Victor Rosenthal : Approche microgťnťtique du langage et de la perception
--- page 14 ---
On commence par l'observation des patients aphasiques dits agrammatiques dont le langage spontanť est dťpourvu des morphŤmes fonctionnels (articles, auxiliaires, pronoms, conjonctions, prťpositions, terminaisons des verbes, etc..), de sorte qu'il apparaÓt comme un langage tťlťgraphique [32] . Au cours des annťes 1970, de nombreux chercheurs se sont penchťs sur la production et la comprťhension du langage de ces patients et ont pour la plupart constatť un parallťlisme dans le type de dťficits affectant la production et la comprťhension : les agrammatiques tendaient ŗ omettre les morphŤmes fonctionnels en production et ŗ se conduire en comprťhension comme s'ils ignoraient leur prťsence dans la phrase (Caramazza & Zurif, 1976; Heilman & Scholes, 1976; Kremin & Goldblum, 1975; Rosenthal & Bisiacchi, 1982; von Stockert, 1972; Zurif, Caramazza, & Myerson, 1972; Zurif, Green, Caramazza, & Goodenough, 1976) . Ce comportement se traduisait par des erreurs [33] de comprťhension de phrases, notamment lorsque ces morphŤmes fonctionnels ťtaient critiques pour l'interprťtation.
L'opinion dominante autour de 1980 ťtait que ces patients avaient perdu la morphologie fonctionnelle et que leur syntaxe ťtait gravement compromise (Berndt & Caramazza, 1980; Schwartz, Saffran, & Marin, 1980) . Le seul ťlťment discordant dans ce concert ťtait l'observation faite par Andreewsky et Seron (1975) que, compte tenu de l'ambiguÔtť morpho-syntaxique omniprťsente dans le langage (par exemple son , ton , car , as , sous , or sont tous, selon le contexte, des mots fonctionnels ou des noms), il est impossible de īlaisser de cŰtť' les mots fonctionnels de la phrase sans les avoir prťalablement identifiťs comme tels, ce qui implique le traitement de tous les mots de la phrase et des rapports syntaxiques locaux qu'ils entretiennent ŗ l'intťrieur de celle-ci. Andreewsky et Seron ont ťtudiť la comprťhension en lecture d'un patient agrammatique et montrť qu'il lisait ou ne lisait pas ŗ haute voix un mot donnť ( car ) selon que celui-ci ťtait, dans le contexte, un nom ou une conjonction (par exemple Le car ralentit car le moteur chauffe ), ce qui confirmait ainsi leur analyse (voir aussi Linebarger, Schwartz, & Saffran, 1983, qui ont trouvť que les patients agrammatiques sont capables d'ťvaluer la grammaticalitť d'une phrase sans Ítre pour autant en mesure de l'interprťter correctement) . ParallŤlement, les chercheurs en linguistique automatique ťtaient eux aussi confrontťs, quoique d'une faÁon diffťrente, au problŤme de l'ambiguÔtť morpho-syntaxique des phrases (voir il lit le livre vs. il livre le lit ; il montre la rŤgle vs. il rŤgle la montre ) qui rendait trŤs difficile le traitement automatique du langage. Avec ces travaux, la dťsambiguation morpho-syntaxique apparaissait comme le prťalable ŗ tout traitement linguistique utile. Nous avons suggťrť avec Evelyne Andreewsky qu'une dťsambiguation morpho-syntaxique revient en fait ŗ repťrer les domaines de connaissance relatifs ŗ l'ťnoncť traitť donc ŗ induire l'ťtape gťnťrale de l'interprťtation (Andreewsky & Rosenthal, 1986; Andreewsky, Rosenthal, & Bourcier, 1987) .
A partir de ces premiers constats thťoriques, nous avons procťdť avec Martine Dťsi ŗ une ťtude dťtaillťe de la lecture de trois patients agrammatiques. Il s'agissait de l'expťrience suivante : on prťsente au patient des phrases comportant des homographes non-homophones dont la prononciation change en fonction de la classe grammaticale [34] . On peut ainsi contraster la lecture ŗ haute voix (et surtout la prononciation des mots tests) de phrases comportant deux acceptions lexico-grammaticales du mÍme morphŤme, comme dans :
Tu joue
ton
as
Ė Tu
as
ton jouet
Je
vis
sur un nuage- Il prend
une
vis
.
Pour rendre cette t‚che plus difficile nous avons mÍme introduit des biais sťmantiques, comme dans les exemples suivants :
Les
religieuses
couvent
la grippe- Les poules
du
couvent
ne pondent plus
rien
Nos
rations
sont dans le train- Encore un
peu et nous
rations
le repas.
Bien que les patients ťprouvaient des difficultťs ŗ lire tous les mots de ces phrases, qu'ils tendaient ŗ omettre un certain nombre de mots fonctionnels ou ŗ produire des paralexies (par ex. lire ĎVivre dans les nuages' ŗ la place de 'Je vis sur un nuage'), dans tous les cas leur lecture (i.e. leur prononciation) manifestait une dťsambiguation lexicale correcte- et par cela-mÍme une dťtermination de la classe syntaxique- des homographes tests utilisťs (cf. Dťsi, Rosenthal et Andreewsky, 1986, Rosenthal & Goldblum, 1989) . On notera que seule la capacitť de traiter les relations morpho-syntaxiques locales permet de savoir que 'rations' dans 'nos rations sont...' correspond ŗ un nom prononcť [ rasjű ] tandis que 'rations' dans 'nous rations le...' ne peut correspondre qu'ŗ une forme de verbe conjuguť que l'on prononce [ ratjű ]. On remarquera ťgalement que le traitement de ces relations morpho-syntaxiques locales reposait dans l'exemple citť sur le traitement des mots fonctionnels qui prťcŤdent et suivent la cible 'rations'. DŤs lors comment pouvait-on accepter l'idťe que les agrammatiques aient perdu la morphologie fonctionnelle et que leur syntaxe ťtait gravement compromise, alors qu'en mÍme temps on pouvait constater une telle capacitť ŗ rťaliser la catťgorisation lexicale sur la base des relations morpho-syntaxiques, et cela en dťpit du petit piŤge sťmantique (induit par le couplage lexical religieuses Ė couvent, rations- train, etc.)? Il faut souligner que ces patients tombaient par ailleurs dans tous les piŤges habituels que les neurolinguistes tendent aux patients agrammatiques; leur performance ťtait alťatoire quand il s'agissait d'apparier des images ŗ des phrases de type : 'le carrť est au dessus du cercle' ou 'le chat que le chien poursuit est noir', ou ils choisissaient systťmatiquement la structure thťmatique usuelle en dťsignant comme actants, pour des phrases de type : 'la petite fille donne ŗ manger ŗ sa maman' ou 'le patient examine le mťdecin', respectivement, la maman et le mťdecin.
