sont composés par les normes sociolectales peuvent être pourvus d'une ou plusieurs références. Mais alors ils ne réfèrent au mieux qu'à une ou plusieursclasses d'individus. En quoi ils sont nécessairement équivoques, puisque coupés de leur contexte.
(iii) En revanche, un mot en contexte peut référer à un individu, dans une situation déterminée. Et cela, même s'il est réputé posséder une signification générique. Dans une famille qui en possède un,le chat renvoie généralement à un et un seul félin domestique.
En notant cela, nous ne nous rallions pas à une sémantique de la référence même dépendante de conditions herméneutiques : nous signalons simplement les corrélats référentiels de propriétés définies par une sémantique différentielle. Ressaisissons en bref ce qui précède :
|
signes |
traits |
unités sémantiques |
systématicité |
référence |
|
morphème |
sèmes |
sémème |
système fonctionnel |
néant |
|
mot |
sèmes afférents |
acception |
normes |
référence |
|
mot |
sèmes afférents |
emploi |
normes |
référence |
4. Les classes lexicales ![]()
Comme pour la sémantique différentielle la définition des sèmes dépend des classes sémantiques constituées en langue comme en contexte, il nous faut caractériser ces classes. Cest dautant plus nécessaire quune grande confusion règne en sémantique cognitive, où les significations sont rapportées à des « domaines cognitifs » sans principe de définition linguistique (cf. e.g. Langacker, 1991 b, pp. 106-107) [23].
1 - La classe minimale est le taxème. En son sein sont définis les sèmes spécifiques du sémème, ainsi que son sème le moins générique (taxémique) : ex. /monument funéraire/ pour mausolée et mémorial. Les taxèmes reflètent des situations de choix ; par exemple autobus appartient au même taxème que métro, à la différence de autocar (qui appartient pour sa part à la même classe que train) [24].
Le taxème est la seule classe nécessaire : tout sémème comprend au moins un sème générique qui lindexe dans son taxème de définition. Au sein dun taxème, on relève divers types de relations : oppositions entre contraires (mâle, femelle), entre contradictoires (possible, impossible), oppositions graduelles (brûlant, chaud, tiède, froid, glacial), implications (démobilisé, mobilisé), complémentarité (mari, femme ; théorie, pratique ; faim, soif ; vendre, acheter). On ne peut ériger lantonymie en règle universelle, comme le montre cette immortelle réplique dans Ionesco : « Vous éternuez ? Non, au contraire ! ».
Les énumérations linéarisent souvent des taxèmes ; soit par exemple ce taxème de la crise économique : //récession, dépression, déflation, stagnation, stagflation// (Le Monde, 09. 06. 93).
Par leur structure différentielle, les taxèmes reflètent les conditions perceptives générales qui font de lactivité linguistique un processus de discrétisation et de catégorisation. Les expériences des associationnistes et les travaux sur lamorçage sémantique ont montré les corrélats psychophysiologiques de lorganisation en taxèmes. Mais par leur contenu, ils reflètent les situations de choix propres aux pratiques concrètes, et relèvent ainsi de conditions culturelles qui diffèrent avec les langues.
2 - La classe de généralité supérieure est le domaine. Chaque domaine est lié à un type de pratique sociale déterminée. Les indicateurs lexicographiques comme chim. (chimie) ou mar. (marine) sont en fait des indicateurs de domaine. Dans les langues écrites des pays développés, on peut compter entre trois et quatre cents domaines. Ce nombre est à rapporter notamment à la spécialisation des pratiques sociales. Leur nombre, leur nature et leur contenu varient selon les cultures.
Tous les taxèmes ne relèvent pas dun domaine : cest le cas notamment des taxèmes grammaticaux, qui, nétant indexés dans aucun domaine, sont de ce fait compatibles avec tous (ex. : la catégorie sémantique du nombre).
Deux tests permettent de différencier les domaines. (i) À lintérieur dun même domaine, il nexiste pas, en règle générale, de polysémie lexicale, car la polysémie résulte notamment de la multiplicité des domaines. (ii) Entre les unités membres d'un même domaine, il ne s'établit pas de connexion métaphorique ; en revanche, les métaphores sétablissent généralement entre domaines différents, et tirent leur effet des différences de valorisation entre les domaines. Par exemple, Chirac transforme un essai contient une métaphore parce que dans notre culture les domaines //sports// et //politique// sont spécifiés et distincts.
3 - Le champ est un ensemble structuré de taxèmes ; par exemple le champ //moyens de transport// comprend des taxèmes comme //autobus, métro, RER//, et //autocar, train//. Dans le discours, des sémènes relevant de différents niveaux hiérarchiques du champ pourront se trouver juxtaposés (ex. « Du vin ou de la badoit ? », « Du beaujolais ou de leau ? »).
Il nest pas certain que les champs soient des classes de langue. Il nexiste pas de critères linguistiques simples pour les mettre en évidence. Ce sont des espaces sémantiques intermédiaires et temporaires qui correspondent à lactivité en cours [25]. Par exemple, consonne est un sémème qui relève du domaine technique de la linguistique, mais non du champ de cet ouvrage, limité à la sémantique.
On a défini jadis les champs sémantiques comme des zones conceptuelles correspondant à certaines réalités physiques (le champ des couleurs, par exemple). À cette définition cognitive et représentationnelle, il nous paraît préférable de substituer une définition opérationnelle : ensemble des taxèmes pertinents dans une pratique concrète [26]. Un champ peut regrouper des taxèmes relevant de domaines différents : dans beaucoup dapplications, on utilise simultanément des taxèmes relevant de différents domaines techniques.
4 - Enfin, les dimensions sont des classes de grande généralité, mais elles ne sont pas superordonnées aux précédentes. En petit nombre, elles divisent lunivers sémantique en grandes oppositions, comme /végétal/ vs /animal/, ou /humain/ vs /animal/. Elles sont souvent lexicalisées (cf. en français vénéneux vs venimeux pour la première opposition, bouche vs gueule pour la seconde).
Les dimensions divisent les domaines ; par exemple, dans le domaine //cuisine//, on distinguera le taxème des cuisiniers (/animé/) et celui des instruments (/inanimé/). En général les éléments dun taxème relèvent des mêmes dimensions. Mais les dimensions évaluatives tracent des seuils dans les taxèmes graduels : ainsi, dans le taxème des degrés de chaleur, chaud et froid relèvent de la dimension évaluative /neutre/, mais passé un seuil, brûlant et glacial appartiennent sauf paradoxe à la dimension /péjoratif/ (de même dans le taxème des tailles pour immense et minuscule relativement à grand et petit).
Les dimensions reflètent vraisemblablement sur le plan sémantique les catégories a priori qui structurent tout lunivers dune culture. Le lexique, remarquait justement Barthes, est de la doxa figée. Les dimensions sémantiques sont des classes doxales qui témoignent de ce figement. Dans la plupart des langues, elles sont grammaticalisées : ainsi en français lopposition on vs ça articule les dimensions /animé/ vs /inanimé/ ; les suffixes -ard et -âtre manifestent la dimension /péjoratif/ (cf. bâtard, jaunâtre). Les différences entre « niveaux de langue » doivent également être rapportées à des dimensions qui sont sans doute des corrélats de la hiérarchisation des catégories et des pratiques sociales [27].
Ces classes ne sordonnent pas selon un degré de généralité croissant, pour mimer un processus de connaissance par abstraction, comme le font les arbres de Porphyre réinventés par les recherches cognitives [28]. En revanche, leur degré de figement est croissant. Les taxèmes peuvent évoluer vite (dans lannée ou la décennie : cf. lintroduction de VAB (pour véhicule de lavant blindé) dans le taxème des blindés, ou celui de trackball dans celui des moyens de commande) ; en outre, ils sont aisément remaniés en discours (cf. infra sur le contexte). Les domaines se constituent et évoluent à léchelle du siècle (ex. le domaine de laviation). Les dimensions évoluent à léchelle du millénaire. Ces trois types de temporalité peuvent être rapportés, respectivement, aux types de systématicité que nous évoquions : celui des normes idiolectales [29], celui des normes sociolectales, et celui du système fonctionnel de la langue.
Corrélativement à ces degrés de figement et à ces ordres historiques, il faut souligner des différences quantitatives : les dimensions sont au plus quelques dizaines, les domaines quelques centaines, les taxèmes quelques milliers (pour une compétence individuelle).
5. La microsémantique et le contexte ![]()
5.1. Pour une théorie
du contexte ![]()
On ne dispose pas en linguistique de théorie générale du contexte. Si la notion de contexte est souvent évoquée, elle est rarement définie. On sait que Bar-Hillel distinguait co-texte (linguistique) et contexte (situationnel). Cette distinction sémiotique a été reprise par nombre de théoriciens du texte. Les spécialistes de l'interaction linguistique y recourent largement, sans donner de rôle particulier au contexte linguistique, puisque leur perspective est pour lessentiel microsociologique. On leur doit donc des définitions très générales. Selon Meyer, le contexte est « ce qui est nécessaire et suffisant comme information pour communiquer à l'interlocuteur la situation du locuteur, donc le sens dans lequel est utilisé le discours (mots, phrases), le sens que ce discours possède » (1979, p. 251). Les définitions de ce genre privilégient l'oral, et la situation hic et nunc, mais la situation ne se résume pas aux circonstances immédiates de la communication entre deux locuteurs, et la lecture ne se laisse pas résumer à une interlocution même différée (cf. Rastier, 1995 a).
Il reste également à théoriser l'incidence de la situation sur le texte, oral ou écrit. Pour cela, il nous paraît nécessaire de distinguer la situation comme type codifié par une pratique sociale, et la situation-occurrence. Puis de préciser l'incidence globale du type sur l'occurrence, par la stipulation des contrats de production et dinterprétation. Ensuite, l'incidence de la situation-occurrence sur le texte global : sélection de stratégies interprétatives, choix des foyers interprétatifs, préactivation de classes et axes sémantiques qui permettront la sélection de faisceaux de sèmes pertinents à la situation, notamment les isotopies.
Il faut encore décrire l'incidence du contexte linguistique global sur le contexte local. Nous distinguons quatre paliers de contextualité : le syntagme, la période, la section (chapitre, chant, etc.), enfin le texte. Chacun de ces paliers détermine les parcours des sèmes en son sein, conformément aux prescriptions du genre et du discours. Et lincidence du texte sur le syntagme est ainsi médiée par les déterminations propres à la section et à la période. Les incidences de ces degrés de contextualité sur les unités étudiées doivent être hiérarchisées.
Dans la mesure où les relations contextuelles sont orientées, on distinguera enfin le contexte actif de chaque unité, constitué des unités proches ou lointaines qui ont une incidence sémantique sur elle, et son contexte passif, composé des unités qu'elle modifie. Cette distinction méthodologique ne doit pas faire oublier que les unités mises en relation sont généralement en interaction réciproque : par exemple, si dans une métaphore le comparé modifie ou précise le comparant, linverse nest pas moins vrai, et si Achille est un lion permet lafférence de /courageux/ dans Achille (et non de /quadrupède/), il y a aussi mise en saillance de /courageux/ dans lion.
Tout cela exige dapprofondir la notion de contexte. En effet, elle reste mal définie en linguistique parce quelle ne se laisse pas réifier par certain positivisme. En effet, alors que le texte appartient au « donné » empirique, tel quon choisit de le décrire, le contexte est choisi (cf. Jucquois, 1986), donc soumis comme tel à des conditions herméneutiques. Dans linterprétation des mots, comme dans linterprétation des textes, le choix du contexte est un acte décisif, qui doit être déterminé par une stratégie (cf. Rastier, 1998 a).
La microsémantique ainsi conçue prend appui sur deux considérations complémentaires : les combinaisons de sémèmes se fondent sur des récurrences de sèmes [30] ; la propagation des sèmes en contexte institue des récurrences là où elles étaient imprévisibles [31]. Enfin, elle laisse toute sa place à lordre herméneutique : l'actualisation des composants sémantiques, même inhérents, est en effet conditionnée par le contexte. Or, les caractères linguistiquement pertinents et perceptivement saillants du contexte dépendent des stratégies et des tactiques de production et d'interprétation. Ces stratégies et tactiques se règlent elles-mêmes sur la pratique en cours.
En deçà, deux opérations interprétatives fondamentales sont à luvre dans lactualisation et la virtualisation des sèmes. La dissimilation opère quand les contrastes sémantiques sont faibles, comme cest notamment le cas pour les tautologies, quelles soient codifiées ou non. Par exemple, dans Une femme est une femme, on affecte toujours une acception différente aux deux occurrences de femme. Lassimilation opère à linverse quand les contrastes sémantiques sont forts (contradictions, coq-à-lâne, cf. infra) ; par exemple, dans une énumération comme des fous, des femmes et des fainéants, on affectera à femme un sème /péjoratif/ [32], par assimilation du sème /péjoratif/ actualisé dans fous et fainéants.
Pour être applicable, une théorie de linterprétation doit articuler les parcours déterminés par la situation de communication (macro-parcours), et les parcours autorisés par les lois de perception sémantique (micro-parcours). Il ny a pas de contradiction entre les stratégies et les opérations élémentaires (ou pas interprétatifs) : il faut cependant tenir compte des problèmes particuliers que pose la perception des objets culturels. Les travaux de Lieberman sur la perception des sons linguistiques ont montré quils étaient discrétisés différemment des autres sons. La perception sémantique est également une perception catégorielle, à la fois immédiate et culturellement apprise. Elle est le substrat perceptif de lordre herméneutique.
5.2. La lexie comme contexte ![]()
Précisons à présent les effets contextuels d'interaction sémantique entre morphèmes à l'intérieur de la lexie. En conservant par souci didactique la perspective combinatoire que nous récusons, nous pourrions discerner trois stades d'assignation des significations morphémiques.