Dans cette mÍme ťtude nous avons comparť le comportement de ces patients et de sujets normaux dans une ťpreuve de dťtection de lettres au cours de la lecture silencieuse d'un texte. Dans ce type d'ťpreuve, Healy et ses collaborateurs (Drewnowski & Healy, 1977; Healy, 1976) avaient dťjŗ montrť l'existence d'un effet de la classe syntaxique. Lorsqu'on demande aux sujets de lire un textetout en cochant toutes les occurrences d'une lettre donnťe, ils īoublient' de cocher (c'est-ŗ-dire ne dťtectent pas) la lettre-cible beaucoup plus souvent dans les mots fonctionnels que dans les mots pleins, et cela mÍme lorsqu'il s'agit de la mÍme forme lexicale (par exemple les deux occurrences de 'son', 'ton', cf. Greenberg & Koriat, 1991) . Nous avons observť le mÍme phťnomŤne avec nos patients agrammatiques qui par ailleurs ne diffťraient pas qualitativement des sujets tťmoins. Lorsque nous avons prťsentť aux sujets les mots issus du mÍme texte mais en dťsordre (scrambled text), l'effet de la classe syntaxique a disparu : les agrammatiques, tout comme les sujets tťmoins, faisaient autant d'omissions dans les mots fonctionnels que dans les mots pleins. Cette expťrience montrait de toute ťvidence que les agrammatiques n'avaient perdu ni la syntaxe ni la morphologie fonctionnelle et qu'ils procťdaient ŗ des traitements morpho-syntaxiques et syntaxiques complexes dont la nature reste ŗ dťterminer.
D'autres travaux, notamment ceux de Grodzinsky (1984) montraient que la thŤse de la perte de la morphologie fonctionnelle est incompatible avec les observations de l'agrammatisme dans une langue comme le russe dont la morphologie est plus riche que celle du franÁais ou de l'anglais, ou qu'elle est totalement impossible dans le cas de l'hťbreu oý l'absence de la morphologie fonctionnelle conduirait ŗ des non-mots.
En analysant le polonais, dont la grammaire repose essentiellement sur la morphologie flexionnelle, j'ai rťalisť que les transformations flexionnelles crťent dans une telle langue (et cela vaut pour toutes les langues ŗ dťclinaison) d'innombrables accidents homonymiques, de sorte que l'identitť lexicale de tout mot d'une phrase est potentiellement ambiguő. Les exemples suivants illustrent ce propos. Ainsi tous les mots dans la phrase :
Nie damy ci grabi (Nous ne te donnerons pas de r‚teau)
sont ambigus dans la mesure oý les mÍmes formes correspondent ŗ d'autres mots (oý leurs formes dťclinťes) du polonais. Ainsi, les deux premiers mots 'nie' (adverbe de nťgation) et 'damy' (premiŤre personne du pluriel du verbe 'donner') peuvent se retrouver dans :
Te damy czekaja na nie (Ces dames les attendent)
oý ils deviennent, respectivement, un nom au pluriel (dames) et un pronom objet fťminin (les). Les autres mots du premier exemple vont, dans les exemples suivants, ťgalement changer d'identitť lexicale et de classe syntaxique :
Ci
panowie byli
pierwsi
(Ces
messieurs ont ťtť les premiers)
Robin
Hood
grabi
bogatych
(Robin des Bois
dťvalise
les riches)
le pronom datif 'ci' (te) devenant un pronom indicatif alors que le nom gťnitif 'grabi' (r‚teau) devenant un verbe (dťvaliser). Ces exemples n'ont pas pour but d'indiquer une curiositť spťcifique au polonais (cela vaut ťgalement pour le russe, le tchŤque,.. et pour toute autre langue dans laquelle les relations syntaxiques sont encodťes par les flexions) mais de montrer l'ambiguÔtť gťnťrale des formes lexicales. Cette ambiguÔtť est trŤs frťquente en franÁais ( il lit le livre vs. il livre le lit ; il montre la rŤgle vs. il rŤgle la montre , etc.), et elle est particuliŤrement sensible quand l'on considŤre le problŤme de la segmentation de la parole continue en mots. Ainsi :
J'ai tout fini
peut Ítre segmentť par un systŤme dťpourvu de toute analyse morpho-syntaxique
Jette ou fi n'y, J'ai toux fit nid, Geai toue finis, Jette ou fie ni,
et l'on peut multiplier les exemples ŗ l'infini.
Ces travaux et ces considťrations ont pavť la voie ŗ la thťorie de l'identification lexicale et de la structuration rťfťrentielle (Rosenthal & Goldblum, 1989) . La dťtermination de l'identitť lexicale de tous les mots des ťnoncťs constitue le prťalable linguistique ŗ tout autre traitement utile. Un individu ne pourrait rien comprendre s'il n'ťtait pas capable de mener ŗ bien la dťtermination de l'identitť lexicale. Cette dťtermination est accomplie par un ensemble de procťdures de dťsambiguation morpho-syntaxique basťes sur des interdťpendances structurelles locales et l'inventaire morphťmique de la langue. Elle n'est pas suffisante, et de loin, pour l'interprťtation correcte du langage mais suffisante pour induire une interprťtation de type agrammatique (Baum, 1989; Schwartz, Linebarger, & Saffran, 1987) . Pour se conduire en agrammatique le patient doit au minimum Ítre capable de la dťsambiguation morpho-syntaxique. Les lois d'interdťpendance structurelle locale diffŤrent d'une langue ŗ l'autre en fonction notamment de leurs propriťtťs morphologiques, mais le principe de ces lois reste toujours le mÍme : la dťsambiguation morpho-syntaxique doit conduire ŗ l'identification d'un item comme un mot m k de l'inventaire morphťmique de la langue, ce qui revient aussi ŗ dťterminer sa classe grammaticale.
A partir de lŗ nous avons fait des prťdictions concernant le comportement des agrammatiques dans un certain nombre de langues et ťvaluť expťrimentalement l'une d'entre elles, relative au franÁais. Selon les donnťes disponibles de la littťrature aphasiologique les agrammatiques ťtaient strictement incapables de faire un quelconque usage des articles. Or, en franÁais, le genre de l'article constitue parfois le seul moyen pour dťterminer l'identitť du nom ( le moule vs. la moule , le vase vs. la vase , le poÍle vs. la poÍle , etc.). Suivant notre thťorie les agrammatiques devaient Ítre capables d'identifier correctement de tels noms en fonction du genre de l'article. Cette prťdiction a ťtť corroborťe expťrimentalement, d'abord par Rosenthal et Goldblum (1989) , puis, dans deux ťtudes conduites au Quťbec, par Jarema et Kehayia (1992) et Jarema et Friederici (1994) . L'intťrÍt de ces deux derniŤres ťtudes rťside, d'une part dans la confirmation expťrimentale de certaines prťdictions de la Thťorie de l'Identification Lexicale par des chercheurs travaillant dans un cadre diffťrent du notre (Jarema et Friederici, 1994) et, d'autre part, dans l'extension de nos rťsultats concernant la comprťhension d'articles par les patients agrammatiques ŗ la production d'articles par ces patients (Jarema et Kehayia, 1992).
La thťorie prťsentťe dans Rosenthal et Goldblum (1989) marque trŤs nettement la distinction entre identification lexicale (rťalisťe au moyen de la dťsambiguation morpho-syntaxique) et structuration rťfťrentielle . Traditionnellement, la linguistique dťcomposait la grammaire en deux parties autonomes, chacune constituant un tout : la morphologie (concernant la forme des mots) et la syntaxe (concernant la structure syntagmatique des phrases). Or cette division du travail paraÓt fonctionnellement et tťlťologiquement incorrecte; d'une part, la morphologie et certains ťlťments de la syntaxe locale sont interdťpendants (cf. de Bleser & Bayer, 1988) , d'autre part, et surtout, l'identification lexicale et la dťtermination de la structure rťfťrentielle ne servent nullement les mÍmes objectifs et sont rťalisťes avec des moyens trŤs diffťrents.
Un exemple reprenant le problŤme de l'emploi des articles en franÁais permet d'illustrer ce propos. Selon la thťorie de l'identification lexicale et de la structuration rťfťrentielle, l'analyse du genre de l'article fait partie des moyens mis en ķuvre par l'identification lexicale (car elle est souvent indispensable pour dťterminer l'identitť lexicale du nom), alors que la dťtermination du nombre de l'article relŤve de l'analyse rťfťrentielle (car elle sert ŗ coindexer diffťrentes entitťs). Ainsi, les patients agrammatiques doivent pouvoir identifier un nom sur la base du genre de l'article qui le prťcŤde (cf. ci-dessus) tout en se montrant incapables de se servir de l'indice rťfťrentiel que fournit le nombre de l'article dans leur interprťtation des ťnoncťs. Et en effet, une patiente agrammatique a montrť cette dissociation dans une ťpreuve de jugement de grammaticalitť de phrases. Alors que cette patiente n'ťprouvait aucun mal ŗ repťrer les usages erronťs du genre, elle acceptait invariablement comme correctes des phrases de type : * Le mille-pattes marchent vite , c'est-ŗ-dire des phrases oý le jugement de grammaticalitť reposait d'une faÁon critique sur la capacitť d'analyser le nombre de l'article.
--- page 18 ---
6. Structuration
rťfťrentielle
![]()
Par structure rťfťrentielle il faut entendre la structure implicite de l'ensemble des relations internes [35] ŗ l'ťnoncť qui forment une sorte de trame permettant d'orienter et de structurer l'interprťtation. Le concept de structure rťfťrentielle prťsuppose donc que tout ťnoncť comporte des traces des intentions thťmatiques du locuteur (au plan de l'interprťtation conventionnelle dont il a ťtť question plus haut) et que l'analyse de ces traces fournit un schťma au processus interprťtatif. L'identification lexicale rend possible toute une sťrie de processus liťs ŗ l'interprťtation mais ne fournit ŗ cette derniŤre aucune structure. Toutefois, dŤs que les mots de la phrase sont connus, les anticipations thťmatiques prennent tout leur relief, et l'on peut īutiliser' les connaissances normalement associťes ŗ la cooccurrence de ces mots ainsi que la connaissance des situations dans lesquelles cette combinaison est susceptible d'avoir lieu. Tout ceci est loin d'Ítre nťgligeable mais nous n'irions pas trŤs loin en interprťtant les ťnoncťs exclusivement sur la base de ce que nous attendons ou savons dťjŗ et non pas en fonction de ce qui a ťtť dit. L'interprťtation conventionnelle implique de toute ťvidence une transformation des attentes et une actualisation, ad hoc , des savoirs en fonction des indices rťfťrentiels des ťnoncťs (ces traces dont l'analyse fournit un schťma hic et nunc au processus de l'interprťtation).
La dťfinition des īprocessus [36] ' rťfťrentiels constitue donc un problŤme incontournable pour modťliser la comprťhension du langage. Il s'agit de processus au pluriel car la structure rťfťrentielle est comme une sorte de toile tissťe d'une variťtť de fils de nature parfois assez diffťrente, pouvant Ítre aussi bien syntaxiques que pragmatiques. Ainsi, bien que tous les ťlťments de la structure rťfťrentielle concourent au mÍme objectif (fournir un schťma hic et nunc ŗ l'interprťtation), leur analyse n'implique pas forcťment les mÍmes moyens. Cette diffťrence d'analyse permet de traiter certains phťnomŤnes rťfťrentiels de faÁon locale, comme s'il s'agissait de phťnomŤnes indťpendants (cf. par exemple Altmann, 1989; Garnham & Oakhill, 1987; Halliday & Hasan, 1976; Levinson, 1987; Tanenhaus, Boland , Garnsey, & Carlson, 1989) . Mais en dťpit de l'intťrÍt des travaux concernťs, de tels dťcoupages thťmatiques ne permettent pas de rattacher les ťlťments de la structure rťfťrentielle ťtudiťs ŗ ce ŗ quoi ils servent.
L'analyse rťfťrentielle doit notamment permettre de dťterminer qui fait quoi parmi les diffťrents agents, d'orienter l'action, les personnes et les objets dans le temps et dans l'espace, de relier les entitťs co-rťfťrencťes, de signaler ce qui est important, etc.., autant d'ťlťments qui contribuent ŗ la cohťsion du discours, maintiennent sa continuitť et... se co-dťfinissent. Le langage emploie une panoplie considťrable d'indices rťfťrentiels : structure argumentale des verbes (un verbe prend un certain nombre de places dťfinies qui renvoient ŗ des entitťs telles que : agent, bťnťficiaire, instrument, etc..), structure pronominale (sujet-objet directs, dťmonstratifs, relatifs, adverbiaux, etc..), co-rťfťrents, co-spťcificateurs, formes dťfinies, (ex. articles dťfinis), structures clivťes, formes dťictiques (ex. je-tu , ici-labas , prŤs-loin ), etc.. Tous ces indices rťfťrentiels constituent des traces des intentions du locuteur, permettent d'orienter et de structurer l'interprťtation en termes d' ici et maintenant . Mais leur analyse au cours de l'interprťtation comporte une structure hiťrarchique (c'est-ŗ-dire doit respecter un ordre, certaines analyses prť-conditionnant d'autres), de sorte que ce qui peut paraÓtre hťtťrogŤne en juxtaposition ne fait qu'exprimer une certaine logique de traitement dans la dimension temporelle.
L'analyse des troubles aphasiques dont l'origine semble souvent se situer au niveau de certaines phases de l'analyse rťfťrentielle (affectant en cascade les opťrations qui suivent) constitue l'un des moyens les plus propices pour ťtudier la structuration rťfťrentielle de l'interprťtation. Certains travaux neurolinguistiques laissent penser que la sťquence des principales analyses rťfťrentielles reflŤte le sens gťnťral dans lequel se dťroule l'interprťtation [37] . Les premiŤres opťrations semblent fournir la base d'une interprťtation trŤs grossiŤre (par exemple, le thŤme gťnťral) qui peut nťanmoins Ítre suffisante dans certains contextes du point de vue comportemental. Ainsi, la dťtermination de la structure argumentale du verbe et l'attribution globale des rŰles thťmatiques (sujet-action-objet) paraissent faire partie des principales opťrations rťfťrentielles effectuťes dans la premiŤre phase du traitement. Ces opťrations semblent Ítre assez īrťsistantes ŗ la lťsion' et sont souvent ťpargnťes chez les aphasiques (cf. Canseco-Gonzalez, Shapiro, Zurif, & Baker, 1990; Canseco-Gonzalez, Shapiro, Zurif, & Baker, 1991; Shapiro & Levine, 1990) ce qui explique la bonne performance des patients dans les expťriences qui reposent sur l'attribution globale des rŰles thťmatiques (on demande aux sujets de mimer l'action dťcrite par la phrase-cible ou d'apparier phrases et images), c'est-ŗ-dire les expťriences qui n'examinent que les ťlťments les plus grossiers de l'interprťtation. Toutefois, dŤs que l'on examine l'attribution des rŰles thťmatiques d'une faÁon plus complŤte, tenant compte du traitement des formes dťfinies, des co-rťfťrents pronominaux et des co-spťcificateurs (ex. : Pierre est tombť en essayant d'escalader le mur de l'ťcole. L' enfant s'est cassť la jambe.) [38] Ė ce qui dťpasse le contexte d'une phrase simpleŮ on constate des erreurs massives chez certains patients, des erreurs ponctuelles chez d'autres.