1 - Hors contexte, même celui du mot, le morphème est pourvu de sèmes spécifiques par contraste avec d'autres morphèmes [33]. Par exemple lev- comporte le sème /ascendant/ par contraste avec baiss- (/descendant/) ; ces deux morphèmes comptent en outre un sème générique commun /mouvement/. À ce stade, les morphèmes comportent généralement peu de sèmes génériques à l'exception bien entendu de ceux dont les lexies intégrantes se trouvent toutes dans les mêmes domaines (ex. zorg- pour le domaine //minéralogie//, où lon relève la lexie zorgite).
Pour opérer à ce stade, on ne peut véritablement utiliser l'analyse sémique car elle exige des contextes. Par exemple, si lev- et baiss- constituent une paire, c'est dans un contexte comportant le sème /animé/ (ex. : baisser ou lever le bras) ; dans un contexte comportant le sème /inanimé/, on aura la paire mont- et baiss (ex. la mer monte ou baisse ; le dollar monte ou baisse ; baisser, monter le son).
2 - Dans le contexte de la lexie, les sèmes ne sont pas conservés « tels quels », mais sont soit actualisés, soit virtualisés [34]. Ainsi /mouvement/ est virtualisé dans élève mais actualisé dans certaines acceptions de élévation. En outre, des sèmes domaniaux sont adjoints aux sémèmes combinés, et fixent leurs acceptions. Ainsi élévation, soppose à coupe dans le domaine //architecture//, à 'introït', etc. dans le domaine /religion/, à bassesse dans le domaine //morale//.
Le maintien des doublets pourrait paraître lié à ces distinctions génériques entre sémèmes (cf. dissol- vs dissou- dans dissolu /animé/ vs dissous /inanimé/). Mais il tient en réalité aux effets contextuels de la combinaison des morphèmes, qu'il s'agisse de radicaux ou d'affixes (cf. non résolu /inanimé/ vs irrésolu /animé/).
3 - Enfin, quand la lexie est décrite en contexte sa signification se
trouve en outre modifiée non seulement par actualisation et virtualisation de
sèmes, mais encore par adjonction de sèmes (dits
Ces déterminations de la signification de la lexie par le contexte s'établissent à tous les paliers (syntagme, période, section, texte). Elles sont cumulatives, comme cela apparaît par exemple pour les noms propres dans les récits de fiction. Si bien que dans un texte donné chaque occurrence lexicale pourrait être considérée comme un hapax sémantique, doté dun sens particulier. Du moins le gros bon sens lexicographique ne doit pas faire écarter cette hypothèse, diversement formulée de Schleiermacher à Pottier.
À la combinaison syntaxique des morphèmes dans la lexie ne correspond pas nécessairement une simple composition sémantique des sémèmes dans la sémie. Les sens qui résultent de la mise en relation des sémèmes dans la sémie ne sont pas prévisibles : par exemple pommade ne signifie pas préparation à base de pomme (vs orangeade, rognonnade) ; archère ne signifie pas tireuse à l'arc ni femme d'un archer, etc. Cette non-compositionnalité est encore plus évidente pour des lexies comme à la queue leu leu, à hue et à dia, au fur et à mesure. S'il existe une forme de compositionnalité, elle procède soit de règles cachées (selon l'hypothèse de Corbin, 1988), soit plutôt de normes qui n'appartiennent pas au système fonctionnel de la langue. Ce sont elles qui fixent, de façon d'ailleurs instable, la référence de la sémie.
Le principe frégéen de compositionnalité règle dans les linguistiques formelles (et notamment la Grammaire Universelle de Montague) les rapports entre syntaxe et sémantique. Appliqué aux morphèmes constitutifs d'un mot, ce principe permettrait de prévoir que la signification du mot est uniquement déterminée par la signification des morphèmes qui le constituent et par leur mode de composition. Si composition il y a, elle n'est pas simple. Les significations de ces morphèmes ne « sadditionnent » pas de manière à déterminer entièrement celle du mot. Plutôt quune addition, on pourrait évoquer par image une soustraction : des sèmes incompatibles avec les significations des morphèmes voisins sont exclus. Par exemple dans supérette, le sème /augmentatif/ afférent à super- sera virtualisé par le sème /diminutif/ inhérent à -ette. Et de façon converse, à la « soustraction » vient répondre un surcroît : des sèmes qui n'appartiennent à la signification d'aucun des morphèmes sont actualisés par leur groupement contextuel dans la signification du mot. Ainsi la signification de é- et de lev- ne comporte aucun des sèmes /animé/, /animal/ ou /humain/, pas plus que celle des suffixes -e, -age ou -er. Et pourtant élève comprend le sème /humain/, élevage le sème /animal/, alors que élever aura au moins deux significations différentes selon qu'il comporte le sème /animé/ ou le sème /inanimé/ [35].
À chacun des sèmes dimensionnels ainsi associés au contenu des mots qui incluent élev- s'ajoutent encore des sèmes spécifiques dont ils conditionnent l'actualisation. Le sème /concret/ permet d'actualiser /spatialité/, inhérent à é- comme à lèv- (ex. élever un monument). Le sème /animal/ permettra lafférence de /nourriture/ (un élevage de poulets) ; de même pour /humain/ dans élever mais non dans 'élève' [36].
Cela confirme bien entendu que élève, élever et élevage voient leurs significations déterminées non seulement par celle de leurs morphèmes, mais encore par celle des mots qui entrent dans leurs paradigmes d'interdéfinition (ou taxèmes). Ces lexies diffèrent ainsi parce que ces taxèmes diffèrent. Élevage sera défini par rapport à agriculture, élève par rapport à disciple ou écolier, etc. [37]. De même, les membres d'un couple morphologique comme excursion et incursion sont définis au sein de domaines sémantiques différents. Le principe de compositionnalité ne peut évidemment rendre compte de cette particularité de la sémantique linguistique.
L'incidence de l'interdéfinition au sein des taxèmes sur la signification des mots apparaît clairement dans le cas des évolutions diachroniques. À sa création, téléphérique signifiait transport par câbles aériens, et les dictionnaires témoignent encore de cette acception générale. La création de télécabine, télébenne et télésiège a restreint contrastivement sa signification à transport par câbles dans une cabine unique. Et cependant, si l'on s'en tient à composer la signification de ses morphèmes, téléphérique ne signifie que transport à distance.
5.3. La lexie en contexte
: de la signification au sens ![]()
En passant de la lexie comme contexte à la lexie en contexte, nous ne quittons pas la syntagmatique. On retrouve entre les mots les mêmes types de relations contextuelles que lon connaît entre les morphèmes [38], ce qui montre tout à la fois combien est arbitraire la frontière du mot et combien utile une typologie des relations contextuelles. Il est en outre douteux que le mot soit perçu isolément tant pour son contenu que pour son expression [39]. Nous formulons l'hypothèse qu'il en va de même, corrélativement, pour le signifié des mots, qui serait perçu par des activations contextuelles.
Dans la perspective interprétative qui est la nôtre, c'est le texte qui détermine le sens des mots à partir certes de leur signification en langue, mais en l'élaborant, en l'enrichissant et/ou la restreignant par l'action de normes génériques et situationnelles [40]. Enfin, les significations répertoriées en langue ne sont que des virtualités : la langue propose, les textes disposent. Et si nous estimons qu'on peut à bon droit parler de perception sémantique, c'est aussi que la foule des unités et des relations sémantiques dans le texte a toute la complexité explétive du signal physique où l'activité perceptive sait saisir l'essentiel.
Pour préciser le statut de la lexie en contexte, il nous faut à présent détailler les opérations interprétatives.
6. Les opérations
interprétatives ![]()
Nous allons dabord les décrire dans leurs principes, en laissant ouvert le problème de leur modélisation, que nous aborderons à la fin de cette étude.
Qu'il s'agisse de relations à courte ou à longue portée, les sens des lexies sont déterminés par trois opérations qui transforment les significations répertoriées en langue : l'activation des sèmes, leur inhibition, et la propagation des sèmes activés d'un sémème à un autre. Ces trois opérations obéissent à des lois de dissimilation ou d'assimilation, qui augmentent ou diminuent les contrastes sémantiques. Sans aucunement prétendre à l'exhaustivité, nous allons illustrer ces trois opérations.
a) L'inhibition interdit l'actualisation de sèmes inhérents. Ils sont alors virtualisés. Les usages phraséologiques présentent d'excellents exemples de ce processus. Ainsi monter comprend le sème inhérent /spatialité/, créneau les sèmes inhérents /architecture/ et /verticalité/. Ils sont actualisés dans le chevalier Bayard monte au créneau mais virtualisés dans Rocard monte au créneau. Si ces sèmes ne sont pas supprimés, leur saillance perceptive est diminuée. Que s'est-il passé ? L'explication classique « par la métaphore » n'en est pas vraiment une : elle classe le phénomène plutôt qu'elle ne le décrit. Le contenu Rocard, indexé dans le domaine //politique// induit une allotopie générique avec 'créneau' indexé dans le domaine //guerre//. Réglée ici par le principe d'assimilation, la lecture inhibe certains sèmes qui indexent le sémème dans le domaine //guerre// pour mettre en relief ceux qui sont compatibles avec //politique//. Sil y a violence, par exemple, elle restera verbale. Cependant, dans notre société, les domaines //guerre// et //politique// sont traditionnellement comparés, et le sème /guerrier/ peut être réactivé à tout moment par le contexte [41].
La loi de dissimilation peut aussi inhiber lactualisation des sèmes. Par exemple, dans fromage ou fromage blanc (formule attestée à la carte d'un restaurant) la première occurrence de fromage reçoit une interprétation restrictive relativement à celle quelle revêt dans fromage ou dessert : tous les sèmes inhérents à fromage et qui sont spécifiques de fromage blanc s'y trouvent inhibés [42]. Contrastivement, elle signifie donc fromage fermenté, et le sème /fermenté/ est alors saillant.
b) L'activation permet l'actualisation des sèmes. Elle est nécessaire mais non suffisante. Elle n'intéresse pas les sèmes inhérents, qui composent la signification du mot et se retrouvent, sauf inhibition, dans son sens : en d'autres termes, la sémie-occurrence les hérite par défaut de la sémie-type.
En revanche, elle intéresse les sèmes afférents qui sont présents dans la sémie-type sous la forme de catégories et non de traits spécifiés (ou dans les termes de la théorie des schémas (frames) d'attributs dont on ne connaît pas la valeur). Par exemple, le sème /debout/ n'appartient pas à la signification de bergère : il est simplement un des traits virtuels que l'on peut inférer du sème inhérent /humain/. Pourtant, dans le contexte Bergère ô tour Eiffel, /debout/ est actualisé par la présence du sème inhérent /verticalité/ de tour. La loi d'assimilation sapplique ainsi dans une construction syntaxique équative.
Une fois que les sèmes, inhérents comme afférents, sont actualisés, ils sont susceptibles de revêtir au moins divers degrés de saillance, en fonction des activations supplémentaires quils reçoivent du contexte proche ou lointain. Comme lactualisation, la saillance est soumise à des préconditions herméneutiques.
La loi de dissimilation sapplique dans les phénomènes dantanaclase, où deux occurrences d'un même mot reçoivent de leur contexte immédiat des activations qui les différencient et en font les occurrences de deux acceptions contrastées. Par exemple, dans Un père en punissant, Madame, est toujours père (Racine), la première occurrence de père contient le sème /éducateur/ (activé par le contexte punissant), et la seconde le sème /bienveillant/ par dissimilation.
La dissimilation rend compte aussi de la syllepse, qui confère deux acceptions contrastées à une même occurrence, par activation simultanée de sèmes afférents. Par exemple, dans Tout père frappe à côté (La Fontaine) les deux sèmes /éducateur/ et /bienveillant/ se trouvent simultanément activés, le premier par frappe et le second par à côté. Cet exemple n'a rien d'exceptionnel. Comme la noté Béringer, dans un syntagme comme l'aide substantielle et désintéressée des pays frères du camp socialiste, substantielle active le sème casuel /objet/ et désintéressée le sème casuel /ergatif/. Bref aide manifeste conjointement et indistinctement les deux acceptions ressource (cf. recevoir une aide) et secours (cf. apporter son aide). La perspective lexicographique qui a toujours dominé la sémantique lexicale ne paraît pas en mesure de rendre compte de ces indistinctions, puisquelle invite précisément à distinguer les acceptions.
c) La propagation de sèmes intéresse les sèmes afférents en contexte. Par exemple, écrivain ne comprend ni le sème /mélioratif/ ni le sème /péjoratif/. Lisons toutefois cette notation angoissée de Julien Gracq (Lettrines, II) :
/p/ : /péjoratif/ ; /m/ : /mélioratif/ ; (a) : afférent ; (i) : inhérent ; : activation ; o : inhibition
La qualification et la prédication sont les moyens privilégiés des afférences contextuelles. Par exemple, saladier, défini en langue relativement aux autres pièces de vaisselle de service (jatte, soupière, plat), ne comporte pas spécifiquement le sème /grande taille/. Dans l'Assommoir de Zola (ch. VII) le contexte propage ce trait : « La blanquette apparut, servie dans un saladier, le ménage n'ayant pas de plat assez grand ». Par une caractéristique de la textualité, ce sème sera conservé par défaut dans les occurrences successives.
Le signifié des noms propres illustre bien le phénomène de la propagation des sèmes. En effet, il ne comprend généralement que très peu de sèmes inhérents. Par exemple, Augustine ne comprend que les sèmes /humain/ et /sexe féminin/. Dans LAssommoir, 'Augustine' recevra entre autres les sèmes /strabisme/, /gloutonnerie/, /hypocrisie/, etc., et les conservera sauf modification dans toutes ses occurrences ultérieures [43].