Avec Michel de Fornel nous avons prťsentť une premiŤre ťbauche de la thťorie de structuration rťfťrentielle (de Fornel & Rosenthal, 1987) . Dans cette premiŤre formulation, nous avons conceptualisť la structure rťfťrentielle en termes d'espace- espace de travail , espace rťfťrentiel - en nous focalisant tout d'abord sur le repťrage et la dťlimitation des savoirs nťcessaires ŗ l'interprťtation [39] .
Nous sommes partis du constat que la dťtermination de l'identitť lexicale des mots d'une phrase constitue le prťalable nťcessaire pour repťrer et dťlimiter les domaines du savoir concernťs [40] . En effet, pour s'engager dans le processus d'interprťtation d'une phrase il faut dťlimiter les domaines de savoir qui la concernent, ceux notamment qui sont associťs aux mots pleins (substantifs, verbes, etc..) de cette phrase. Cela prťsuppose un lien dťterminable entre mots de la langue (unitťs morphologiques) et domaines de savoir auxquels ils sont frťquemment associťs. La prise en compte de la cooccurrence de ces mots permet de dťlimiter les seuls domaines de savoirs concernťs , ce qui ťquivaut, implicitement, ŗ la dťsambiguation des ťventuelles polysťmies. Par exemple, si le mot polysťmique īvol' est entourť de mots comme ębattements d'ailes ' , īvent' , etc. , autrement dit de mots liťs au dťplacement dans l'air et non ŗ un acte dťlictueux consistant ŗ dťrober des biens, alors le savoir liť ŗ ce dernier domaine (qui n'est pas associť aux autres mots de la phrase) peut Ítre ťliminť du jeu, ce qui lŤve de ce fait l'ambiguÔtť de īvol' . Il est ŗ noter que de telles polysťmies peuvent Ítre rťsolues au moyen d'un traitement purement formel , que ce soit en exploitant certaines rŤgles morpho-syntaxiques du franÁais ou en se fondant sur le fait que, statistiquement, l' ensemble des mots qui co-occurrent dans un contexte donnť ne cooccurrent pas dans un autre contexte. Ce procťdť de rťsolution des polysťmies a d'ailleurs ťtť implťmentť sur ordinateur (cf. Andreewsky et al., 1987) . Nous avons par ailleurs explorť une dťmarche analogue pour la rťsolution automatique des anaphores (Rosenthal & de Fornel, 1985) .
La dťlimitation des domaines de savoirs concernťs amorce de fait une prť-comprťhension . Cette prť-comprťhension peut dans certaines conditions limites n'Ítre suivie d'aucun autre traitement; elle peut d'ailleurs Ítre mise en ťvidence sur le plan comportemental. On peut notamment montrer l'effet de ces conditions limites chez certains sujets aphasiques (capables, par exemple, d'apparier des mots īsťmantiquement proches' qu'ils ne peuvent ni lire ni ęcomprendre' ) ou chez des sujets normaux au moyen d'expťriences de prťsentation subliminale de mots (cf. Marcel, 1983) .
Nous avons appelť l'ensemble des domaines de savoirs ainsi dťlimitťs ī l'espace de travail ' des processus d'interprťtation d'un ťnoncť. C'est dans cet espace qu'il s'agissait de dťfinir les interactions entre la structure linguistique de l'ťnoncť et les diffťrents savoirs liťs ŗ cet ťnoncť. Cet espace de travail ne pouvait pas cependant Ítre seulement fonction des domaines de connaissances liťs ŗ l'ťnoncť traitť et du contexte pragmatique de l'acte d'ťnonciation. …tant donnťe la continuitť, sauf exception, du fonctionnement cognitif il ne peut pas y avoir de rupture entre les espaces de travail successifs, les espaces immťdiatement prťcťdents fournissant la base aux anticipations thťmatiques de l'instant t .
La dťlimitation de l'espace de travail ne permet pas pour autant de dťterminer la nature des ťtapes opťratoires qui doivent Ítre franchies pour parvenir ŗ l'interprťtation. Tout d'abord, se pose un double problŤme : comment mettre en ķuvre les seules interactions utiles, alors que le nombre d'interactions possibles entre les diffťrents savoirs potentiellement concernťs peut Ítre astronomique et que le sens de l'ťnoncť reste ŗ dťterminer? Cette question exprime de fait le problŤme de 1'interactivitť : comment sortir du cercle vicieux d'un trŤs grand nombre d'interactions, en principe toutes possibles, sans recourir ŗ une espŤce de īpilotage par le haut ' Ė ce qui ne fait que dťplacer le problŤme.
Au premier abord, il semble impossible d'ťviter l'explosion combinatoire des interactions entre les divers savoirs potentiellement concernťs (et dont le nombre est quasiment infini). Ce problŤme est ťvoquť par Fodor (1983) et lui sert d'argument principal pour soutenir la thŤse de l'impossibilitť d'une science cognitive. Toutes nos connaissances, dit Fodor, peuvent potentiellement s'articuler entre elles (c'est le principe de l'interconnectivitť infinie des connaissances) et toute interprťtation, bien qu'apparemment liťe ŗ un domaine limitť, peut faire appel ŗ n'importe quel domaine de connaissances, mÍme ŗ des domaines qui semblent a priori sans aucun rapport avec les ťnoncťs traitťs (c'est le principe de l'isotropie de l'interprťtation).
Le problŤme se pose en fait ŗ deux niveaux. D'une part, il s'agit de savoir comment ne choisir que les domaines du savoir concernťs? La notion d'espace de travail peut constituer une rťponse ŗ cette question. Mais, d'autre part, qu'est-ce qui fait que l'interprťtation ne bascule pas dans l'isotropie?
Trois raisons principales expliquent pourquoi l'isotropie n'est pas inťvitable (voir aussi Rosenthal, 1988) . PremiŤrement, la continuitť du fonctionnement du systŤme : la structure de l'espace de travail, ŗ l'instant t-1 conditionne en partie celle ŗ l'instant t .
DeuxiŤmement, la propension au conservatisme qui consiste ŗ privilťgier les relations habituelles (ou, si l'on veut, les plus frťquentes ). Cette disposition est illustrťe par des īerreurs' de comprťhension qui rťvŤlent une ęcontamination' par le savoir de ce qui se passe habituellement. Sans cette derniŤre on ne peut interprťter le fait que, par exemple, la phrase ęLe ballon a frappť la fenÍtre' est trŤs souvent comprise comme ęLe ballon a brisť la vitre' ? On trouvera dans l'ouvrage de Lakoff (1987) plusieurs exemples de mťtonymie qui s'expliquent par ce mÍme conservatisme cognitif.
Enfin, troisiŤmement, l'exploitation de certains aspects formels des ťnoncťs (autres que ceux qui permettent de dťlimiter l'espace de travail) joue un rŰle considťrable dans l'ťmergence de l'interprťtation.
Par ęaspects formels' il faut entendre principalement les indices liťs ŗ la structure rťfťrentielle et thťmatique du discours. Les interactions visant ŗ structurer l'espace de travail sont ainsi liťes ŗ la fois ŗ la continuitť du fonctionnement cognitif, aux anticipations thťmatiques, ŗ la tendance ŗ privilťgier les associations habituelles entre diffťrents types de savoir et ŗ l'exploitation des indices formels. Ces indices permettent de privilťgier certaines interactions et d'orienter certaines relations pour structurer l'espace de travail et constituer un espace rťfťrentiel . Le concept d'espace rťfťrentiel s'attache ŗ un autre problŤme inhťrent aux t‚ches de comprťhension du langage, celui du traitement de la rťfťrence interne ŗ un espace de travail. Sans ce concept, on ne peut guŤre expliquer la production et l'interprťtation des termes rťfťrentiels dans le discours (en ce qui concerne, par exemple, la rťfťrence anaphorique), en particulier le problŤme de l'identification rťfťrentielle qui sera examinťe plus bas. Ce concept est ťgalement indispensable pour expliquer la structuration thťmatique du discours, le choix lexical et les diffťrences dans l'interprťtation des alternatives verbales formellement ťquivalentes. C'est aussi ŗ travers cette notion que l'on peut prendre en compte la richesse du langage, alors que classiquement les thťories psycholinguistiques de la comprťhension du langage tendaient ŗ considťrer que les diffťrentes paraphrases d'un ťnoncť ont un statut cognitif identique.
Dans l'exemple suivant :
īDimanche dernier, nous avons ťtť au cinťma . Quelle catastrophe! L'ouvreuse nous a mal placť, la salle ťtait mal climatisťe et le film ťtait trŤs long.'
les descriptions dťfinies- l'ouvreuse, la salle et le film- rťfťrent ŗ des entitťs non-mentionnťes antťrieurement dans le discours. Ce fait n'est guŤre explicable sans la notion d'espace rťfťrentiel. La structure de ce dernier mobilise en partie notre savoir sur l'art et la maniŤre d'aller au cinťma mais elle comporte ťgalement des ťlťments nouveaux [41] . On notera que l'espace rťfťrentiel a peu de rapports avec les concepts classiques de īscripts' ou de ęframes' qui avaient pour but, du moins en partie, de traiter ces mÍmes phťnomŤnes (Minsky, 1975; Schank, 1975) . En effet, l'espace rťfťrentiel correspond ŗ une structure implicite qui n'est ni prťexistante, ni mÍme distincte de l'espace de travail.
Le concept d'espace rťfťrentiel permet aussi d'engager une rťflexion sur l'occurrence de certaines īerreurs' comme, par exemple, certains lapsus ou aveux involontaires. Considťrons l'exemple suivant, extrait d'un roman policier :
- Oý est
Midge?
- Je connais personne qui s'appelle Midge.
(...)
- Nous pensons que Big Anthony et Midge sont
ensemble.
- Impossible.
- Pourquoi?
- D'abord, qui c'est, Midge? Si je la connais pas,
comment Big pourrait-il la connaÓtre? Et en plus, Big a
une petite amie et elle serait furieuse s'il fricotait avec
une autre sauterelle. Pas vrai, Toy? Elle serait pas
furieuse?
- Si, dit Toy, elle serait furieuse.
Les deux
inspecteurs observaient Nesbitt avec insistance. Ils lui
avaient donnť une bonne longueur de corde pour se pendre;
maintenant, ils se contentaient de le regarder en silence,
attendant qu'il se rende compte que la trappe s'ťtait ouverte,
que le nķud roulant s'ťtait resserrť autour de son cou et que
ses pieds pendaient dans le vide sous la
potence.
- Qu'est-ce qu'il y a? demanda Nesbitt. Qu'est-ce que
vous regardez?
(...)
- Comment sais-tu que c'est une fille? demanda
Carella.
- Qui Áa? De qui vous parlez maintenant? dit
Nesbitt.
-De la mÍme
personne. Midge. Comment sais-tu que c'est une
fille?
- Vous avez dit que c'ťtait une fille. Vous avez dit que vous
cherchiez une fille qui s'appelait Midge.
- Nous avons dit que nous essayons de retrouver une personne
du nom de Midge. Nous n'avons pas dit que c'ťtait une
fille.
(E. Mc Bain, Branle-bas au 87, ťditions Gallimard,
1974)
Il s'agit, bien entendu, d'un aveu involontaire. En anglais, Midge est soit un sobriquet qui dťsigne un homme soit un diminutif qui rťfŤre ŗ une femme. Nesbitt tombe dans le piŤge, aussi vieux que le monde, consistant ŗ faire parler le suspect de ce dont il nie avoir connaissance. S'il disait la vťritť, Nesbitt ne devrait pas connaÓtre le rťfťrent de Midge et ne devrait donc pas y associer un domaine de connaissance spťcifique. En identifiant Midge ŗ une femme, il montre qu'il ment et que ce domaine ęfait partie' de son espace rťfťrentiel. Cet espace devient alors un vťritable piŤge, car il est extrÍmement difficile d'ťviter, par un effort conscient, une mention (dans cet exemple, en utilisant le fťminin) īrťvťlatrice' de ses connaissances concernant les entitťs et leurs relations dans cet espace.
Regardons de plus prŤs ce dialogue entre les deux policiers et leur suspect. Le nom de Midge est introduit ŗ deux reprises (par les policiers) dans la conversation. Une premiŤre fois, dans une question partielle (oý est Midge?) qui permet d'īintroduire' une entitť nouvelle dans l'espace de travail de leur interlocuteur, une seconde fois, sous la forme d'une spťculation (nous pensons que Big Anthony et Midge sont ensemble) permettant d'introduire certains ťlťments qui vont jouer un rŰle central dans la structuration de son espace rťfťrentiel. Dans cette deuxiŤme phrase, le syntagme nominal 'Big Anthony et Midge' est en position de thŤme (se rťfťrant ŗ des entitťs dťjŗ introduites), le prťdicat 'sont ensemble' est en position de comment (entitť ou relation nouvelle). Le rŰle de ce dernier est particuliŤrement important dans la structuration de l'espace rťfťrentiel. En effet, la suite de la conversation (et surtout la rťaction du suspect) montre que ce comment et ce thŤme , apparemment tout ŗ fait bťnins, ont entraÓnť un remarquable travail cognitif chez Nesbitt (en structurant son espace de travail), en crťant un espace rťfťrentiel dont certains ťlťments clťs (par exemple le fait que Midge est une femme et qu'elle pourrait avoir une relation amoureuse avec Big Anthony), non mentionnťs par les interlocuteurs, constituent le piŤge dont il ťtait question plus haut . Pour expliquer cet exemple , on ne peut s'en tenir ŗ une simple reprťsentation du contenu de cette phrase (d'ailleurs, qu'est-ce que ce contenu?) ou, purement et simplement, ŗ l'ťvocation d'un domaine de savoir prťexistant. L'aveu involontaire de Nesbitt oblige ŗ envisager l'existence d'une structure rťfťrentielle ad hoc , certes composťe en partie d'un savoir prťexistant (le fait qu'il sache que Big Anthony ait une petite amie et, en particulier, qu'il connaisse Midge) mais aussi d'ťlťments nouveaux (notamment ceux liťs ŗ la possibilitť que Big Anthony et Midge puissent avoir une relation amoureuse) qui interviennent d'ailleurs dans son ęaveu' .