6.1. Les conditions des opérations interprétatives ![]()
1 - Les opérations interprétatives dont nous venons de décrire les effets ne sont pas mises en uvre sans conditions. Elles manifestent au mieux des régularités, non des règles. Dans chaque cas, il convient de distinguer, pour déclencher le parcours interprétatif : (i) le problème quil a pour effet de résoudre ; (ii) linterprétant qui sélectionne l'inférence à effectuer ; (iii) la condition daccueil qui abaisse le seuil dactivation, et permet ou facilite ainsi le parcours. Ces conditions remplies, il faut encore préciser le signifié qui en est la source, et celui qui en est le but.
En règle générale, la morphosyntaxe se définit par rapport à la sémantique comme un ensemble de contraintes sur le tracé des parcours interprétatifs. La sémantique à son tour se définit par rapport à la psychologie comme un ensemble de contraintes sur la formation des représentations mentales.
a) La condition daccueil est nécessaire, mais jamais suffisante. Elle stipule les constructions morphosyntaxiques qui permettent le parcours. Par exemple, il est facilité à lintérieur du même syntagme, que celui-ci soit de forme Déterminant+Nom+Adjectif, ou de forme énumérative (Adj+Adj ou N+N). En revanche, il est inhibé par des barrières syntaxiques, voire interdit par des frontières macrosyntaxiques (que signalent par exemple à lécrit le tiret long ou lalinéa).
b) Le problème interprétatif le plus simple est posé par la discohésion sémantique, par exemple la juxtaposition de sémies contradictoires. Toute discohésion cependant, comme toute cohésion, est construite et non donnée : elle dépend dune présomption propre à la situation interprétative [44].
c) Linterprétant est une unité linguistique ou sémiotique qui permet de sélectionner la relation sémique pertinente entre les sémies reliées par le parcours interprétatif. Parmi les interprétants, il faut souligner limportance des axiomes normatifs implicites (ou topoï).
a) Les distinguos opposent deux synonymes ou parasynonymes. Ils illustrent le fait que si la synonymie n'est pas un fait de langue, elle peut n'être pas non plus un fait de discours. L'équivalence conventionnelle établie dans le contexte d'une définition peut parfaitement être contredite dans le contexte d'un distinguo. Par exemple, la bière est une boisson, tous les dictionnaires en conviennent, mais une buvette peut afficher : « Bières : 6 F, Boissons : 4 F ». Le problème interprétatif est la juxtaposition de la classe et de son élément. La condition d'accueil est la distinction entre les deux propositions. L'interprétant est la distinction juridique et fiscale entre les boissons alcoolisées ou non, qui fait partie de ce que l'on appelle commodément les « connaissances d'univers ». L'opération interprétative est une dissimilation qui actualise d'une part le sème /alcoolisé/ dans bière, qui est la sémie source de lafférence, et le sème /non-alcoolisé/ dans boissons, qui est la sémie cible.
Les figures de syllepse et dantanaclase, dont nous avons donné des exemples plus haut, sont en quelque sorte des distinguos portant sur la même occurrence ou sur deux occurrences dune même sémie.
b) Soit cette définition qui aligne des coq-à-lâne : « Un opéra raisonnable, cest un corbeau blanc, un bel esprit silencieux, un Normand sincère, un Gascon modeste, un procureur désintéressé, enfin un petit-maître constant et un musicien sobre » (Antoine La Motte, épigraphe au livret dAlcyone, de Marin Marais).
(i) Le problème interprétatif est posé par la contradiction entre corbeau et blanc, puisque noir est inhérent à corbeau, et que dans notre tradition ces deux couleurs sont réputées antithétiques.
(ii) La condition daccueil est double : parataxe de lénumération, qui autorise à traiter par le même type de parcours les divers syntagmes quelle juxtapose ; syntagmes de forme Dét.+N+Adj.
(iii) Les interprétants sont une série daxiomes normatifs ou topoï, qui témoignent de la doxa ou opinion supposée commune de l'époque : les beaux esprits sont bavards, les Normands hypocrites, les Gascons vantards, etc.
Les résultats des parcours interprétatifs sont : (i) lactualisation de sèmes afférents socialement normés dans bel esprit (/bavard/), Normand (/hypocrite/), procureur (/avide/), petit maître (/volage/) ; (ii) l'actualisation de sèmes afférents contextuels dans opéra (/déraisonnable/) et dans musicien (/buveur/) ; (iii) linhibition de /noir/ dans corbeau, qui au lieu d'être hérité du type, est remplacé par /blanc/ (sème propagé par détermination) [45].
6.2. Les substrats des opérations interprétatives ![]()
La description sémantique ne se confond pas avec les traitements psycholinguistiques. Nous avons distingué diverses catégories de contextes (linguistique / non linguistique, global / local, actif / passif ; cf. 1998 a). Il nous reste à présent à formuler des hypothèses sur les bases psychophysiologiques des effets de contexte. Elles appartiennent à la mémoire et à la perception.
Les théoriciens de la Gestalt navaient distingué que deux degrés de localité : les contextes proche et lointain. En linguistique, il nous faut distinguer en outre le contexte syntagmatique du contexte paradigmatique ; le premier se définit d'abord par des relations positionnelles, le second par des relations oppositionnelles (qui ont sans doute pour corrélat psychique des relations associatives en mémoire).
Le traitement du contexte syntagmatique dépend en premier lieu de variables positionnelles, qui définissent des distances temporelles et donc des effets de récence. Psycholinguistiquement, la compréhension est dominée par l'oubli : une phrase n'est pas finie que son début est déjà oublié. Par exemple, si dès la fin de la phrase La neige dévalait furieusement la pente on demande aux sujets qui viennent de la lire si le mot avalanche s'y trouve, un sur cinq environ acquiesce. Selon nous, cela indique que le traitement sémantique de la phrase consiste notamment à sélectionner des sèmes pertinents et à les grouper en structures, les molécules sémiques. Si l'on propose au sujet une lexicalisation qui en manifeste lessentiel, il pourra la reconnaître, ce qui confirme au demeurant l'importance des processus descendants dans la perception, et la prééminence du signifié sur le signifiant.
La distance temporelle entre deux unités ne suffit évidemment pas à caractériser le contexte syntagmatique. La morphosyntaxe définit en effet des zones structurelles de localité, telles que les unités qui sont placées sous un même nud syntaxique entretiennent des interactions sémantiques privilégiées. En revanche toute « barrière » syntaxique inhibe les relations sémantiques contextuelles. Certes, les phénomènes morphosyntaxiques sont eux aussi très vite oubliés, mais au cours de la compréhension, ils conditionnent les opérations interprétatives.
Le contexte paradigmatique connaît aussi des distances et des barrières, qui dépendent de la structure du lexique étudié. La distance minimale est celle qui sépare une sémie de son antonyme, comme lont montré les études sur l'amorçage sémantique. Plus généralement, le taxème est la classe dont les distances entre éléments sont les plus faibles. Les frontières des domaines et des dimensions élèvent en revanche des barrières qui ne peuvent être franchies que par des tropes.
6.3. Les domaines de modélisation ![]()
Nous venons de décrire les conditions des parcours interprétatifs dans un langage proche de la résolution de problèmes. Cest là une simplification, conforme aux objectifs pratiques de ce livre, mais dautres descriptions sont évidemment possibles dans divers domaines de modélisation : la logique, la topologie, la psychologie, la psychophysiologie. Selon le type dapplication, et le type dimplantation informatique, on pourra avoir recours à lun ou à lautre, en gardant à lesprit leurs différences.
a) Les opérations interprétatives élémentaires, lassimilation et la dissimilation, diminuent ou accentuent la distance sémantique entre deux unités. Dans une modélisation dinspiration logique, la distance est franchie par inférence, et accusée par instauration dune opposition de contradictoires ou de contraires. Le parcours interprétatif est alors assimilé à un raisonnement.
b) Dans une modélisation dinspiration psychologique, la modélisation la plus satisfaisante est issue de la psychologie de la perception. Cest pourquoi nous avons pu proposer le concept de perception sémantique. Lassimilation, par exemple, sera le résultat de ce que lon appelle le principe de bonne continuation, ou ce que Gombrich, dans le domaine de la perception visuelle, appelait le principe des etc.
c) La modélisation psychophysiologique prend appui sur la neurophysiologie de la perception. On remarque que la perception sémantique tend à discrétiser les contenus proches : cest alors linhibition latérale qui domine. En revanche les contenus bien distincts sont en relation dactivation réciproque (comme lont montré dès la fin du siècle dernier les expériences des associationnistes). Il y a là sans doute un substrat physiologique de la sémantique différentielle.
Il faut tenir compte ici des phénomènes de seuil. En effet, pour réduire une distance sémantique, on peut soit élever lactivation, soit abaisser le seuil de franchissement. Le rôle ou du moins leffet des récurrences de traits sémantiques, et généralement des isotopies, doit être rappelé à ce propos. En effet, la récurrence dun stimulus induit même à court terme une facilitation par abaissement du seuil dactivation. En revanche, les phénomènes généraux de satiété et de blasement sont là pour le rappeler, passé un certain degré de récurrence, leffet inverse dune hausse du seuil peut être observé.
La précompréhension herméneutique, la présomption disotopie et leffet de pertinence qui en résulte pourraient être rapportés à ces phénomènes. Nous entrons alors dans le domaine des parcours complexes (cf. ch. VII).
Les concepts dactivation et dinhibition, transposés au plan sémantique, permettent de rendre compte de lactualisation et de la virtualisation des sèmes. Alors que la modélisation logique, apodictique par principe, ne connaît pas de degrés, la modélisation psychophysiologique représente les sèmes non plus comme les éléments dun ensemble (dans une logique des classes) ou les arguments dun prédicat (dans une logique des relations) mais comme les points saillants dune dynamique, avec les effets de relief variable et darrière-plan caractéristiques des processus perceptifs. Au palier supérieur, la lecture peut être représentée comme une propagation dactivité contrôlée, et dirigée par anticipation et rétroaction.
Limplantation connexionniste, inspirée elle aussi par la modélisation pyschophysiologique et surtout neurophysiologique, se montre apte à simuler les effets de contexte en microsémantique.
6.4. Méthodologie descriptive ![]()
Deux impératifs simposent tout dabord.
1. Il faut sassurer que le corpus traité ait été recueilli correctement et quil est entièrement pertinent pour la tâche à accomplir. Cela permet à lévidence décarter des problèmes de polysémie et déquivalence paraphrastique. Par exemple, en analysant le discours médical, il paraîtrait nécessaire de définir patient et malade, quitte à prévoir une relation de synonymie entre ces sémèmes (qui diffèrent pourtant par des sèmes casuels et évaluatifs). En fait, ils ne se rencontrent pas dans les mêmes contextes : le premier apparaît dans les paroles des médecins à lintention des malades ; le second, dans les paroles quéchangent les médecins entre eux.
Il faut par ailleurs spécifier, en fonction de cette tâche, les unités, les caractéristiques et les relations quil importe de retenir. Ainsi, un lexique destiné à la génération de textes ne sera pas structuré de la même façon quun lexique destiné à lanalyse syntaxique. Ou encore, lélaboration dune terminologie conduira à négliger certaines parties du lexique et à en structurer dautres. En effet, une terminologie néglige les grammèmes (qui généralement ne sont pas spécifiques à un domaine déterminé), et parmi les lexèmes retient pour lessentiel des substantifs ; elle réduit systématiquement la polysémie, et choisit parmi ces substantifs ceux qui lui paraissent aptes à désigner des concepts. Au plan sémantique, ces concepts ne sont que des sémies stabilisées par les normes dune discipline, et déliées de leurs déterminations contextuelles [46].
2. Cela précisé, la méthodologie varie avec les classes que lon doit décrire. En général, les applications sont bornées par les limites dune discipline théorique ou pratique, et se placent à lintérieur dun domaine voire dun champ. La tâche primordiale consiste alors à inventorier et à structurer les taxèmes. Cela suppose de se défaire de certains préjugés ; par exemple, une phrase comme Vous voulez un gâteau ? Ah bon, je croyais que vous vouliez une tarte ! signale simplement que pour une vendeuse en pâtisserie, et dans les usages de la profession, gâteau appartient au même taxème que tarte, au lieu de lui être superordonné [47].
a) Pour définir un taxème, deux voies principales souvrent. La première relève dans le corpus les syntagmes équatifs, en particulier les énumérations. Prenons lexemple du sémème caviar, défini ainsi dans le Petit Robert : « ufs desturgeon », à quoi le Petit Larousse ajoute quils sont salés. Faut-il le définir au sein dun taxème des ufs de poisson consommables, avec poutargue, par exemple ? Le corpus choisi peut en décider autrement. Ainsi, Lévénement du Jeudi titrait le 4.12.1991 : Caviar congelé, saumon louche, foie gras truqué, confirmant ainsi lexistence dun taxème des aliments luxueux de fête. Dans ce genre de contexte, il serait mal venu de définir saumon par rapport à daurade, ou foie par rapport à gésier ; comme dailleurs dinstituer un taxème //louche vs congelé vs truqué//
Le repérage des contextes est lui-même soumis à conditions. En effet, les énumérations peuvent être hétérogènes, et dans certains genres comporter des coq-à-lâne. Même dans les genres techniques, on relève fréquemment des incohérences : si par exemple dans le Courrier du CNRS (80, p. 22) tel « arbre de la sûreté de fonctionnement » distingue à bon droit, parmi les entraves, les fautes, les erreurs et les défaillances, il juxtapose aux entraves, les moyens (comme validation) et les attributs (comme validité) sans que lon puisse conclure quil sagisse dun taxème même idiolectal.
Lautre méthode semploie à loral dans une situation de choix, et repose elle aussi sur lassociation. Par exemple, telle maraîchère répond à qui lui demande des poireaux : Pas de carottes ? ; à qui lui demande des poireaux et/ou des carottes : Des navets ?. Elle confirme ainsi lexistence dun taxème drastiquement fermé des légumes du pot-au-feu. Si on lui demande des aubergines, elle demande : Pas de courgettes ? ; des aubergines et/ou des courgettes : Pas de tomates ?, ce qui établit le taxème des légumes de la ratatouille.
Hors dune situation de choix, il reste toujours possible de faire énumérer par des sujets des légumes ou des oiseaux, avec lobjectif de définir ces classes que Rosch nommait des catégories naturelles. Mais cette situation expérimentale crée sans doute des artefacts, et il faut douter que lautruche appartienne au même taxème que le canari, sauf dans le domaine particulier de la zoologie. Une expérience de laboratoire est toujours passablement scolaire. Dans les pratiques non-didactiques, on aura par exemple à choisir entre le canari et la perruche, mais jamais entre le canari et lautruche. Bref, les classes lexicales varient avec les pratiques sociales : le mot canari na pas la même définition chez loiseleur ou pour lornithologue, et le mot légume semploie dans les restaurants pour désigner indifféremment des frites, du riz ou des coquillettes. Autant déléments pour rappeler que le lexique ne relève pas de la langue ou du moins nest pas une structure unifiée et invariable..
b) En règle générale, il importe de parvenir aux classes les plus restreintes, car cest au sein de ces classes que lon peut faire ressortir les sèmes spécifiques [48]. Prenons lexemple des moyens de transport collectifs. On pourrait penser quil sagit là dun taxème bien défini, où voisineraient lautobus et lautocar, le train et le métro. Les corpus montrent quil nen est rien, et confirment nos hypothèses sur les situations de choix ; par exemple, les notes de frais dune grande entreprise placent sous des rubriques différentes la classe autobus/métro, et la classe autocars/chemins de fer. Ces deux taxèmes diffèrent donc par les traits génériques /intra-urbain/ vs /extra-urbain/, et les oppositions sémiques qui les structurent sont alors identifiables sur la base de ces regroupements [49].
Notons quici encore, les situations concrètes restent déterminantes, et ne correspondent pas toujours aux situations canoniques : si par exemple je demande à un ami Tu rentres à pied ou en métro ? parce quil se trouve à une station de chez lui, cela nentraîne pas que à pied doive soudain figurer dans la classe des transports parisiens.
Remarque La définition des taxèmes a des conséquences théoriques importantes. En effet, les indications méthodologiques que nous formulons permettent des conjectures sur une partie de lordre paradigmatique. On définit traditionnellement un paradigme comme lensemble des unités qui peuvent occuper une même place dans un syntagme. Rapportée à la sémantique, cette définition sapplique par exemple ainsi : la classe des sièges sera définie comme lensemble des lexies qui peuvent compléter il sassit sur... Devra-t-on alors inclure le sol, un rocher ou un tronc darbre dans cette classe ? Lépreuve de la commutation, qui sert à identifier les signes eux-mêmes, en distinguant ceux qui à la même place diffèrent par leur sens, se trouve alors soumise à des préconditions herméneutiques, et notamment à des déterminations propres aux genres et aux textes. Sa portée est dautant plus restreinte quelle ne peut définir que des taxèmes, mais non des domaines ou des dimensions.
c) Une fois identifiés les taxèmes, il reste à les structurer en précisant quels sèmes spécifiques distinguent leurs éléments. Ici encore, des considérations herméneutiques doivent guider la méthodologie. En effet, différents axes sémantiques (dans la terminologie de la sémantique) ou attributs (dans la terminologie de lIA) seront choisis selon les conditions de la description : pour opposer métro et autobus, on peut choisir la catégorie /ferré/ vs /routier/ dans un texte technique, mais aussi lent vs rapide si lon décrit les raisons du choix des usagers, ou en surface vs souterrain si lon dépouille une enquête sur la claustrophobie, etc. Bien entendu, ces divers axes ne sexcluent pas, mais une description pertinente doit rejeter les catégories inutiles.
Corrélativement, les relations qui distinguent les sèmes peuvent être classées en types généraux (comme lopposition ou la gradation) mais doivent être spécifiées selon les corpus : si lon enseigne la docimologie, il conviendra de préciser que deux points séparent assez bien de bien ; si lon décrit la fabrication du caramel, il est important de préciser combien de degrés séparent la consistance dite petit boulé de celle dite grand boulé. En rester au concept de gradation ne suffirait pas. En somme, au lieu den réduire le nombre dans lespoir de contempler les universaux, il convient de multiplier les catégories sémantiques pour adapter les descriptions à leurs objectifs et à leur objet.
d) A fortiori, comme les champs ne sont pas des classes de langue mais des classes de discours dont la définition peut varier avec les pratiques, on ne saurait les définir abstraitement. On peut cependant formuler des recommandations pour les décrire.
En premier lieu, éviter de réifier les champs ad hoc familiers aux linguistes. Tesnière présente ainsi les principaux verbes de don : donner, fournir, procurer, attribuer, distribuer, reléguer, conférer, concéder, déléguer, décerner, prodiguer, administrer, octroyer, destiner, promettre, accorder, refuser, céder, sacrifier, laisser, abandonner, prêter, confier, rendre, payer, rembourser, porter, transmettre, remettre, livrer, envoyer, expédier, demander, enlever, ôter, soustraire, voler. Cette classe est un artefact, qui regroupe des verbes trivalents (à trois actants) dont lobjet nest pas un dire. Rien, sinon ces critères arbitraires ne permet de regrouper ces unités qui relèvent de différents taxèmes, de divers domaines (juridique, commercial, entre autres) et dimensions (comparer par exemple le « niveau de style » de donner et doctroyer).
Même à lintérieur dun domaine technique, comme par exemple la chirurgie, il faut tenir compte de la structure des champs. Si lon constitue un champ des gestes chirurgicaux, on ne peut juxtaposer ablation et thyroïdectomie. Il faut distinguer des degrés de généralité en constituant des arbres taxinomiques. Les champs sont dailleurs les seules classes qui se laissent structurer entièrement de cette façon, du moins dans les discours techniques ou scientifiques, qui sont précisément, dans notre tradition, organisés selon les principes aristotéliciens de la classification.
e) En règle générale, chaque application se situe dans un champ. Cest la discipline scientifique ou technique qui le délimite et le structure en fonction de ses règles et de ses objectifs. Pour cette raison sans doute, certains auteurs comme Coseriu ont proposé dexclure tout bonnement les lexiques spécialisés de la description du lexique général de la langue. Ce serait une erreur à nos yeux, car il nexiste pas de lexique général (pas plus que de texte sans genre), dans la mesure où tout usage linguistique est situé dans et par une pratique déterminée. Certes, bien des lexèmes et presque tous les grammèmes sont employés dans des pratiques diverses, et y connaissent des acceptions et emplois divers. Mais cette polymorphie nest pas une neutralité.
f) Sauf exception, les applications se situent ainsi dans un espace inférieur au domaine. Par exemple, un manuel dentretien aéronautique ne traite que certains champs dans ce domaine. Seuls certains textes didactiques présentent la structure dun domaine dans son intégralité. Deux modes de relations entre domaines sont à considérer.
Soit lon trouve dans un domaine une réplique dun autre : par exemple, dans un contrat dassurance, on pourra évoquer des risques liés à la spéléologie ou à la plongée sous-marine. Mais ces répliques sont partielles et ne conservent pas la structure du domaine source, puisquelles obéissent aux critères de pertinence du domaine cible.
Soit encore, deux domaines sont connectés. Les connexions les plus étudiées ressortissent à la thématique, et la métaphore est leur emblème. Mais il existe dautres sortes de connexions, dialectiques, dialogiques ou tactiques (cf. lauteur, 1989b). Le contenu de ces connexions dépend de la hiérarchisation sociale des pratiques représentées par les domaines. La « promotion du sens » que selon Ricur permet la métaphore tient au fait que la tradition situe le domaine comparant dans une dimension évaluative supérieure à celle du domaine comparé.
Les discours mythiques (philosophiques, religieux, littéraires) mettent ordinairement en jeu plusieurs domaines, puisque leur objectif est de rechercher voire de donner un « sens » à la vie, considérée ici sous langle du lexique. Le roman moderne présente lexemple dun genre totalisant : le Bouvard et Pécuchet de Flaubert récapitule ainsi dérisoirement tous les domaines.
g) Les dimensions sémantiques posent des problèmes de description à trois niveaux du lexique. Dans leur interaction avec les taxèmes, il faut tenir compte des changements de seuils évaluatifs, toujours possibles dans un corpus ou un contexte donné. Par exemple, dans un procès pour infanticide, laccusée se défendit ainsi : « Je voulais seulement labandonner ! », présentant ainsi labandon comme une pratique acceptable.
Dans leur interaction avec les domaines, les dimensions diffèrent selon quelles englobent le domaine, le divisent en groupes de taxèmes, ou traversent ses taxèmes.
Enfin, certaines dimensions sont relatives à des types de discours. Cest dans les discours mythiques que lon trouve les exemples les plus clairs. Les trois « styles » classiques sont présentés par Servius dans son commentaire de Virgile, et leur distinction a été maintenue pendant quinze siècles dans toute la littérature occidentale. Ces tons humble, modéré, et noble correspondent à autant de dimensions dans lesquelles sont indexés les sémèmes : par exemple, le narrateur de La Divine Comédie nomme un vieillard vecchio en enfer, veglio au purgatoire et sene au paradis. Une étude de la sémantique des tons reste à conduire systématiquement.
En règle générale, si la tâche lexige, les applications même descriptives peuvent prendre toute liberté avec la structure du lexique décrit, et même le doivent. Cependant, si lon choisit de négliger certains aspects du lexique parce quils sont peu ou pas pertinents pour la tâche, il faut avoir en vue lensemble de la problématique, pour pratiquer une réduction méthodologique à bon escient et non par ignorance. Par exemple, pour travailler sur des corpus techniques, on peut négliger certains types dafférence si lon doit composer une terminologie qui recueille les acceptions standard et non des emplois particuliers.
La construction dun lexique doit cependant tenir compte de considérations herméneutiques, et particulièrement des contrats interprétatifs : ceux des textes « pratiques » excluent certaines formes de polysémie, comme la syllepse ou la métaphore in absentia ; ceux des textes « mythiques », surtout en poésie lyrique, lautorisent sinon la prescrivent.
7. Application : un système dinterprétation en contexte ![]()
En nous attachant particulièrement à la construction dynamique du sens lexical en contexte, nous avons cherché à différencier automatiquement non seulement les significations, mais les acceptions d'une classe restreinte de lexèmes. Pour cela, nous utilisons des règles d'activation et d'inhibition des sèmes. Un petit système, purement expérimental, a été mis en uvre par Sylvie Brugère (1990), dans le cadre dun travail universitaire [50]. Il fonctionne en contexte ouvert mais la rançon de cette ouverture réside dans sa restriction à un seul champ, celui de la parenté proche.
7.1. Problématique ![]()
Par ambiguïté lexicale, on désigne en IA deux sortes de phénomènes :
(a) L'homonymie, qui est traitée par spécifications morphosyntaxiques (ex. : vers [Prép.] vs vers [N.]) et, à défaut, par spécifications sémantiques qui mettent en jeu des traits génériques. Par exemple, la distinction entre 'avocat'1 /humain/ et 'avocat'2 /végétal/ met en jeu des restrictions de sélection (sèmes dimensionnels) ; la distinction 'avocat'1 /justice/ vs 'avocat'2 /alimentation/ met en jeu des sèmes domaniaux.
(b) La polysémie de significations entre contenus possédant un noyau sémique commun (par exemple les diverses significations de rayon ou de plateau) est traitée par les mêmes spécifications sémantiques que l'homonymie.
Toutefois, un troisième type de phénomènes est resté inaperçu en IA : la polysémie d' acceptions (cf. Martin 1983, ch. II). Elle distingue par exemple minute1 (soixantième partie d'une heure) de minute2 (court espace de temps). Or, si lon veut parvenir à une représentation un peu fine du contenu lexical, il est indispensable de traiter la polysémie dacceptions. Et pourtant, les restrictions sémantiques généralement utilisées (restriction de sélection et lexiques scripturaux) [51] sont inopérantes en la matière puisqu'elles se bornent à différencier des sèmes génériques, et que les acceptions d'un même sémème possèdent par principe les mêmes sèmes génériques. Il faut donc pour les différencier recourir à lanalyse des sèmes spécifiques.
Si deux acceptions possèdent les mêmes sèmes génériques, c'est parce qu'elles ne constituent pas deux sémèmes distincts, mais deux occurrences différentes d'un même sémème-type. Or les occurrences sont susceptibles de différer du type parce qu'elles sont modifiées par le contexte : il active ou inhibe certains de leurs composants sémantiques.
7.2. Objectifs ![]()
Voici à quelles conditions et dans quelles limites nous avons traité la polysémie d'acceptions :
(a) Nous nous restreignons à la classe lexicale [52] de la parenté proche (frère, soeur ; mère, père ; fils, fille ; mari, femme) ; soit trois taxèmes (//filiation//, //alliance//, //fraternité//). La paire fille et garçon nappartient pas à ce champ, mais elle est traitée pour écarter les ambiguïtés.
(b) Les entrées sont des séquences textuelles déjà attestées contenant des occurrences du vocabulaire choisi. Leur nature et leur nombre sont indéfinis a priori.
(c) Le traitement consiste à interpréter les sémèmes-occurrences en identifiant le sémème-type correspondant, puis en y activant ou inhibant certains sèmes en fonction du contexte.