L'importance de ces ťlťments nouveaux apparaÓt aussi clairement si l'on considŤre les exemples de mťtonymie ŗ la Nunberg (1978) , comme le suivant :
īL'omelette au jambon est parti sans payer'
oý l'on cherchera en vain une case adťquate pour īomelette au jambon' dans une structure prťexistante comme le script de restaurant de Schank. La possibilitť de multiplier ŗ l'infini les divers usages mťtonymiques rend de tels scripts inopťrants pour traiter ce genre d'expressions. Des tels usages illustrent d'ailleurs le potentiel crťatif et novateur du langage qu'interdisent les thťories psycholinguistiques qui prennent les significations lexicales pour des unitťs de sens fixes rťsidant dans un lexique mental et servant de base (au moyen d'une combinatoire) ŗ l'interprťtation du langage [42] .
L'utilisation des connaissances du sujet et l'ťmergence de motifs thťmatiques nouveaux dans la structuration rťfťrentielle de l'interprťtation ont ťtť ťtudiťes dans le cadre d'une recherche conduite ŗ l'Universitť de Padoue avec des patients aphasiques, des patients atteints de lťsions traumatiques du cerveau (sans trouble du langage), des sujets ‚gťs et des ťtudiants (Rosenthal & Bisiacchi, 1997) . Dans cette recherche nous avons eu recours au paradigme expťrimental de mise en ťvidence dans l'interprťtation des phrases des īelaborative effects' , paradigme initialement utilisť par Bransford et ses collŤgues (Bransford & Franks, 1971; Johnson, Bransford, & Solomon, 1973) . Dans la version classique de ce type d'expťrience on lit aux sujets (ou on leur fait lire) des phrases dites ŗ implication pragmatique, par exemple : le ballon frappe la fenÍtre , et on procŤde ŗ une ťpreuve de reconnaissance en leur fournissant parmi les choix alternatifs l'implication pragmatique de la phrase test: le ballon casse la fenÍtre . Ces travaux ont montrť que les sujets font un grand nombre d'erreurs de reconnaissance en choisissant les implications pragmatiques des phrases test (Johnson et al., 1973) . Il faut souligner que ce sont nos connaissances des matťriaux (verre, ballon) et des situations typiques qui se produisent lorsqu'un ballon frappe une fenÍtre qui permettent de thťmatiser le motif nouveau (casser la vitre). Ce ne sont en aucun cas les propriťtťs sťmantiques du verbe frapper qui induisent une telle interprťtation; pour s'en apercevoir il suffit d'essayer la phrase : le ballon frappe le mur que nul n'interprťtera comme indiquant qu'un ballon a cassť un mur. Pour ma part, j'ai montrť dans une expťrience antťrieure que ce phťnomŤne de thťmatisation au moyen d'intťgration tacite d'implications pragmatiques n'est pas liť au fait que l'on crťe des īpiŤges' parmi les choix proposťs en reconnaissance : les sujets font les mÍmes īerreurs pragmatiques' dans une ťpreuve de rappel non indicť (Rosenthal, 1981) .
Dans la recherche menťe ŗ Padoue la principale expťrience ne reposait pas sur une ťpreuve de mťmoire mais sur une ťpreuve d'appariement de phrases et d'images. Ce choix rťpondait pour une part ŗ des impťratifs pratiques de l'expťrimentation avec des sujets aphasiques, mais il rťpondait ťgalement ŗ la critique que l'on pouvait adresser aux travaux sur les īelaborative effects' au moyen d'ťpreuves de mťmoire, ŗ savoir que rien ne permet de savoir si ces effets d'intťgration d'implications pragmatiques se produisent au cours de l'interprťtation ou s'ils correspondent ŗ des transformations qui interviennent postťrieurement en mťmoire. On pouvait en effet considťrer qu'une ťpreuve d'appariement phrase- image sonde d'une faÁon plus directe l'utilisation des connaissances du sujet et l'ťmergence de motifs thťmatiques nouveaux induits par lesdites īimplications pragmatiques' .
Le tableau ci-dessous prťsente le matťriel expťrimental utilisť dans toutes les expťriences de cette ťtude.
TABLEAU 1 : Les phrases (TI) ont des implications pragmatiques et les phrases (C) correspondent ŗ la condition de contrŰle
TI C
1.
La
bambina compera un
gelato
. 1.
Il
passegero monta
sull'autobus
.
La
petite fille achŤte une glace. Le
passager monte dans le bus.
2.
La
volpe afferra la
gallina
. 2.
Il
professore scrive sulla
lavagna
.
Le renard
attrape la
poule
.
Le
professeur ťcrit sur le tableau.
3.
La
palla arriva contro la
finestra
. 3.
Il
poliziotto ferma
l'automobile
.
Le ballon
frappe la
fenÍtre
.
Le
policier arrÍte la voiture.
4.
L'uomo
prende una
sigaretta
. 4.
L'
uomo
lava
l'automobile.
L'homme
prend une
cigarette
.
L'homme
lave la voiture.
5.
Il
cacciatore spara al
cinghiale
. 5.
La
ragazza si alza dal
letto
.
Le
chasseur tire sur le
sanglier
.
La
fille se lŤve du lit.
6.
Il
campione di karatŤ colpisce il
mattone
. 6. Lo
sciatore
discende da una
pista
.
Le
champion de karatť frappe la
brique
.
Le
skieur descend la piste.
7.
Il
violinista afferra il suo
strumento
. 7.
Il
medico visita il
malato
.
Le
violoniste saisit son
instrument
.
Le
mťdecin examine le patient.
8.
L'uomo
fa cadere il
vaso
. 8. Il
calzolaio
ripara
la scarpa.
L'homme
fait tomber le
vase
.
Le
cordonnier rťpare la chaussure.
9.
La
donna scivola sulle
scale
. 9. Il
gatto
beve
il
latte.
La femme
glisse dans l'escalier. Le chat boit
du lait.
10.
La
nave si scaglia contro le
rocce
. 10.
L'uomo
va in
bicicletta
.
Le bateau
fonce sur les
rochers
.
L'homme monte sur la bicyclette.
A chaque phrase correspondaient trois images en couleur. Pour les phrases TI, qui ont des implications pragmatiques, le choix consistait en une image reprťsentant l'ťvťnement dťcrit ( image correcte ), une image reprťsentant l'implication pragmatique probable de cet ťvťnement ( image TI ) et une image mettant en scŤne les mÍmes acteurs ou objets mais dans une action diffťrente ( image distracteur ). Pour les phrases C (contrŰle) le choix consistait en une image correcte et deux images distracteurs .
Quatre groupes de sujets ont participť ŗ l'ťpreuve d'appariement phrases- images.
(a) 14 aphasiques (‚ge moyen 68,4) dont 7 aphasiques de Broca, 1 aphasique de Conduction, 4 aphasiques de Wernicke et 2 aphasiques anomiques.
(b) 14 patients (‚ge moyen 28,4) qui ont ťtť victimes d'une lťsion traumatique du cerveau (il s'agissait pour la plupart d'un accident de circulation) dont 5 lťsions bilatťrales, 5 lťsions de l'hťmisphŤre droit et 4 lťsions de l'hťmisphŤre gauche. Aucun de ces patients ne prťsentait de troubles du langage ou de la reconnaissance d'images.