(d) La sortie précise sous forme de définition la composition sémique de loccurrence, son contexte probable (sans contre-indication pour le système), et le cas échéant les autres acceptions possibles, présentées par ordre de plausibilité décroissante.
Remarque Les acceptions dites métaphoriques sont alors traitées de la même manière que les « sens littéraux ». Nous estimons en effet que la distinction littéral / métaphorique, douteuse théoriquement, ne recouvre pas des différences de nature, mais de degré ; de même pour la distinction dénotation / connotation.
7.3. Conditions danalyse ![]()
A. Le corpus utilisé en entrée est la banque de données textuelles de l'Institut National de la Langue Française, ici limitée à un sous-corpus (Les mots de Sartre).Le Trésor de la Langue Française est utilisé pour la constitution de la base de faits et la base de règles.
B. La base de faits stipule la constitution sémique des sémèmes-types, en distinguant les sèmes génériques et les sèmes spécifiques. Soit par exemple pour père : sèmes génériques : (1) /animé/, (2) /humain/, (3) /adulte/, (4) /ascendant/, (5) /géniteur/, (6) /masculin/ ; sèmes spécifiques : (7) /éducateur/, (8) /bienveillant/, (9) /valorisé/, (10) /sacré/. Dans chaque groupe, les sèmes sont ordonnés par degrés d'inhérence ; par exemple, pour mère, /bienveillant/, devra venir avant /éducateur/ [53].
C. La base de règles comprend des règles dont la partie action ordonne la sélection d'un sème ou d'un groupe de sèmes ; leur partie conditions stipule des conditions graphiques, morphosyntaxiques, distributionnelles (tactiques), sémantiques, qui peuvent être combinées entre elles sans limitation.
a) Les règles de sélection de sémèmes-types comprennent dune part des règles à conditions graphiques et morphologiques. En voici des exemples pour père : (i) si pluriel, et si précédé d'un possessif, alors sèmes 2, 3, 4 : (aïeux) ; (ii) si pluriel, et majuscule, alors sèmes 2, 3, 6, 7, 9, 10 (Pères de lÉglise) ; (iii) si singulier, et majuscule, alors 6, 7, 8, 9, 10 ('Dieu le Père') ; (iv) si adjectif ou précédé d'un tiret, alors 4 (ex. :le processus-père, le nud-père), et inhibition des autres sèmes [54].
Elles comptent dautre part des règles à conditions d'antonymie. Par exemple pour femme : (i) si mari dans le contexte, alors femme (épouse) ; (ii) si homme, sans possessif, dans le contexte, alors femme2 (adulte de sexe féminin).
On définit enfin des distances positionnelles (exprimées en nombre de mots) et des distances syntaxiques qui conditionnent lapplication des règles (distance 1 : même syntagme ; 2 : même énoncé ; 3 : même période ;4 : période adjacente).
b) Les règles de construction d'acceptions opèrent par assimilation ou présomption de récurrence sémique. La cooccurrence de contextes prédéterminés active tel ou tel sème. Par exemple, pourpère : si punir, frapper (ou l'un de leurs dérivés ou synonymes), sévère (ou l'un de ses dérivés ou synonymes), alors activer le sème 7(/éducateur/).
Elles peuvent opérer aussi par dissimilation. Dans le cas d'une répétition à une distance syntaxique ou distributionnelle proche, l'activation d'un sème dans une occurrence entraîne l'activation d'un autre sème, conventionnellement couplé, dans l'autre occurrence. Par exemple dans le vers de Racine cité plus haut (Un père en punissant, Madame, est toujours père), le système active dans la première occurrence le sème 7 (/éducateur/) et dans la seconde le sème 8 (/bienveillant/).
Remarque Si à chaque sème sont associés des contextes d'activation, on ne peut raisonnablement stocker toutes les inférences possibles (si l'on veut pouvoir traiter des extraits divers). Par exemple, le système activera 7 dans Tout père frappe à côté (La Fontaine), mais il ne pourra activer simultanément 8 (inféré de à côté) faute d'une règle ad hoc du type : si frapper à côté alors activer /bienveillant/.
7.4. Architecture et mise en uvre ![]()
Après lanalyse morphologique de la suite textuelle, le système procède à une recherche dindices. Sil trouve un indice décisif, il fournit une réponse en stipulant un sémème type. Par exemple, dans Anne-Marie, la fille cadette, passa son enfance sur une chaise, lindice décisif est cadette, et lacception de fille est ainsi définie : jeune personne de sexe féminin considérée par rapport à son père ou à sa mère. Pour la suite dans un café quand un garçon tarde à prendre la commande, Charles Schweitzer sempourpre de colère patriotique, lindice décisif est prendre la commande, et lacception retenue est serveur dans un café.
Si le système ne trouve pas dindice décisif, il calcule la vraisemblance des acceptions candidates, et en présente une liste ordonnée. Par exemple, dans Elle lui fit quatre enfants par surprise : une fille qui mourut en bas âge, deux garçons, une autre fille, les acceptions retenues sont dans lordre : (i) jeune personne de sexe féminin considérée par rapport à son père ou à sa mère (indice : faire+déterminant+enfant), (ii) jeune personne de sexe féminin dont le sexe est souligné (par antonymie relativement à garçon).
La hiérarchisation des indices pose des problèmes délicats. Dans il fit connaissance de Anne-Marie Schweitzer, sempara de cette grande fille délaissée, lui fit un enfant au galop, moi, et se réfugia dans la mort, le système distingue les deux acceptions jeune personne de sexe féminin considérée par rapport à son père ou à sa mère (indice : faire+déterminant+enfant), et personne de sexe féminin non mariée mais en âge de lêtre (indice : épousa), mais il les hiérarchise incorrectement.
Les systèmes de ce genre rencontrent évidemment une limitation qui mérite dêtre soulignée : faute de pouvoir mettre en uvre des stratégies interprétatives, ils en sont réduits à combiner des indices locaux, alors que les difficultés quils rencontrent témoignent de lincidence du global sur le local. Il faudrait donc leur adjoindre un composant qui mette en uvre une stratégie interprétative.
[*] N.B. : Ce texte est élaboré à
partir du chapitre 3 de Sémantique pour lanalyse (Paris, Masson,
1994) révisé pour la traduction anglaise de cet ouvrage : Semantics
for descriptions, Chicago University Press, CSLI Lectures Notes,
138, avec la collaboration, pour les ch. 4 et 6 de Marc Cavazza et Anne
Abeillé.
Pour cette publication, jai tiré profit des suggestions de Carine
Duteil et Evelyne Bourion, que jai plaisir à remercier ici.
![]()
NOTES
[1] Pour une discussion sur cette conception, et ses rapports avec l'arbre de Porphyre, cf. Rastier, 1991 b, ch. VII. Certes, la théorie de la typicalité élaborée en psychologie par Rosch et ses collègues a influencé aussi les théories du lexique en IA et en linguistique, mais cest à tort quelle a été présentée comme une nouveauté radicale (cf. Kleiber, 1991), car elle ne rompait pas véritablement avec les présupposés classiques. Au contraire, elle a poussé à lextrême leurs incohérences. Par exemple, Rosch estime quil existe des catégories naturelles, comme les oiseaux, et quelles sont structurées par des degrés de typicalité : le canari serait typique, lautruche peu typique. Outre que lautruche nest pas un canari déviant, ces conclusions établies sans tenir compte des contextes culturels restent passablement ethnocentriques.
[2] Un « sens » serait le prototype des autres.
[3] Dans les recherches cognitives, on utilise plutôt le mot concept, ce qui traduit une position mentaliste, et crée une confusion avec les emplois techniques de ce mot en logique et en philosophie. Dans la mesure où il est considéré comme indépendant des langues, le concept ne relève pas de la linguistique.
[4] Il est douteux que le mot soit une unité phonique. Sil a vraisemblablement une existence psychologique, cela ne suffit pas non plus à linstituer en unité sémantique.
[5] Les primitives ne sont telles que par décision méthodologique : comme les composants, elles sont complexes, mais leur dénomination lexicalise de façon analytique ce que les sémies quelles servent à définir lexicalisent de façon synthétique.
[6] Putnam définissait le mot water en donnant notamment la formule chimique de leau, et Petöfi fait de même pour chlore.
[7] Jemprunte ce concept, parmi dautres, à Pottier. Le mot n'est pas un signe, mais seulement une unité de signifiant, essentiellement graphique, commode en lexicographie. Les véritables unités fonctionnelles à ce palier de la langue sont le morphème et la lexie. Il ne nous paraît pas linguistiquement fondé de faire correspondre mot (lexical) et concept, comme on le fait pourtant communément en Intelligence Artificielle.
[8] Les sèmes ne sauraient être confondus avec des conditions nécessaires et suffisantes pour assurer la dénotation du mot, comme on le voit chez Morris ou Fodor. Ces conditions sont les héritières de la quiddité aristotélicienne (une chose se définit par tout ce quelle est nécessairement, cest-à-dire par tout ce quelle ne peut pas ne pas être). En revanche, pour la sémantique différentielle, un sémème se définit par tout ce quil « nest pas ».
[9] Les exemplaires les plus typiques d'une catégorie sont en général « connotés » ; en cela, ils possèdent des traits qui n'appartiennent pas aux autres exemplaires de la catégorie. Cf. sur ce point 1991 b, ch. VII, sur les parangons.
[10] La représentation d'attributs facultatifs suppose de prévoir des sections conditionnelles du graphe qui représente le sémème.
[11] Cf. la phraséologie, lacception délateur anonyme', et même la fable de La Fontaine.
[12] Une théorie linguistique qui négligerait ce problème sous prétexte qu'il relève de la performance ou de la parole (au sens saussurien) resterait incomplète.
[13] Voici les éléments du débat. Dans le Trésor de la langue française,
les principales définitions de lueur sont : « (i) Lumière qui
na pas un plein éclat, (ii) Lumière qui apparaît soudainement, mais qui est
éphémère » ; et, dans le grand Robert, on relève notamment :
« Lumière faible, affaiblie ou diffuse ; lumière éphémère.
Remarque :
on emploie parfois lueur en parlant dune lumière vive et
durable ». Piotrowski estime alors « quil savère impossible de
rapporter les différentes acceptions du lexème lueur sous un sémème commun cohérent,
i.e. non contradictoire » (1993, p. 72). Mais si lon convient que les
deux attributs qui définissent laspectualité et lintensité ne prennent leur
valeur quen contexte, il suffit de noter /+ ou - intense/ et /+ ou
- duratif/ dans le sémème-type. Il reste certes à actualiser les valeurs
en fonction du contexte. Par exemple (je suis en partie Piotrowski), dans
« la lueur mate des petits abat-jour jaunes [
] créait autour du banquet
une atmosphère languissante et recueillie » (Martin du Gard), le trait /-intense/
actualisé en fonction dindices contextuels comme mate, abat-jour, jaunes, recueillie,
et le trait /+duratif/ par languissante, sachève (imperfectif), recueillie.
Certes, on relève des contextes moins nets, comme « à lhorizon, on
pouvait apercevoir des lueurs », mais aucun nest «neutre». Par exemple, à lhorizon et
apercevoir
renforcent le trait /- intense/, alors que limparfait
(imperfectif), et même le on, renforcent le trait /+ duratif/.
[14] Zola, Madeleine Férat. Cité par Martin, 1983.
[15] Létablissement de tous ces liens dépend de conditions interprétatives globales (discours, genre du texte, objectif de la description).
[16] Le maintien de la distinction entre sèmes et primitives favorise une mise en uvre informatique par les méthodes classiques, car elle saccorde avec la distinction logique entre prédicats et arguments. En revanche, son abolition relève dune problématique associationniste, et convient en cela à une implantation connexionniste.
[17] La tripartition syntaxe/sémantique/pragmatique conduisait à séparer le lexique de la syntaxe, doù une foule de faux problèmes.
[18] Nous rejetons la distinction proposée par Vendryès entre mots représentant des idées et mots représentant des relations entre ces idées, comme celle de Marty entre éléments autosémantiques et synsémantiques, qui conduisait Ullmann à éliminer les premiers du vocabulaire pour les étudier dans la syntaxe. Enfin, l'opposition reçue aujourd'hui en pragmatique "intégrée" entre lexèmes et connecteurs nous paraît reformuler pour lessentiel la distinction entre termes catégorématiques et syncatégorématiques proposée au sixième siècle par Priscien.
[19] Il conviendrait en effet de distinguer la polysémie du mot et celle du morphème.
[20] C'est pourquoi la pragmatique s'est emparée de certains d'entre eux, dénommés connecteurs à l'image des connecteurs de la logique. C'est pourquoi aussi Récanati déclare que ces « mots du discours [ ] n'ajoutent rien à la signification de l'énoncé » (1982, p. 6).
[21] La prudence s'impose bien entendu, et en synchronie un morphème n'a pas nécessairement de trait inhérent commun à toutes ses combinaisons : cf. can- dans canin, canine, canicule, voire canari et Canaries.
[22] Cf. Rastier, 1989, II, ch. V.
[23] Le postulat mentaliste de la sémantique cognitive la dissuade en fait de formuler des tests linguistiques pour définir des classes lexicales quelle estime mentales.
[24] En dautres termes, il existe en français un taxème des moyens de transport collectifs intra-urbains. Son existence se vérifie dans les corpus, où lon trouvera des énoncés comme « Tu prends le bus ou le métro ? », et non « Tu prends lautobus ou lautocar ? ».
[25] En termes psycholinguistiques, ils correspondraient à la mémoire de travail.
[26] Les bornes du champ sont ainsi ad hoc et temporaires.
[27] Dans certaines langues, le lexique varie avec les castes ou les sexes.