(c) 19 sujets ‚gťs (‚ge moyen 70,2) ne prťsentant aucun signe clinique ou neuropsychologique de dťmence.
(d) 10 ťtudiants de psychologie ŗ l'Universitť de Padoue (‚ge moyen 22).
Le tableau ci-dessous rťsume les rťsultats (la condition TI est marquťe en italique gras).
|
|
Tacit Implication Sentences |
Control Sentences |
|||
|
Picture Choice |
Correct |
TI |
Distractor |
Correct |
Distractor |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Aphasics (14) |
41.4 |
54.3 |
4.3 |
95.7 |
4.3 |
|
Elderly (19) |
72.1 |
25.3 |
2.6 |
98.4 |
1.6 |
|
Head injury (14) |
82.2 |
15.7 |
2.1 |
96.4 |
3.6 |
|
Students (10) |
91 |
9 |
0 |
100 |
0 |
|
|
|
|
|
|
|
Plusieurs ťlťments marquants apparaissent ŗ la lecture de ces rťsultats. Tout d'abord on constate que tous les sujets font des erreurs de type TI en thťmatisant une implication pragmatique probable de la phrase test. Il ne peut pas s'agir lŗ de rťponses au hasard puisque les rťsultats montrent que les erreurs consistant ŗ choisir un distracteur ont ťtť marginales. On note une sorte de gradation dans la thťmatisation de l'implication pragmatique, les aphasiques le font une fois sur deux, les sujets ‚gťs une fois sur quatre, les patients cťrťbrolťsťs (jeunes et sans troubles du langage) une fois sur six, alors que les ťtudiants, une fois sur dix.
Le fait que mÍme de jeunes ťtudiants fassent ce type d'īerreurs' est frappant. Lorsqu'il s'agissait d'expťriences de rappel ou de reconnaissance on pouvait toujours contester l'idťe que ces ęelaborative effects' interviennent lors de l'interprťtation des phrases et que les ťpreuves de mťmoire favorisent la confusion entre l'interprťtation initiale et la rťflexion ultťrieure, voire qu'elles induisent de tels effets par l'utilisation des items de reconnaissance faciles ŗ confondre avec la cible. Or, dans le cas prťsent, le sujet avait sous les yeux la phrase test et les images ŗ apparier et il disposait de tout son temps pour faire son choix. De plus, la consigne insistait sur la dťsignation de l'image reprťsentant exactement ce que dit la phrase. Ainsi, le fait que mÍme les ťtudiants thťmatisent de cette faÁon les implications pragmatiques probables de phrases indique que ce rťsultat ne peut pas Ítre expliquť par la ędťfaillancedu systŤme' due ŗ la lťsion du cerveau ou au vieillissement. Ce rťsultat ne peut pas davantage s'expliquer, en ce qui concerne les aphasiques, par la difficultť syntaxique des phrases tests dans la mesure oý il s'agit dans tous les cas de phrases dťclaratives simples dont la structure est la mÍme dans les conditions TI et C.
Ces rťsultats illustrent ainsi la faÁon dont les sujets thťmatisent les motifs nouveaux (ici consťquences probables d'un ťvťnement) au cours de l'interprťtation en se fondant sur leur savoir expťrientiel. Cette thťmatisation est mÍme susceptible de prťvaloir sur les indices rťfťrentiels : l'existence des taux significatifs des rťponses TI dans tous les groupes de sujets indique une tendance gťnťrale ŗ se fier ŗ l'expťrience (ou au savoir expťrientiel) et d'interprťter les ťnoncťs en conformitť avec des anticipations expťrientielles, le cas ťchťant au dťtriment d'indices rťfťrentiels ici et maintenant . Cette tendance, comme le montre le Tableau 2, croÓt avec l'‚ge : les choix TI semblent Ítre plus en rapport direct avec l'‚ge du sujet qu'avec le fait d'avoir ťtť victime d'une lťsion du cerveau. Les aphasiques font certes plus de choix TI que les sujets non-aphasiques d'‚ge comparable. Dans le cas prťsent, cela ne semble que confirmer le caractŤre rťfťrentiel des troubles aphasiques ou, du moins, indiquer qu'en cas de difficultť īŗ dťmÍler tous les fils rťfťrentiels' on privilťgie ce que l'on sait d'expťrience.
D'un autre cŰtť, l'observation que les rťsultats des aphasiques ne sont que quantitativement diffťrents de ceux des autres sujets renforce l'idťe que la pathologie agit dans ce cas comme un miroir grossissant qui met en ťvidence un phťnomŤne normal dont l'existence nous aurait ťchappť si nous nous ťtions contentťs du miroir usuel. L'un des principaux avantages du miroir usuel est qu'il nous renvoie une image flatteuse. Il nous fait oublier que l'interprťtation des ťnoncťs n'agit pas en fonction d'un procťdť mťcanique dont le rťsultat est prťdťterminť. Comme le montrent notamment ces rťsultats, l'interprťtation est un processus faillible mÍme chez les sujets jeunes en pleine possession de leurs moyens, car elle ťmerge aux termes d'une nťgociation dont l'issue demeure incertaine. Cela n'empÍche pas d'observer les mÍmes ressorts rťfťrentiels chez diffťrents groupes de sujets, du moins tant qu'il s'agit du mÍme contexte interprťtatif. Ainsi, lorsqu'on compare les diffťrentes phrases TI on constate une trŤs forte corrťlation dans les choix TI des diffťrents groupes : ce sont, comme le montre le Tableau 3, les mÍmes phrases qui donnent lieu au plus grand nombre de rťponses TI, et inversement, les mÍmes phrases qui obtiennent le plus faible nombre de rťponses TI de la part de tous les groupes de sujets.
|
|
|
|
|
|
|
Phrases TI |
Aphasics |
Elderly |
Head Inj. |
Students |
|
|
|
|
|
|
|
|
|
|
|
|
|
1. La petite fille achŤte une glace. |
14.3 |
0 |
7.2 |
0 |
|
2. Le renard attrape la poule. |
28.6 |
10 |
14.3 |
0 |
|
3. Le ballon frappe la fenÍtre. |
78.6 |
30 |
14.3 |
0 |
|
4. L'homme prend une cigarette. |
35.7 |
10 |
7.2 |
0 |
|
5. Le chasseur tire sur le sanglier. |
14.3 |
0 |
0 |
0 |
|
6. Le champion de karatť frappe la brique. |
92.8 |
60 |
28.6 |
40 |
|
7. Le violoniste saisit son instrument. |
50 |
0 |
7.2 |
0 |
|
8. L'homme fait tomber le vase. |
42.8 |
0 |
21.4 |
0 |
|
9. La femme glisse dans l'escalier. |
92.8 |
80 |
35.7 |
30 |
|
10. Le bateau fonce sur les rochers. |
92.8 |
60 |
21.4 |
20 |
TABLEAU 3 : Pourcentages moyens des rťponses TI pour chaque Phrase TI.
Cette forte corrťlation montre l'existence des mÍmes rťgularitťs ou plutŰt des mÍmes ressorts rťfťrentiels chez tous les sujets dans le prťsent contexte interprťtatif. On aurait pu objecter ici qu'il est inutile de recourir ŗ la thťorie de la structuration rťfťrentielle pour expliquer ces similaritťs : la corrťlation entre les rťponses TI des diffťrents sujets indiquant tout simplement que les mÍmes propriťtťs sťmantiques conduisent ŗ la mÍme interprťtation des phrases.
Dans le cadre de cette mÍme ťtude, nous avons conduit deux expťriences complťmentaires avec des ťtudiants de l'Universitť de Padoue. Les mÍmes phrases TI ont ťtť utilisťes dans une ťpreuve de jugement [43] et dans une ťpreuve de reconnaissance ŗ 3 items (phrase cible, son implication pragmatique, mÍmes acteurs/objets dans une action diffťrente), l'objectif ťtant d'ťvaluer l'effet du contexte interprťtatif sur l'interprťtation des mÍmes phrases. Les rťsultats ont montrť un pattern diffťrent de rťponses TI pour chaque ťpreuve : ce ne sont jamais les mÍmes phrases qui produisent le plus (ou le moins) de rťponses TI. La figure ci-dessoux illustre ces tendances. Les Expťriences 1, 2 et 3 correspondent, dans l'ordre, aux ťpreuves : d'appariement phrase- image, de jugement et de reconnaissance.
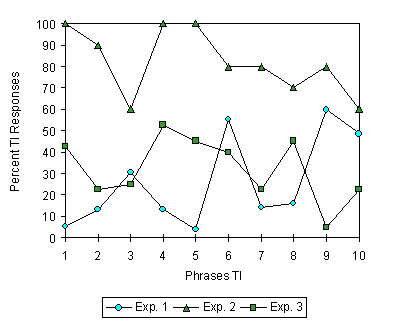
FIGURE 1. Pourcentages des rťponses TI pour les phrases TI dans les Expťriences 1, 2, et 3.
Ainsi nous avons mis en ťvidence la dťpendance de la thťmatisation des motifs nouveaux du contexte interprťtatif dans lequel se trouve le sujet. Si l'on change un tant soit peu ce contexte, de nouvelles anticipations thťmatiques, le cas ťchťant contradictoires avec les prťcťdents, apparaissent et entraÓnent une interprťtation nouvelle. On conviendra certes que les contextes explorťs dans cette ťtude sont tout ŗ fait artificiels et fort ťloignťs de la cohťrence naturelle des situations de la vie dans lesquels nous sommes normalement immergťs, avec leurs rťseaux d'anticipations thťmatiques, leur environnement perceptif, ainsi que les ajustements intersubjectifs et les tactiques de communication qui jouent tous un rŰle dans l'interprťtation. On s'imagine difficilement quelqu'un surgir dans mon bureau pour annoncer que Jacques a glissť dans l'escalier dans le seul but de m'informer de la survenue de cet ťvťnement. Cela pourrait se produire si le locuteur voulait m'expliquer pourquoi Jacques a ťtť hospitalisť ou pour confirmer ce que nous disions tous, ŗ savoir que le produit lustrant utilisť dans notre b‚timent rend l'escalier dangereux pour les savants vieillissants, dangereux car glissant. Et l'on peut imaginer d'autres contextes dans lesquels une telle phrase (Jacques a glissť dans l'escalier) aurait rťellement un sens. On notera ťgalement que l'action thťmatisťe variera selon ces contextes, se rattachant selon le cas ŗ une chute, au fait de renverser des produits dangereux, ŗ une glissade, etc. Or, le fait que mÍme des changements de contexte aussi microscopiques et insignifiants que ceux de notre ťtude entraÓnent une thťmatisation diffťrente montre le caractŤre sťmantiquement sous-dťterminť des ťnoncťs et le rŰle de l' entourage sensible (perceptif, social, culturel, biologique,..) [44] dans la structuration rťfťrentielle.
![]()
NOTES
[32] Ces patients ťtaient nťanmoins traditionnellement dťcrits comme capables d'une assez bonne comprťhension.
[33] Le sujet devait apparier une phrase ŗ des images (prťsentťes en choix multiple) ou mimer l'ťvťnement dťcrit par la phrase avec un ensemble de poupťes et jouets.
[34] Par exemple : as , vis , est , bus , rations , portions .
[35] J'insiste sur le caractŤre interne de ces relations pour bien diffťrencier le concept de structure rťfťrentielle de celui classique de la rťfťrence qui concerne le rapport entre objets, ťvťnements et phťnomŤnes d'un cŰtť et ťnoncťs linguistiques de l'autre. Le concept de la rťfťrence prťsuppose un rapport objectif entre les ťnoncťs et le monde extťrieur, celui de la structure rťfťrentielle ne fait pas une telle hypothŤse, mais pose qu'un ťnoncť comporte des traces tangibles et dťterminables de ce que le locuteur voulait dire.
[36] Ce terme est utilisť ici pour dťsigner un ensemble de rŤgles, tactiques, ruses ou dťveloppements qui semblent concourir au mÍme objectif structurel.
[37] Les processus rťfťrentiels se prÍtent aisťment ŗ l'expťrimentation car ils sont fragiles, ce sont eux qui sont atteints en premier dans l'aphasie (d'une faÁon sťlective et variťe) et au cours du vieillissement, et il est d'ailleurs facile de crťer des conditions expťrimentales dans lesquelles des sujets normaux ťprouvent quelque difficultť ŗ dťmÍler tous les fils rťfťrentiels (cf. Rosenthal & Bisiacchi, 1997) .
[38] Dans cet exemple l' enfant et Pierre sont des co-spťcificateurs du mÍme actant.
[39] Le concept d'espace rťfťrentiel s'inspirait en partie des travaux de Fauconnier (1984) .
[40] Il ne s'agit pas d'une reprťsentation encyclopťdique des connaissances gťnťrales mais d'un savoir personnel ettacite dont l'implication dans l'interprťtation du langage peut Ítre mise en ťvidence de maniŤre implicite.
[41] On notera que si des principes pragmatiques autorisent l'utilisation d'articles dťfinis pour des entitťs non mentionnťes antťrieurement dans le discours mais relevant du domaine de connaissances impliquť dans le traitement, elles ne rendent pas pour autant cette utilisation obligatoire. L'emploi d'articles dťfinis devant 'ouvreuse', 'salle' et 'film' relŤve d'un choix thťmatique et rťfťrentiel qui a donc nťcessairement des consťquences sur la structure de l'espace rťfťrentiel.
[42] Johnson-Laird (1987) a ťcrit par exemple : "Lexical meanings are the ingredients from which the sense of an utterance is made up, and its syntactic structure is the recipe by which they are combined. Listeners must put together the meanings of the words they recognize according to the grammatical relations that they perceive between them". (p. 189). Johnson-Laird reconnaÓt certes qu'il ne suffit pas de combiner les sens des mots pour obtenir le sens de la phrase, il insiste nťanmoins sur l'idťe que le sens des mots est reprťsentť dans un lexique mental et que l'accŤs aux entrťes sťmantiques ainsi reprťsentťes constitue la principale opťration de la comprťhension du langage.
[43] Dire si, oui ou non, la phrase donnťe invite fortement le sujet ŗ considťrer qu'elle implique X- X ťtant l'implication pragmatique de cette phrase.
[44] Ce concept d'entourage sensible peut Ítre rapprochť de celui d'entourage de comportement de Koffka (1935) ou de celui d' Umwelt du biologiste Jacob von UexkŁll (1965) . Voir Rosenthal et Visetti (1999) pour une discussion.