[28] Les réseaux taxinomiques en IA (Winograd, 1977), en psychologie (Rosch, 1978), en anthropologie (Berlin et Kay) reprennent limage dune inclusion croissante.
[29] Il existe des taxèmes idiolectaux dans le langage privé (familial ou câlin) ; mais surtout les taxèmes les mieux institués sont susceptibles de modifications idiolectales, par exemple dans les plaisanteries.
[30] Les restrictions de sélection reconnues par la linguistique américaine depuis Bloomfield rendent compte de phénomènes de cet ordre, mais considérés au palier supérieur (méso-sémantique).
[31] Les corrélats psychologiques de ces phénomènes sémantiques sont bien établis par les travaux sur l'amorçage (depuis les expériences de Meyer et Schvaneveldt), et sont compatibles avec les théories néo-associationnistes qui se développent aujourd'hui avec le connexionnisme.
[32] La syntaxe joue ici un rôle qui demeure secondaire : par exemple, les constructions parataxiques favorisent certes les propagations de sèmes, mais ne suffisent pas à les imposer. Nous détaillerons plus loin le mécanisme de ces afférences.
[33] Il existe des paradigmes à tous les degrés de la description linguistique : des morphèmes, mots, et syntagmes (ex. pommes de terre sautées vs pommes de terre frites), jusquau texte (les genres sont aussi des formes paradigmatiques).
[34] Cela correspond à des inhibitions ou à des activations (cf. infra).
[35] En d'autres termes, élève dans le contexte d'un sémème comportant le trait /animal/ (ex. : ce chien est mon élève), comme élevage dans un contexte comportant le trait /humain/ (ex. : l'élevage des enfants riches) induisent des allotopies en français contemporain.
[36] Ces compatibilités imprévisibles dépendent en dernier ressort de normes sociales : on ne nourrit pas ses élèves, mais les enfants qu'on élève. Autre exemple : archère signifie 'meurtrière' et non 'femme archer' ou 'femme d'un archer' comme on pourrait l'attendre par similitude avec bouchère, d'une part parce quarcher n'est plus un métier, de l'autre parce que les femmes jadis ne tiraient pas à l'arc.
[37] Nous avons laissé de côté la question de savoir si, outre é- et lev- , il existe un morphème élev- en français. Nous tenons pour la décomposition, car lever, lève (nom féminin), levage sont amplement attestés.
[38] D'ailleurs la syntaxe interne du mot n'est qu'un des paliers de la syntaxe.
[39] La synthèse de la parole par mot isolés est fort peu ergonomique, car l'absence de variations contextuelles et surtout de prosodie gêne l'identification des phonèmes. En effet les relations contextuelles entre phonèmes sont très riches (cf. e.g. l'harmonisation nasale en guarani) et obéissent à des règles d'assimilation qui induisent des isophonies à quoi peuvent répondre en poésie des isotopies sur le plan sémantique.
[40] Dont la sémantique ici encore ne peut se dessaisir au profit de la pragmatique.
[41] La suppression totale dun sème est un phénomène diachronique. Par exemple, dans une expression complètement figée comme à la queue leu leu, les sèmes /canin/ et /sauvage/ dans leu (qui signifiait loup en ancien français) se trouvent neutralisés.
[42] Certes, fromage blanc est une lexie, commutable avec dautres, comme compote ou ici fromage. Mais ce sont bien deux sémies, celle de fromage et celle de fromage blanc, dont nous soulignons ici le contraste.
[43] Nous traitons selon les mêmes principes de définition le signifié des noms propres et celui des noms dits substantifs : sauf parti-pris métaphysique qui en ferait les corrélats dessences différentes, ils sont régis par les mêmes conditions interprétatives.
[44] Dans les termes de lherméneutique philosophique, le problème serait le corrélat sémantique dune question, et la présomption, celui dune attente.
[45] La contradiction entre corbeau' et 'blanc' joue le rôle « d'îlot de confiance », et permet de situer la phrase dans le genre du paradoxe. Les sémies mises en relief, en fonction de la situation de la phrase, relèvent du domaine //musique// et se trouvent en position symétrique au début et à la fin de la phrase : chacune reçoit une des deux afférences contextuelles, qui ne sont pas sans rapport (si alcool, alors déraison). Dans cet exemple et ceux qui suivent, nous ne tenons compte que du statut des sèmes, sans préciser les structures sémantiques des syntagmes (gradations, successions dialectiques, etc.).
[46] On peut appeler conceptuelles ces formations sémantiques : peu importe, si l'on convient que le conceptuel est du sémantique allégé.
[47] La recherche des superordonnés réserve des surprises, comme celle du touriste anglais qui demande au serveur : « Quest-ce quune bavaroise ? », et sentend répondre : « Cest un petit diplomate ! ».
[48] Cette recommandation méthodologique est issue de lexpérience des descriptions, mais saccorde avec les résultats des expériences sur lamorçage menées en psychologie depuis une vingtaine dannées.
[49] Cf. Rastier, 1987 a, pp. 51-52. On relève sur le même document lopposition avions/taxe aéroport (où avions signifie prix du billet).
[50] Ses principes ont été présentés dans Rastier, 1987 b.
[51] Un lexique scriptural (scriptal lexicon) est un lexique lié à un script, cest-à-dire à une certaine sorte de champ sémantique.
[52] Dans la perspective interprétative adoptée, nous partons des expressions pour leur assigner des sens. Aussi, hors des classes sémantiques minimales retenues, nous aurons à rendre compte de 'femme'2(vs 'homme'), 'femme'3 (vs 'fille'), 'fille'2 (vs 'garçon'), etc.
[53] C'est là un reflet de la hiérarchie des rôles sociaux tels qu'ils apparaissent dans le corpus.
[54] Sauf 1, dans un contexte comportant le trait /animé/ ; ex. : la cellule-mère, la plante-mère.
BIBLIOGRAPHIE
ABEILLÉ A. L'unification dans une grammaire d'arbres adjoints : quelques exemples en syntaxe française, TA Informations, 30 :1-2, 69-112 (1989).ABEILLÉ A. Les nouvelles syntaxes : grammaires d'unification et analyse du français. Paris, Armand Colin (1993).
ABEILLÉ A. The flexibility of French idioms : a representation within Lexicalized TAGs, in Schenk A., Van Der Linden E. (éds.), Idioms, Lawrence Erlbaum Associates, Hillsdale (New Jersey) (1994).
ABEILLÉ A. Une grammaire lexicalisée d'arbres adjoints pour le français. Thèse de Doctorat, Paris VII (1991, à paraître aux éditions du CNRS).
ABEILLÉ A. (éd.) Analyseurs syntaxiques du français, TA Informations, 32 : 2 (1991).
ABEILLÉ A., Schabes Y. Non compositional discontinuous constituents in TAG, in Van Horck A., Sijtsma W. (éds.), Actes du colloque Discontinuous Constituency, Tilburg (1990).
ADAM J.-M. Eléments de linguistique textuelle. Mardaga, Bruxelles (1990).
ADAM J.-M. Les textes : types et prototypes. Nathan, Paris (1992).
ANDLER D. Le cognitivisme orthodoxe en question, Cahiers du C.R.E.A., 9, 7-105 (1986).
ARISTOTE De l'interprétation, trad. J. Tricot. Vrin, Paris (1965).
ARNAULD A., NICOLE P. La logique ou l'art de penser. Flammarion, Paris (1970 [1683]).
ASLANIDES S., DANLOS L. Génération d'un texte à partir d'un graphe événementiel dans le formalisme TAG, Actes Colloque ILN, IRIN, Nantes (1993).
AUBENQUE P. (éd.) Concepts et catégories dans la pensée antique. Vrin, Paris (1980).
AUBENQUE P. Le problème de lEtre chez Aristote. PUF, Paris (1962).
AUGUSTIN SAINT De trinitate, éd. Migne, J.-P., Garnier, Paris, t. XLII, 819-1098 (1886).
AUGUSTIN SAINT La doctrine chrétienne, in Combès G. et Farges (éds.), Oeuvres de Saint Augustin, Desclée de Brouwer, Paris, t. IX, 152-423 (1947).
BAKHTINE V. N. Esthétique de la création verbale. Gallimard, Paris (1984).
BALLÒN AGUIRRE E., CERRÒN-PALOMINO R. & CHAMBI PAPAZA E. Vocabulario razonado de la actividad agraria andina. Cuzco : Monumenta Lingüistica Andina (1992).
BARATIN M., DESBORDES F. L'analyse linguistique dans l'antiquité classique : I - Les théories. Klincksieck, Paris (1962).
BARBOTIN E. (éd.) Quest-ce quun texte ? Eléments pour une herméneutique. Corti, Paris (1975).
BARTHES R. Texte (théorie du), Encyclopaedia universalis, t. 15 (1977).
BARTLETT F. Remembering. Cambridge University Press, Cambridge (1932).
BEACCO J.-C. Les genres textuels dans lanalyse du discours, Langages, 105, 8-25 (1992).
BENVENISTE E. Problèmes de linguistique générale, Gallimard, Paris, t. I, (1966).
BÉRARD-DUGOURD A, FARGUES J. & LANDAU M.C. Natural Language Analysis using conceptual graphs. Proceedings of the International Computer Science Conference , Hong-Kong (1988).
BÉRINGER H. Disambiguization with purely linguistic knowledge, Actes AFCET, 9 p. (1989).
BERLIN B., ET KAY P. Basic Color Terms : Their Universality and Evolution. Berkeley (Cal.), University of California Press (1969).
BLANCHE-BENVENISTE C., STEFANINI J. & HANDEN-EYNDE K. Pronom et syntaxe : lapproche pronominale et son application. SELAF, Paris, 2e éd. (1987).
BLANCHE-BENVENISTE C. (dir.) Le français parlé. Editions du CNRS, Paris (1990).
BOBROW D. & COLLINS A. (éds.) Representation and Understanding : Studies in Cognitive Science. Academic Press, New York (1975).
BORGMANN A. The Philosophy of Language. Historical Foundations and Contemporary Issues. Mouton, La Haye (1974).
BREAL M. Essai de sémantique. Hachette, Paris [rééd. Brionne, Gérard Monfort, 1982] (1897).
BRECKLE H. Sémantique. Armand Colin, Paris (1974).
BROWN G., YULE G. Discourse Analysis. Cambridge University Press, Cambridge (1983).
BRUGÈRE S. Étude dun système de traitement de la polysémie dacceptions, Mémoire, Université de Paris XI (1990).
BRUGMAN C., LAKOFF G. Cognitive topology and Lexical Networks, in Small S. et alii, Lexical Ambiguity Resolution, Kaufman Press, New York (1988).
BÜHLER K. Le modèle structural de la langue, Langages, 107, 55-61, (1993) [Travaux du cercle linguistique de Prague, 6, 1936].
BÜHLER K. Sprachtheorie. Stuttgart, Fischer (1965 [1934])
CARCAGNO D., DE CHARENTENAY C. Un modèle de lexique fondé sur une sémantique intensionnelle et son utilisation dans l'analyse de texte, Actes Cognitiva, Paris (1987).
CARNAP R. Meaning and Necessity. Harvard University Press, Cambridge (Mass.) (1975).
CARTER R. Sous-catégorisation et régularités sélectionnelles, Communications, 40, 181-210 (1984).
CASSIRER E. Le langage et la construction du monde des objets, Journal de Psychologie normale et pathologique, 30, 18-44 (1933).
CASSIRER E. La philosophie des formes symboliques, t. I. Minuit, Paris, (1972).
CATACH N. Listes orthographiques de base. Paris, Nathan (1984).
CAVAZZA M. Analyse sémantique du langage naturel par construction de modèles, Thèse de lUniversité de Paris VII (1991).
CAVAZZA M. Modèles mentaux et sciences cognitives, in Ehrlich M.-F., Tardieu H., Cavazza M. (éds.), Les modèles mentaux : approche cognitive des représentations, Paris, Masson (1993).
CHAROLLES M. Le problème de la cohérence dans les études sur le discours, in Charolles M., et al. (éds.), Research in Text Connexity and Text Coherence, Buske, 1-65 Hambourg (1986).
CHOMSKY N. La connaissance du langage, Communications, 40, 7-24 (1984).
CHOMSKY N. Language and Problems of Knowledge. MIT Press, Cambridge (Mass.) (1988).
CLÉMENCEAU D. Automates et analyse morphologique. Thèse de Doctorat, Université Paris VII (1993).
COLLINS A. M., LOFTUS E. A Spreading-Activation Theory of Semantic Processing, Psychological Review, 82, 6, 407-428 (1975).
CORBIN D. Pour un composant lexical associatif et stratifié, DRLAV, 38, 63-92 (1988).
COSERIU E. Lexikalische Solidaritäten, Poetica, I, 115-129 .
COSERIU E. Die Geschichte der Sprachphilosophie von der Antike bir zur Gegenwart. Eine Ubersicht, Teil I : von der Antike bir Leibnitz, Tubinger Beitrage zur Linguistik, 11, 68-70 (1970).
COSERIU E. L'étude fonctionnelle du vocabulaire, Cahiers de lexicologie, 27, 30-51 (1976).
COSERIU E. Textlinguistik Eine Einführung. Tübingen, Narr. (1981).
COSERIU E., GECKELER H. Trends in Structural Semantics. Tübingen, Narr (1981).
COURTOIS B. Le DELAS, Rapport technique LADL, Université Paris VII (1991).
CRUSE D.A. Lexical Semantics. Cambridge : University Press, Cambridge (1986).
CULIOLI A. Sur quelques contradictions en linguistique, Communications, 20, pp. 83-91 (1973).
DE BEAUGRANDE R., DRESSLER W.U. Introduction to Text Linguistics. Longman, Londres (1981).
DENHIÈRE G., BAUDET S. Lecture, compréhension de texte et science cognitive. PUF, Paris (1992).
DENIS M. Propriétés figuratives et non figuratives dans l'analyse des concepts. L'année psychologique, 84, 327-345 (1984).
DENIS M., LE NY J.-F. Centering on figurative features in sentence comprehension of sentences describing scenes, Psychological Research, 48, 145-152 (1986).
DENNETT D. La compréhension artisanale, Lekton, II, 1, 27-52 (1992).
DESCLÉS J.-P. La construction formelle de la catégorie de l'aspect, in David J. & Martin R. (éds.), La notion d'aspect, Klincksieck, Paris, 195-213 (1980).
DESCLÉS J.-P. Réseaux sémantiques : la nature linguistique et logique des relateurs, Langages, 87, 55-78 (1987).
DI CESARE D. La semantica nella filosofia greca, Bulzoni, Rome (1980).
DOWTY D. Type Raising, Function Composition and Non Constituent Conjunction, in Oehrle R., Bach E., Wheeler D. (éds.), Categorial grammars and Natural language Structures, Dordrecht, Reidel (1988).
DREYFUS H. Intelligence Artificielle, mythes et limites. Flammarion, Paris [tr. de What Computers Cant Do, seconde édition revue et augmentée, New York, Harper et Row, 1979] (1984).
DUBOIS D. La compréhension de phrases : représentations sémantiques et processus. Thèse de doctorat d'Etat, Université Paris VIII (1986).
DUBOIS D. (éd.) Sémantique et cognition. Editions du Cnrs, Paris (1991).
DYER M. In Depth Understanding : A Computer Model of Integrated Processing for Narrative Comprehension, MIT Press, Cambridge (Mass.) (1983).
ECO U. Lector in fabula. Bompiani, Milan (1979).
ECO U. L'antiporfirio, in Vattimo G., Rovatti P.A. (éds.), Il pensiero debole, Feltrinelli, Milan (1983).
ECO U. Le Signe. Bruxelles, Labor (1988a).
ECO U. Sémiotique et philosophie du langage. Paris, Presses Universitaires de France (1988b).
FASS D. met*: A Method for Discriminating Metonymy and Metaphor by Computer. Computational Linguistics, 17, 1, 49-90 (1991).
FAUCONNIER G. Espaces mentaux. Éditions de Minuit, Paris (1984a).
FAUCONNIER G. Y a-t-il un niveau linguistique de représentation logique ? Communications, 40, 211-228 (1984b).
FILLMORE C. Frames semantics, in Linguistics in the Morning Calm, Hanshin, Séoul, 111-137 (1982).
FILLMORE C. Scenes-and-frames semantics, in Zampolli A. (éd.), Linguistic Structure Processing, Elsevier, North Holland, Amsterdam - New York, 55-81 (1979).
FINDLER N. (éd.) Associative Networks : Representation and Use of Knowledge by Computers. Academic Press, New York (1979).
FODOR J.A. The Language of Thought. Harvard University Press, Cambridge (Mass.) (1975).
FODOR J.A. The modularity of Mind. MIT Press, Cambridge (Mass.) [tr. fr. Paris, Éditions de Minuit, 1986] (1983).
FODOR J.A. Psychosemantics. Mit Press, Cambridge (Mass.) (1987).
FODOR J.A., GARRETT M., WALKER E., PARKES C. Against definitions, Cognition, 8, 263-367 (1980).
FORMIGARI L. Opérations mentales et théories sémantiques : le rôle du kantisme, HEL, 14, 2, 153-173 (1992).
FREGE G. Ecrits logiques et philosophiques. Seuil, Paris (1971).
FUCHS C. (éd.) Linguistique et traitements automatiques des langues. Hachette, Paris (1993).
GAMBARARA D. Alle fonti della filosofia del linguaggio : "Lingua" e "nomi" nella cultura greca arcaica. Bulzoni, Rome (1984).
GARDNER H. The Minds New Science : A History of the Cognitive Revolution. Basic Books, New York (1985).
GARNHAM A. Mental Models as Representations of Discourse and Text. Chichester, Ellis Horwood (1987).
GAZDAR G., KLEIN E., PULLUM G., SAG I. Generalized Phrase Structure Grammar. Harvard University Press, Cambridge (Mass.) (1985).
GEERAERTS D. Grammaire cognitive et sémantique lexicale, Communications, 53, 17-50 (1991).
GENETTE G. Figures III. Seuil, Paris (1972).
GEORGESCU I. The Hypernets Method for Representing Knowledge, in Bibel W. & Petkoff B. (éds.), Artificial Intelligence, methodology, systems, applications, North-Holland, Amsterdam-New York, 47-58 (1985).
GIRARDON J. La lancinante question de lhécatombe des espèces, Sciences et Avenir, 465, 28-35.
GIVÓN T. Prototypes : between Plato and Wittgenstein, in Craig C. (éd.), Noun Classes and Categorization, Benjamins, Amsterdam-Philadelphie (1986).
GODARD D. JAYEZ J. Towards a proper treatment of coercion phenomena. Proceedings of the European Chapter of the ACL (1993).
GREIMAS A.-J. Sémantique structurale. Larousse, Paris (1966).
GREIMAS A. J., RASTIER F. The Interaction of Semiotic Constraints. Yale French Studies, 41, 86-105 (1968).
GROSS M. Méthodes en syntaxe. Hermann, Paris (1975).
GROSS M. Grammaire transformationnelle du français: syntaxe du nom. Larousse, Paris (1977).
GROSS M. Grammaire transformationnelle du français : les expressions figées. ASSTRIL, Université Paris VII (1989).
GROSZ B. Focusing in dialog, Computational Linguistics, 79, 96-103 (1979).
GUILLAUME G. Leçons de linguistique 1956-1957, Presses de luniversité de Lille, Lille (1982).
GUSDORF G. Les sciences humaines et la pensée occidentale, t. I : De lhistoire des sciences à lhistoire de la pensée. Payot, Paris (1966).
HALLIDAY M.A.K. & HASAN R. Cohesion in English. Longman, Londres (1976).
HARNAD S. Category induction and representation, in Harnad S. (éd.), Categorical Perception, Cambridge University Press, Cambridge (1987).
HARRIS C. Connectionism and Cognitive Linguistics, Connection Science, 1-2, 7-33 (1990).
HAUGELAND J. Semantic engines : an introduction to mind design, in Haugeland J. (éd.), Mind Design, MIT Press, Cambridge (Mass.), 1-34 (1981).
HENLE P. (éd.) Language, Thought, and Culture. The University of Michigan Press, Ann Arbor (1958).
HEYCOCK C. Layers of predication and the syntax of the copula, Belgian Journal of Linguistics, 7, 95-123 (1992).
HJELMSLEV L. Essais linguistiques. Minuit, Paris (1971).
HOEPELMAN J., ROHRER C. Time, tense, and quantifiers, in Rohrer C. (éd.), Proceedings of the Stuttgart Conference on the Logic of Tense and Quantification, Niemeyer, Tübingen, 85-112 (1980).
JACKENDOFF R. Semantics and Cognition., MIT Press, Cambridge (Mass.) (1983).
JACKENDOFF R. Consciousness and the Computational Mind. MIT Press, Cambridge (Mass.) (1987a).
JACKENDOFF R. On beyond zebra : The relation of linguistic and visual information, Cognition, 26, 89-114 (1987b).
JACOB P. La syntaxe peut-elle être logique ? Communications, 40, 25-96 (1984).
JAYEZ J. L'inférence en langue naturelle. Paris, Hermès (1988).
JOHNSON M. The Body in the Mind. Chicago University Press, Chicago (1987).
JOHNSON M. Philosophical implications of cognitive semantics, Cognitive Linguistics, 3-4, 345-366 (1992).
JOHNSON-LAIRD P.N. Mental Models, Cambridge University Press, Cambridge (1983).
JOHNSON-LAIRD P.N. La représentation mentale de la signification, RISS, 115, 53-69 (1988).
JOLY A., STÉFANINI J. (éds.) La grammaire générale des Modistes aux Idéologues. Presses Universitaires de Lille, Lille (1977).
JOSHI A., VIJAY-SHANKER K., WEIR D. The convergence of mildly context-sensitive grammar formalisms, in Sells P. et al. (éds.), Foundational issues in Natural Language Processing, MIT Press, Cambridge (1991).
JUCQUOIS G. Aspects anthropologiques de quelques notions philologiques, in François F. (éd.), Le texte parle, CILL, Louvain, 183-248 (1986).
KALINOWSKI G. Sémiotique et philosophie. Hadès-Benjamins Paris-Amsterdam (1985).
KAPLAN R., BRESNAN J. LFG : a formal system for grammatical representation, in Bresnan J. (éd.), The Mental Representation of grammatical relations, MIT Press, Cambridge (1982).
KATZ J.J. Semantic Theory. New York, Harper & Row (1972).
KATZ J.J. Chomsky on meaning, Language, 56, 1-42 (1980).
KATZ J.J., FODOR J.A. Structure of a semantic theory, Language, 38, 170-210 (1963).
KINTSCH W. The Representation of Meaning in Memory, Erlbaum, Hillsdale (N. J.) (1974).
KINTSCH W. Knowledge in discourse comprehension, in Denhière G. & Rossi J.-P. (éds.), Text and Text Processing, North Holland, Amsterdam New York, 107-154 (1991).
KLEIBER G. La sémantique du prototype. PUF, Paris (1990).
KRIPKE S. La logique des noms propres. Minuit, Paris (1982).
KUHN T.H. The structure of Scientific Revolutions. University of Chicago Press, Chicago (1970).
LADRIÈRE J. Limites de la formalisation, in Piaget J. (éd.), Logique et connaissance scientifique, Gallimard, 312-333 (1967).
LAKOFF G. Some Remarks on A.I. and Linguistics, Cognitive Science, 2, 267-275 (1978).
LAKOFF G. Women, Fire, and Dangerous Things : What Categories Reveal About the Mind, University of Chicago Press, Chicago (Ill.) (1987).
LAKOFF G. The invariance hypothesis : is abstract reason based on image-schemas ? Cognitive Linguistics, I, 1, 39-74 (1990).
LANDAU M.-C. Solving ambiguities in the semantic representations of texts. Proceedings of COLING'90 conference, Helsinki (1990).
LANGACKER R.W. An Introduction to Cognitive Grammar, Cognitive Science, X, 1, 1-40 (1986).
LANGACKER R.W. Foundations of Cognitive GrammarTheoretical Prerequisites, vol. 1, Stanford University Press Stanford (Cal.) (1987).
LANGACKER R.W. Compte rendu de Lakoff 1987, Language, 64, 2, 383-395 (1988).
LANGACKER R.W. Foundations of Cognitive Grammar Descriptive Applications (vol. 2) Stanford University Press Stanford (1991a).
LANGACKER R.W. Noms et verbes, Communications, 53, 103-154 (1991b).
LE NY J.-F La sémantique psychologique. Presses Universitaires de France, Paris (1979).
LEACH E. Lunité de lhomme et autres essais. Gallimard, Paris (1980).
LINSKY L. Le problème de la référence. Seuil, Paris (1974).
LONGACRE R. E. The Grammar of Discourse, New York et Londres, Plenum Press (1983).
LOTMAN I. Different Cultures, Different Codes, Times Literary Supplement, 3736, 1213-1215 (1973).
LUZZATI D. Incidence de la machine sur le comportement langagier, DRLAV, 36-37, 183-197 (1987).
LYONS J. Eléments de sémantique. Larousse, Paris (1978).
MALCOLM N. Nothing is Hidden. Blackwell, Oxford (1986).
MARTIN E. L'exploration textuelle assistée par ordinateur : l'interrogation thématique. Colòquio de lexicologia e lexicografia, Universidade Nova de Lisboa (1990).
MARTIN R. Pour une logique du sens. PUF, Paris (1983).
MARTINET A. Eléments de linguistique générale. A. Colin, Paris (1960).
MARTINET A. Linguistique et sémiologie fonctionnelle, Publications de l'Ecole supérieure des langues étrangères, n° 2850/5, 77, Istamboul (1981).
MATTON S. De Socrate à Nietzsche. In : Le Courage, Autrement (série Morales), 6, 32-51 (1992).
MAUREL D. Préanalyse des adverbes de date du français, TA Informations, 32, 2, Klincksieck (1991).
MCCLELLAND J., KAWATOMO A. Mechanisms of sentence processing : Assigning roles to constituents, in McClelland J., Rumelhart D. (éds.) Parallel Distributed Processing, MIT Press, 2 vol., Cambridge (Mass.) (1986).
MCCLELLAND J., RUMELHART D. (éds.) Parallel Distributed Processing, MIT Press, 2 vol., Cambridge (Mass.) (1986).
MECACCI L. Le cerveau et la culture, Le Débat, 47, 184-192 (1987).
MEHLER J., DUPOUX E. De la psychologie à la science cognitive, Le débat, 47, 65-87 (1987).
MELCHUK I, IORDANSKAJA L., ARBATCHEWSKY-JUMARIE N. Un nouveau type de dictionnaire : le dictionnaire explicatif et combinatoire du français contemporain, Cahiers de lexicologie, 38-1, 3-34.(1981)
MEL'CHUK I. Dependency Syntax: Theory and Practice. SUNY Press, Albany (NY) (1988).
MEYER M. Découverte et justification en science. Klincksieck, Paris (1979).
MILLER G.A. & JOHNSON-LAIRD P.N. Language and Perception. Cambrige University Press, Cambridge (1976).
MILLER P., TORRIS T. Formalismes syntaxiques pour le traitement automatique du langage naturel. Hermès, Paris (1990).
MINSKY M. A Framework for Representing Knowledge, in Winston P. (éd.), The Psychology of Computer Vision, McGraw-Hill, New-York, 99-128 (1975).
MONTAGUE R. Formal Philosophy. Yale University Press, New Haven (1974).
MOREL M.-A. (dir.) Dialogue homme-machine : analyse linguistique d'un corpus. Publications de la Sorbonne nouvelle, Paris (1988).
MORRIS C. Writings on the general theory of signs. Mouton, La Haye (1971).
MORRIS J., HIRST G. Lexical Cohesion Computed by Thesaural Relations as an Indicator of the Structure of a Text. Computational Linguistics, 17, 1 (1991).
NEF F. La description de la deixis temporelle du français moderne. Université de Paris IV, thèse de Doctorat d'Etat (1983).
NORMAN D. Cognition in the head, or in the world ? Cognitive Science, 17, 1, 1-7 (1993).
OGDEN C.K., RICHARDS I.A. The Meaning of Meaning. Routledge and Kegan Paul, Londres (1923).
OUELLET P. Lingua ex machina : le statut de la « langue » dans les modèles cognitivistes, Semiotica, 77, 1/3, 201-223 (1989).
PERDRIZET F. Les structures morphologiques du vocabulaire de la bonneterie, Cahiers de lexicologie, XII, 1, 72-85 (1983).
PERFETTI C.A., GOLDMAN S.R. Thematization and sentence retrieval, Journal of Verbal Learning and Verbal Behaviour, 13, 70-79 (1974).
PERRET J. Du texte à lauteur du texte, in Barbotin E. (éd.) BARBOTIN E.(éd.) Quest-ce quun texte ? Eléments pour une herméneutique. Corti, Paris, pp. 11-40 (1975).
PIOTROWSKI D. Pour linformatisation du Trésor de la langue française rapport préalable, Nancy, Inalf, rapport interne (1993).
POST M. Scenes-and-Frames Semantics as a Neo-lexical Field Theory, in Hüllen W., Schulze R. (éds.), Understanding the Lexicon, Niemeyer, Tübingen, 36-45 (1988).
POTTIER B. Systématique des éléments de relation. Klincksieck, Paris (1962).
POTTIER B. Linguistique générale Théorie et description. Klincksieck, Paris (1974).
POTTIER B. Théorie et analyse en linguistique, Hachette, Paris (1987).
POTTIER B. Sémantique générale. PUF, Paris (1992).
PUSTEJOVSKY J. The Generative Lexicon. Computational Linguistics, 17, 4 (1991).
PUTNAM H. The meaning of «meaning», in Gunderson K. (éd.), Language, Mind, and Knowledge, Minnesota Studies in the Philosophy of Science, vol. VIII, University of Minnesota Press, Minneapolis, 131-193 (1975).
PUTNAM H. Representation and Reality. MIT Press, Cambridge (Mass.) (1988).
PUTNAM H. Définitions. LÉclat , Paris (1992).
PYLYSHYN Z. Computation and Cognition, MIT Press, Cambridge (Mass.) (1984).
QUILLIAN R. Semantic Memory, in Minsky M. (éd.), Semantic Information Processing. MIT Press, Cambridge (Mass.), 227-270 (1968).
RASTIER F. Les niveaux d'ambiguïté des structures narratives, Semiotica, III, 4, 289-342 (1971).
RASTIER F. Essais de sémiotique discursive. Mame, Paris (1973).
RASTIER F. Microsémantique et syntaxe, L'information grammaticale, 37, 8-13 (1985).
RASTIER F. Sémantique interprétative. PUF, Paris (1987 a).
RASTIER F. Représentations du contenu lexical et formalismes de l'Intelligence Artificielle. Langages, 67 (1987 b).
RASTIER F. Sur la sémantique des réseaux, Quaderni di Semantica, 15, 109-124 (1987 c).
RASTIER F. Problématiques sémantiques, in Bénézech J.-P., et alii (éds.), Hommage à Bernard Pottier, Paris, Klincksieck, tome II, 671-686 (1988)
RASTIER F. La sémantique descriptive unifiée, in Modèles sémantiques pour les traitements automatiques des langues naturelles, Nanterre, EC2 (1989a).
RASTIER F. Sens et textualité. Hachette, Paris (1989 b).
RASTIER F. La triade sémiotique, le trivium et la sémantique linguistique. Nouveaux actes sémiotiques, 9 (1990 a).
RASTIER F. Signification et référence du mot, Modèles linguistiques, 24, 61-82 (1990 b).
RASTIER F. L'analyse linguistique des textes d'experts, Génie logiciel, 23, pp.16-23 (1991a)
RASTIER F. Sémantique et recherches cognitives. PUF, Paris (1991b).
RASTIER F. Tropes et sémantique linguistique, Langue française , 101 (1994).
RÉCANATI F. Présentation, Langages, 67, pp. 5-6 (1982).
REGOCZEI S., HIRST G. The meaning triangle as a tool for the acquisition of abstract, conceptual knowledge, International Journal of Man-Machine Studies, 33, 505-520 (1990).
REY A. Théories du signe et du sens, Klincksieck, 2 vol., Paris (1973-1976).
REY-DEBOVE J. Le sens de la tautologie, Le français moderne, 4, 318-332 (1978).
RICUR P. Du texte à laction. Essais dherméneutique II, Paris, Seuil (1986).
RORTY R. Texts and Lumps, New Literary History, XVII, 1 (1985).
ROSCH E. Principles of categorization, in Rosch E. et Lloyd B. (éds.), Cognition and Categorization, Hillsdale, Erlbaum, 27-48 (1978).
SABAH G. LI.A. et le langage, 2 vol. Paris, Hermès (1988-1989).
SAINT-DIZIER P. Constraint Propagation Techniques for Lexical Semantics Descriptions, in Saint-Dizier P., Viégas E. (éds.), 2nd Seminar on Computational Lexical Semantics, IRIT, Toulouse (1992).
SALANSKIS J.-M. Continu, cognition, linguistique, ms., 28 p. (1992a).
SALANSKIS J.-M. Lesprit et la pensée, ms., 21 p. (1992b).
SALANSKIS J.-M. (éd.) Philosophies et sciences cognitives, Intellectica, 17 (1993).
SAUSSURE F. de Cours de linguistique générale, Payot , Paris (1972 [1916]).
SCHABES Y., ABEILLÉ A., JOSHI A. Parsing strategies with lexicalized grammars : Tree adjoining grammars, Actes 12° COLING, Budapest, vol. 2, 578-583 (1988).
SCHANK R. Conceptual Information Processing, Amsterdam, North Holland (1975).
SCHANK R., ABELSON, R. Scripts, Plans, Goals and Understanding, Erlbaum, Hillsdale (N.J.) (1977).
SCHANK R.C. Conceptual Dependency : A Theory of Natural Language Understanding, Cognitive Psychology, 3, 4, 552-630 (1977).
SERBAT G. Cas et fonctions. PUF, Paris (1981).
SHIEBER S. An introduction to unification-based theories of grammar, CSLI, University of Chicago Press (1986) [Trad. fr. in Miller P. Torris T. (1990)].
SHIEBER S., SCHABES Y. Synchronous Tree Adjoining grammars, Actes 13° COLING, Helsinki, vol. 3, 253-260 (1990).
SLAKTA D. Grammaire de texte : synonymie et paraphrase, in Fuchs C. (éd.), Aspects de lambiguïté et de la paraphrase dans les langues naturelles. Peter Lang, Berne (1985).
SMOLENSKY P. The Proper Treatment of Connectionnism, Behavioral and Brain Sciences, 11, 1, 1-74 (1988).
SMOLENSKY P., LEGENDRE G., MIYATA Y. Harmonic Grammar - A formal multi-level connectionnist theory of linguistic well-formedness : Theoretical foundations, ICS Technical Report, 90-5 (1990).
SMOLENSKY P., LEGENDRE G., MIYATA Y. Principles for an Integrated Connexionnist/ Symbolic Theory of Higher Cognition, University of Colorado at Boulder, Report CU-CS-600-92 (1992).
SOWA J. Conceptual structures, Information processing in mind and machine. Addison Wesley, New York (1984).
SPERBER D., WILSON D. La pertinence, Editions de Minuit, Paris [trad. fr. de Relevance, Blackwell, Londres, 1986] (1989).
STEINTHAL H. Grammatik, Logik und Psychologie und ihr Verhältnis zueinander. Georg Holms Verlag, Hildesheim -New York (1968 [1855]).
SZABOLCSI A. Compositionality in focus, Folia Linguistica, XV, 1-2, 141-161 (1981).
TALMY L. Force Dynamics in Language and Cognition, Cognitive Science, 12, 49-100 (1988).
TALMY L. (sans date) The Relation of Grammar to Cognition, University of California, Berkeley, Preprint (s.d.)
TAYLOR J.R. Linguistic Categorization. Oxford, Oxford University Press (1989).
TESNIÈRE L. Éléments de syntaxe structurale. Klincksieck, Paris (1959).
THAYSE A. et al. Approche logique de l'intelligence artificielle. Dunod Informatique, Paris (1990).
THOMAS D'AQUIN Somme théologique, Paris-Tournai, Editions du Cerf - Desclée de Brouwer (1968 ---).
TODOROV T. Grammaire du Décaméron. Mouton, La Haye (1970).
TOGEBY K. Structure immanente de la langue française, T.C.LC., V, Nordisk Sprog- og Kulturforlag, Copenhague (1951).
TOMITA M. Linguistic sentences and real sentences, Actes 12ème COLING, vol. 2, Budapest. p. 453 (1988).
ULLMANN S. The Principles of Semantics. Blackwell, Oxford (1957).
VANDELOISE C. Lespace en français, Seuil, Paris (1986).
VANDELOISE C. Autonomie du langage et cognition, Communications, 53, 69-102 (1991).
VIGNAUX G. Les sciences cognitives : une introduction, La Découverte, Paris (1992).
VAN DIJK T. Text and Context. Longman, Londres (1977).
VAN DIJK T. Le texte : structures et fonctions, in Kibédi Varga A. (éd.), Théorie de la littérature, Picard, Paris (1981).
VAN DIJK T. Texte, in Beaumarchais J.-P. de (éd.), Dictionnaire des littératures de langue française, Bordas, Paris (1984).
VAN DIJK T., KINTSCH W. Strategies of Discourse Comprehension. Academic Press, New York (1983).
VIJAY-SHANKER K. Using descriptions of trees in Tree Adjoining Grammars, Computational Linguistics, 18, 4 (1992).
VIJAY-SHANKER K., JOSHI A. Feature-based Tree Adjoining Grammars, Actes 12ème COLING, Budapest, vol. 2, 714-719 (1988).
VISETTI Y.-M. Modèles connexionnistes et représentations structurées, Intellectica, 9-10, 167-212 (1990).
VISETTI Y.-M. Des systèmes experts aux systèmes à bases de connaissances : à la recherche d'un nouveau schéma régulateur, Intellectica, 12 (1991).
VISETTI Y.-M. Intelligence artificielle et systèmes experts, in Chambat P. et Lévy P. (éds.), Les nouveaux outils du savoir, Editions Descartes, Paris, 63-86 (1992).
VOGEL C. Génie cognitif, Masson, Paris (1988a).
VOGEL C. Les systèmes experts dans le domaine spatial : l'innovation experte. Colloque technospace, Bordeaux, n. p. (1988b).
VYGOTSKY L. S. Thought and Language. MIT Press Cambridge (Mass.) (1962 [1934]).
WEINRICH H. Grammaire textuelle du français, Paris, Didier (1989 [1982])
WEIZENBAUM J. Puissance de lordinateur et raison de lhomme. Les Editions dInformatique, Boulogne (1981).
WHORF B. L. Language, Thought, and Reality. MIT Press, Cambridge (Mass.) (1956).
WILKS Y. Philosophy of language, in Charniak E., Wilks Y. (éds.), Computational Semantics, North Holland, Amsterdam New York, 205-234 (1976).
WILKS Y. Good and bad arguments for semantic primitives, Communication and Cognition, 10, 181-221 (1977).
WILKS Y. Frames, Semantics and Novelty, in Metzing D. (éd.), Frame Conceptions and Text Understanding, Berlin - De Gruyter, New York, 134-163 (1980).
WILKS Y. Form and content in semantics, in Rosner M., Johnson R. (éds.), Computational Linguistics and Formal Semantics, Cambridge, Cambridge University Press (1992).
WINOGRAD T. Towards a procedural Understanding of Semantics, Revue internationale de philosophie, t. 30, n° 117-118, 261-303 (1976).
WINOGRAD T. Formalisms for knowledge, in Johnson-Laird P.N. & Wason P.C. (éds.), Thinking , Cambridge, Cambridge University Press, pp. 62-74 (1977).
WINOGRAD T. Language as a Cognitive Process, Vol. I, Syntax., Addison Wesley, New York (1983).
WINOGRAD T. Heidegger et la conception des systèmes informatiques, Intellectica, 17, 51-78. (1993).
WINOGRAD T., FLORES F. Understanding Computers and Cognition, Ablex, Norwood (N. J.) (1986).
WOODS W. Procedural semantics as a theory of meaning, in Webber B., Joshi A., Sag I., (éds.), Elements of Discourse Understanding, Cambridge University Press, Cambridge (Mass.),301-334 (1981).
ZADROZNY W. Logical Dimensions of Some Graph Formalisms, in Sowa J. (éd.), Principles of Semantic Networks, Morgan Kaufmann, San Mateo (1991).
Vous pouvez adresser vos commentaires et suggestions à : Lpe2@ext.jussieu.fr
|
©
Référence
bibliographique : RASTIER, François. La microsémantique. Texto ! [en ligne], juin
2005, vol. X, n°2. Disponible sur :
<http://www.revue-texto.net/Inedits/Rastier/Rastier_Microsemantique.html>.
(Consultée le ...). |